

> 本文已收录到 [AI编程一站式导航](https://ai80.net)。本文链接:[03.9 2026 年最佳 AI 编码工具完全指南]
(https://code.ai80.vip/ai-tool-guides/03.9 2026 年最佳 AI 编码工具完全指南)
> 强烈推荐:AI编程巴士网站:[稳定纯净的ClaudeCode套餐供应](https://code.ai80.vip/home);
每天 13.5 万次 GitHub 提交:Claude Code vs Codex,2026 年 AI 编程大战深度对比
写在前面
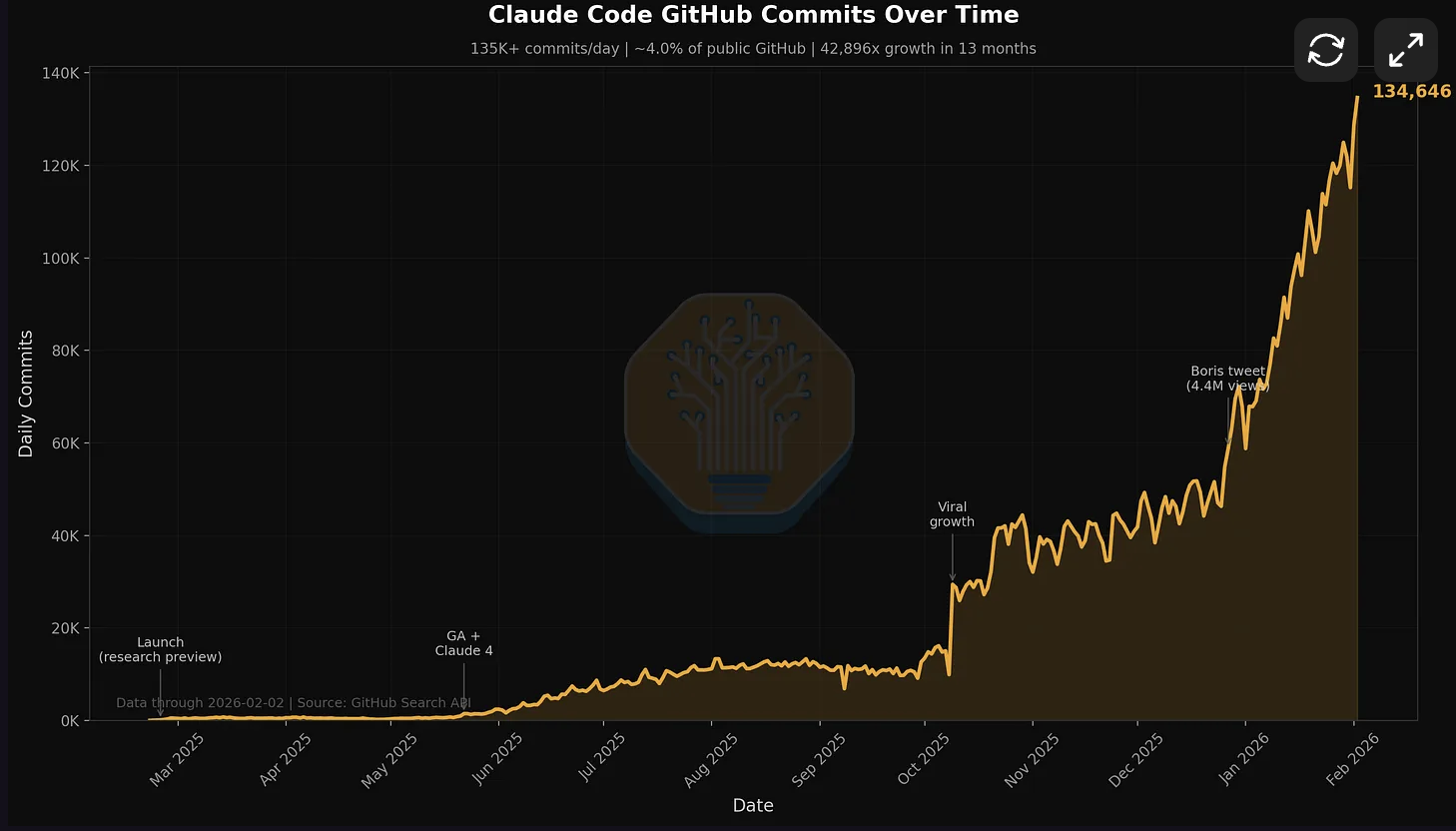
GitHub 上现在每天有大约 13.5 万次提交来自 Claude Code,占所有公开提交的 4%。
这是 SemiAnalysis 今年 2 月的测算数据。他们的预测是:按现在的增速,年底前这个比例会超过 20%。
同期,OpenAI Codex 在另一边也没闲着——CLI 用 Rust 重写、部署在 Cerebras WSE-3 上跑到 1000+ token/秒,还发布了 macOS 专属 App 管理多个 Agent 任务。
两个工具都在高速演进,定位却越来越不一样。
这篇文章基于 2026 年 2 月底的真实数据,从基准测试、Agent 架构、用量限制、失败模式四个维度做了完整对比。不是哪个更好的问题,是哪个更适合你的问题。
AI 已经在写代码了,问题是你用哪个
两张图说明背景。
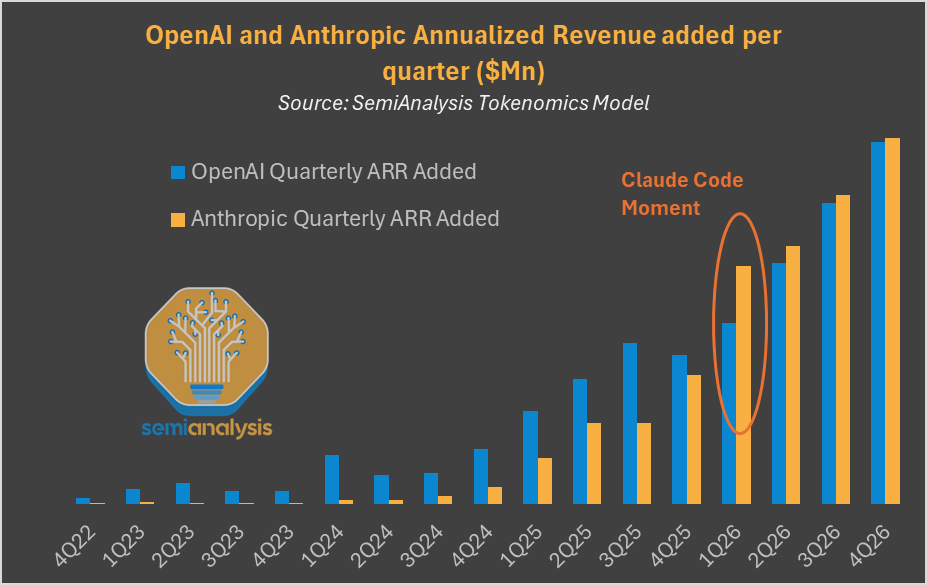
Anthropic 的 ARR 增长在 Q1 2026 出现了一个明显的拐点,研究机构把那个节点叫做"Claude Code Moment"。现在 Anthropic 估值 3800 亿美元,ARR 达到 140 亿。
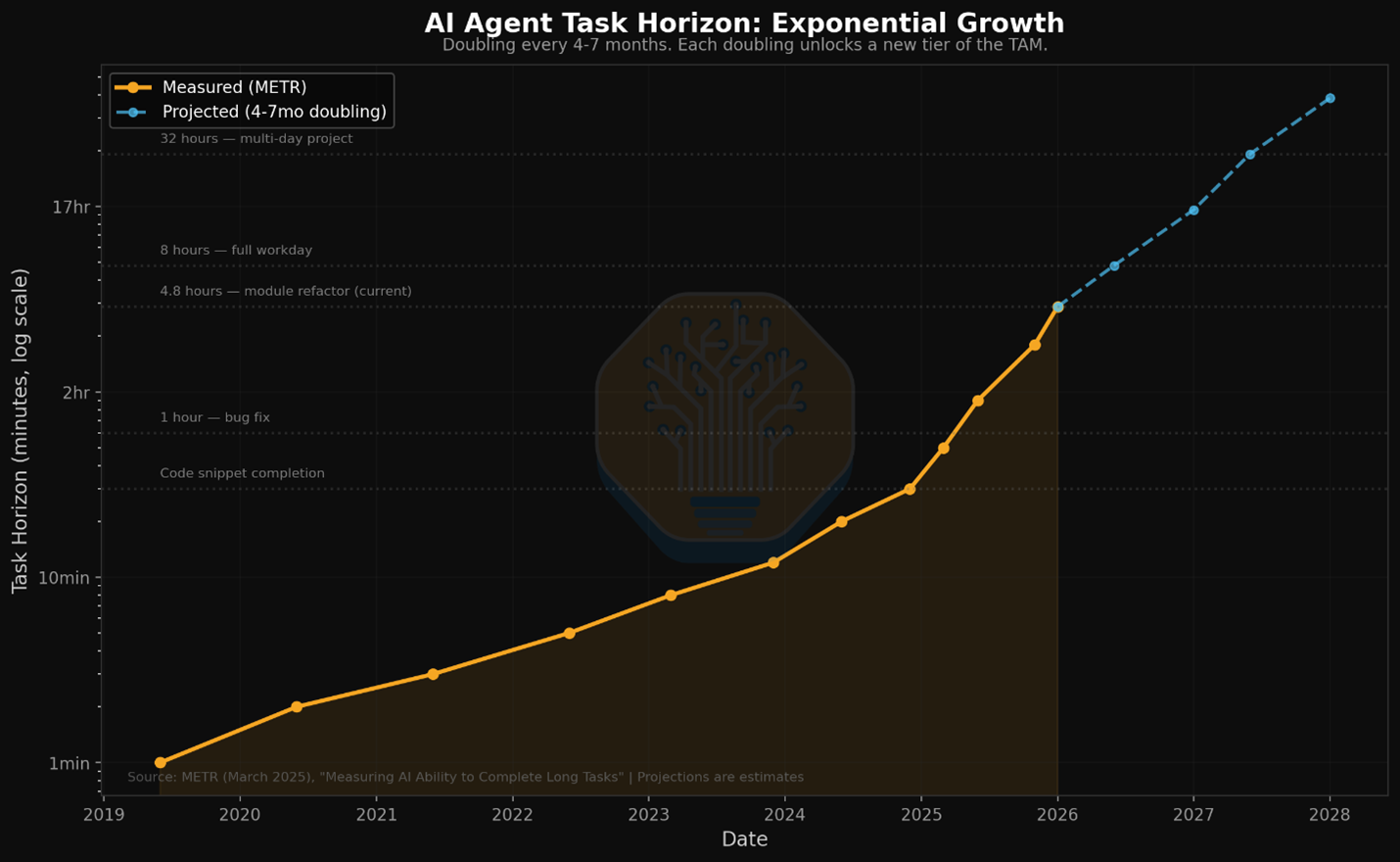
METR 的数据显示,AI Agent 能独立完成的任务时长,每 4-7 个月翻一倍——从 2019 年的 1 分钟级任务,到 2026 年的多小时复杂工程任务。
这两个数字放在一起意味着什么?
AI 写代码不再是演示,是正在发生的生产力迁移。 Claude Code 和 Codex 都站在这条增长曲线上,代表的是两种不同的 Agent 编程哲学。
基准测试:先把数字说清楚
对比之前,有一个重要的基准警告必须先说:Anthropic 报告的是 SWE-bench Verified,OpenAI 报告的是 SWE-bench Pro Public,这是两个不同的题库,分数不能直接比较。
目前唯一可以直接对比的公开榜单是 Terminal-Bench 2.0。
| 基准 | GPT-5.3-Codex | Claude Opus 4.6 | 备注 |
|---|---|---|---|
| SWE-bench Verified | — | 80.8% | 不同题库,不可直接比 |
| SWE-bench Pro | 56.8% | 59% | 同榜,Claude 略胜 |
| SWE-bench Pro(+WarpGrep) | — | 57.5% | MCP 工具加持 |
| Terminal-Bench 2.0 | 77.3% | 65.4% | 唯一苹果对苹果的比较 |
| ARC-AGI-2 | — | 68.8% | 较上代 37.6% 提升近一倍 |
结论:终端操作密集的场景 Codex 更强,复杂代码工程 Claude 更稳。 两个工具在不同维度各有领先,没有全面胜出的一方。
GitHub 生态数据(2026 年 2 月 28 日)
| 指标 | Claude Code | OpenAI Codex |
|---|---|---|
| GitHub Stars | 71,500 | 62,365 |
| 贡献者数量 | 51 | 365 |
| VS Code 安装量 | 5.2M | 4.9M |
| VS Code 评分 | 4.0/5 | 3.4/5 |
| 最新版本 | v2.1.63(2/28) | v0.106.0(2/26) |
| 开源协议 | 专有 | Apache-2.0 |
VS Code 评分的差距值得注意:4.0 vs 3.4,在用量限制更严格的情况下,Claude Code 用户满意度反而更高——说明核心体验确实在做对的事。
Agent 架构:这才是 2026 年真正的分水岭
基准数字重要,但 2 月最关键的变化不是跑分——是两个工具都开始支持多 Agent 工作流,而且实现思路完全不同。
为什么 Agent 架构比跑分更重要
AI 编程 Agent 最大的瓶颈不是智力,是上下文污染。你让一个 Agent 重构认证模块,它读了 40 个文件,等处理到最后几个文件,前面看到的代码规范它已经"忘了"。
解法是给每个子任务分配独立的上下文窗口。Codex 和 Claude 都做了这件事,但方式不同。
Codex:云端沙盒隔离
每个 Codex 任务运行在独立的云容器里。新发布的 macOS Codex App 可以按项目管理多个任务线程。
优点:隔离彻底,任务之间完全不互相干扰,安全边界清晰。 缺点:各任务之间没法通信,只能各自为政。
Claude Code:Agent Teams 协作
Claude Code 的 Agent Teams(目前是 Research Preview)是另一种思路:
$ claude "Build the payment integration"
# Claude Code 自动:
# 1. 创建带任务列表的团队
# 2. 启动 researcher agent → 探索 Stripe SDK 用法
# 3. 启动 implementer agent → 等 research 完成后再写代码
# 4. 同时启动 test-writer agent → 并行写测试
# 每个 agent 有独立上下文,互不污染
# agents 之间可以互发消息:"research 完成,找到 3 个模式"
# 依赖追踪确保 implementer 在 researcher 之前不会启动
16 个 Claude Agent 协作写出了一个 10 万行 Rust C 编译器,能编译 Linux 内核 6.9,GCC 折磨测试通过率 99%,API 成本约 2 万美元。这是 Agent Teams 能力的一个具体参照。
| 维度 | Codex(2026.02) | Claude Code(2026.02) |
|---|---|---|
| 多 Agent 模式 | 独立线程,手动切换 | 协调子 Agent,共享任务列表 |
| 隔离方式 | 云端容器 | Git worktree(本地) |
| Agent 间通信 | 无 | 直接消息 + 广播 |
| 任务依赖追踪 | 无 | 有 |
| 执行环境 | 云端(禁止联网) | 本地(完整权限) |
用量限制:定价页面没告诉你的真相
这是很多人踩过坑之后才知道的事情。
$20 档的实际对比
| 套餐 | Codex(ChatGPT) | Claude Code | 关键差异 |
|---|---|---|---|
| $8/月 | ChatGPT Go(新增) | 无 | 仅 Codex 有入门档 |
| $20/月 | Plus:30-150 条/5小时 | Pro:标准限制 | Codex 给的会话更多 |
| $100/月 | 无 | Max 5x | 仅 Claude 有中间档 |
| $200/月 | Pro:300-1500 条/5小时 | Max 20x | 两者在这档都宽松 |
$20 这档,Codex 给的会话数量比 Claude 多——这是事实,官方定价页面不会主动告诉你。
Token 消耗:一个没人讨论的关键数据
在相同任务上,Claude Code 消耗的 token 约是 Codex 的 4 倍:
| 任务 | Codex | Claude Code | 倍率 |
|---|---|---|---|
| Figma 插件开发 | 1,499,455 | 6,232,242 | 4.2x |
| 日程应用 | 72,579 | 234,772 | 3.2x |
| API 集成 | ~180,000 | ~650,000 | 3.6x |
这不代表 Claude 在浪费 token——它的高消耗对应的是更详细的推理、更完整的边界覆盖、更多的确认步骤。但在 Agent Teams 场景下,多个子 Agent 并行跑,每个都消耗独立配额,限制烧得更快。
Claude Sonnet 4.6 的价值被低估:在 SWE-bench Verified 上得分 79.6%,只比 Opus 4.6 低 1.2%,API 价格约是 Opus 的一半。多 Agent 场景下,用 Sonnet 4.6 跑工作 Agent、只用 Opus 4.6 跑主导 Agent,成本可以显著降低。
配置代价:零门槛 vs 高可塑性
Codex 在 2 月完成了一次大幅简化:CLI 用 Rust 重写,零依赖安装,开箱即用。新增功能包括:
- 按空格键语音输入(v0.105.0),说话即编程
- Diff-based forgetting:一个新颖的记忆管理方式——旧上下文不是被摘要压缩,而是通过 diff 方式只保留"变化量",对代码库结构的理解保留得更完整
- 可配置的沙盒模式:只写工作区 / 只读 / 完全访问
- JetBrains、Xcode、GitHub Actions 集成全部 GA
Claude Code 的思路是相反的方向——配置本身就是功能:
# CLAUDE.md - 项目专属指令示例
## 代码规范
- 使用 TypeScript strict 模式
- 优先函数式组件
- 不允许无注释的 any 类型
## 架构约定
- 所有 API 调用走 /lib/api
- 状态管理用 Zustand
- 未经确认不修改 package.json
## 测试要求
- TDD:先写测试,再实现
- 新代码覆盖率不低于 80%
- 使用 React Testing Library 规范
CLAUDE.md 让每个项目都有自己的 AI 行为规范。你还可以完全替换系统 Prompt,创建完全定制化的专属 Agent。代价是时间:有开发者报告"工程时间的大部分不是在写代码,而是在配置 Claude Code"。
失败模式:它们各自怎么出错
两个工具都会出错。知道它们怎么出错,比知道它们多强更重要。
Codex 的典型失败模式:
- 相同 Prompt 跑出不同结果,输出不稳定
- 觉得自己"更懂"的时候会偏离计划
- 倾向于过度防御性工程,加很多不必要的错误处理
- 不会主动适应代码库已有的风格
- 复杂多文件编辑时容易丢失上下文
"Codex 有时候会指出可能存在问题的数据库并发查询 bug,我花 30 分钟验证之后发现是幻觉。"——HN 评论
Claude Code 的典型失败模式:
- 问确认的频率太高(可以开 auto-accept 模式缓解)
- 对话 5-6 轮后上下文压缩开始影响表现
- 遇到用量限制会在任务中途停下来
- 有时会在没有明说的情况下填补信息缺口
恢复性的差异:Codex 出错通常要重新开始。Claude 出错往往可以通过对话把它拉回正轨——同样是失败,Claude 的失败更"可修复"。
各自适合什么场景
Codex 的强项
- 从零开始的项目:云端沙盒快速搭架子,Codex App 可以同时跑多个任务线程
- 长时自主运行:2 月新功能支持中途干预而不丢上下文
- 预算敏感的团队:8 的 Go 入门档
- 终端密集型工作流:Terminal-Bench 领先 12%,DevOps / 脚本 / CLI 工具场景明显更强
Claude Code 的强项
- 协调多 Agent 重构:子 Agent 有依赖追踪和消息通信,分工执行复杂任务
- 超大代码库:1M token 上下文(Beta)+ SWE-bench 80.8%,Rakuten 在 1250 万行代码库上验证了 99.9% 的准确率
- 严格按计划执行:需要 AI 老老实实按 spec 来,Claude 明显更守规矩
- 自定义自动化:Hooks 系统可以在 Agent 生命周期事件(任务完成、worktree 创建等)上触发自定义操作
最优解:两个都用
# 第一步:用 Codex 在云端沙盒快速搭原型
$ codex "按照 /lib/auth 的模式实现 JWT 用户认证"
# 云端容器里跑,15-20 分钟自主完成
# 第二步:用 Claude Agent Teams 做 review 和加固
$ claude "Review 认证实现。启动一个安全审查 Agent 和一个测试 Agent。
安全 Agent 检查 OWASP Top 10,测试 Agent 写集成测试。
两个都通过前不允许合并。"
# Claude 启动 2 个子 Agent,各自独立上下文
# 安全 Agent 找出 3 个漏洞,测试 Agent 写了 12 个测试用例
# 都完成后向主 Agent 汇报
# 第三步:快速修复用 Codex
$ codex "修复这 3 个安全问题:[粘贴 Claude 的发现]"
Claude Code 是什么?怎么开始用
Claude Code 是 Anthropic 官方的 AI 编程 Agent,不是补全工具——工作单元是"任务",不是"行"。
能力清单:
- 读写项目任意文件,理解整个代码库结构
- 在终端执行命令(构建、测试、部署脚本)
- 跨文件重构,处理复杂依赖变更
- 根据报错自主 debug 到根因
- Agent Teams 协作,多 Agent 并行执行复杂任务
官方定价(2026 年 2 月):
| 套餐 | 月费 | Claude Code 使用 |
|---|---|---|
| Claude Pro | $20 | 支持,标准限制 |
| Claude Max 5x | $100 | 5 倍 Pro 用量 |
| Claude Max 20x | $200 | 20 倍 Pro 用量 |
| Anthropic API | 按 token | Opus 4.6: 25 per 1M token |
官方订阅需要海外信用卡,对国内用户门槛不低,网络环境也得折腾。如果嫌麻烦想找个更省事的渠道,可以看看 Code80,真实订阅账号转 API,换个 endpoint 就能直接用,体验跟官方完全一样。详情到官网了解:code.ai80.vip
常见问题
Q:2026 年到底哪个更好,Claude Code 还是 Codex?
A:取决于你做什么。Terminal-Bench 2.0 Codex 领先(77.3% vs 65.4%),SWE-bench Pro Claude 略胜(59% vs 56.8%)。最大的区别在架构:Codex 是云端沙盒隔离执行,Claude Code 是协调子 Agent 并发。用量预算有限的选 Codex,做大型代码库重构或需要多 Agent 协作的选 Claude Code。
Q:Claude Code Agent Teams 是什么?
A:Research Preview 功能。可以生成多个子 Agent,每个 Agent 有独立的上下文窗口,共享任务列表并支持依赖追踪,Agent 之间可以直接发消息。防止上下文污染是核心解决的问题——每个子任务只专注自己负责的部分。
Q:用量限制哪个更宽松?
A:$20 档 Codex(ChatGPT Plus)给的会话数量多于 Claude Pro。但 Codex Agent Teams 场景下每个子 Agent 消耗独立配额,多 Agent 工作流实际消耗会倍增,要提前规划。两个平台现在都支持超额按 API 费率计费。
Q:能同时用两个吗?
A:可以,而且是越来越多高级用户的选择。Codex 负责快速原型和自主实现,Claude Code 的 Agent Teams 负责 review、安全审查和复杂重构。
Q:国内开发者怎么用上 Claude Code?
A:官方订阅需要海外信用卡,国内用户可以通过 Code80 更方便地接入,换个 API endpoint 就能在 Claude Code 里正常调用,不需要折腾海外支付和网络环境。
> 本文已收录到 [AI编程一站式导航](https://ai80.net)。本文链接:[03.9 2026 年最佳 AI 编码工具完全指南]
(https://code.ai80.vip/ai-tool-guides/03.9 2026 年最佳 AI 编码工具完全指南)
> 强烈推荐:AI编程巴士网站:[稳定纯净的ClaudeCode套餐供应](https://code.ai80.vip/home);
