

《Smart Agent-Based Modeling: On the Use of Large Language Models in Computer Simulations》
📖 摘要
本文提出“智能体智能体建模”(Smart Agent-Based Modeling, SABM)框架,把大语言模型(Large Language Models, LLMs)作为智能体建模与交互的核心引擎,用自然语言替代大量手工规则与参数设定,并通过紧急疏散、认罪协商、企业定价竞争三个案例说明:这种方法有望提升复杂社会模拟的真实性、可解释性与适应性。
一、论文基本信息
- 论文标题:Smart Agent-Based Modeling: On the Use of Large Language Models in Computer Simulations
- 作者:Zengqing Wu、Run Peng、Xu Han、Shuyuan Zheng、Yixin Zhang、Chuan Xiao;作者机构包括大阪大学(Osaka University)、密歇根大学(University of Michigan)、福坦莫大学(Fordham University)、京都大学(Kyoto University)与名古屋大学(Nagoya University)
- 出处: arXiv:2311.06330v4
- DOI/链接:arXiv:2311.06330
二、研究背景与动机
1. 问题背景
传统的复杂系统研究,大体可以分为解析建模(analytical modeling)、统计建模与基于智能体的建模(Agent-Based Modeling, ABM)。其中,ABM 的优势在于:它能够从“个体—交互—涌现”的底层机制出发,解释宏观层面的复杂现象,尤其适合社会系统、经济系统、生态系统这类高度异质、强交互、难以用单一公式刻画的对象。
但问题也恰恰出在这里:当研究对象涉及自然语言、常识判断、主观认知、情境化推理与动态适应时,传统 ABM 往往只能把这些“软因素”压缩成有限参数、启发式规则或学习算法。这样做不是不能跑,而是很容易把真正重要的复杂性“抹平”。
图1 用视觉系统进化作比喻:水母式感光对应解析建模,鹦鹉螺式低分辨率视觉对应 ABM,而人类高分辨率视觉则对应 SABM。这个比喻很妙:作者想说的不是“旧方法没用”,而是不同方法看到世界的“分辨率”不同,SABM 试图把语言、常识、情境理解也纳入模拟视野。
2. 现有方法的不足
先看复杂系统与方法选择的关系。
图2 区分了牛顿式机械系统、复杂系统与随机系统,并说明不同问题更适合解析方法、统计方法还是模拟方法。
图3 给出 ABM 的经典结构:真实世界(real world)经过抽象形成模型(model),模型中包含智能体(agent)、智能体之间的交互(agent-agent interaction)以及智能体与环境的交互(agent-environment interaction),最终通过仿真(simulation)再回到验证(validate)。
进一步地,作者指出,ABM 在以下几个方面存在结构性瓶颈:
- 复杂行为难表达:涉及语言、常识、情绪、主观判断时,规则系统往往不够用。
- 参数选择带来研究者偏差:很多结果其实高度依赖参数怎么设。
- 模型复杂度难拿捏:过简会失真,过繁又会失控,作者借用了“梅达沃区间”(Medawar zone)来描述这种平衡点。
- 异质性刻画很难:现实中的人不是几个参数能完整概括的。
- 适应性有限:真实系统在变,ABM 的规则体系却常常偏静态。
- 可解释性悖论:规则写得越多越复杂,最后越不一定真正解释了现实。
图4 强调了仿真在现实实验与理论建模之间的桥梁作用。作者的核心目标之一,就是缩小“理论/实验结果”与“模拟结果”之间的鸿沟。
图5 给了一个非常直观的例子:火灾疏散中,个体不仅要看出口远近,还会听他人喊话、理解语言建议、结合拥堵情况和自身心理状态做决定。这种“自然语言输入 + 主观判断 + 动态交互”的状态空间,对传统 ABM 来说非常吃力。
3. 本文动机
作者的判断很明确:既然 LLM 已经具备较强的语言理解、常识推理、少样本学习(few-shot learning)与角色扮演能力,那么它就不只是“写文案的工具”,而可以成为模拟系统中的“智能引擎”。SABM 的动机,本质上就是把原本硬编码在参数与规则里的“人类式判断”,尽量转移到自然语言驱动的智能体内部。
三、核心方法与创新点
1. 核心思想
SABM 的核心不是简单地“在 ABM 里接一个 LLM API”,而是重新定义建模方式:
- 用自然语言描述智能体、环境与交互;
- 用 LLM 承担一部分过去由规则、参数和手工设定承担的行为生成任务;
- 把模型拆成“引擎(engine)+ 底盘(chassis)”:
- 引擎:LLM 本身的语言、推理、常识与知识能力;
- 底盘:研究者对任务、环境、状态、流程、变量与验证方式的设计。
这个拆分非常关键。它意味着:研究者不必每次都从零“造人”,而是可以把更多精力放在问题建模与实验设计上。
图6 展示了 LLM 智能体的常见模块:行动(action)、规划(planning)、记忆(memory)、工具使用(tool use)以及人格化(personalization)。这其实为 SABM 提供了一个“组件库”式的实现视角。
图7 是全文最重要的总览图之一。作者将 SABM 和 ABM 的差异概括为几条主线:
- 自然语言建模 替代大量形式化规则;
- 常识与知识内置,不必每次都从头编码;
- 少样本学习与零样本推理 让模型更灵活;
- 个性化(personalization) 更容易实现;
- 模型解释性 更强,因为智能体能直接给出语言解释;
- 随机性与多样性 更接近现实,但也带来控制难题。
2. 创新点拆解
创新点一:从“后验拟合”走向“先验建模”
传统 ABM 很多时候是“先观察人类行为,再提炼成规则”。SABM 则尝试假设:经由人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)对齐过的 LLM,在一定程度上已经具备模仿人类常识与判断的能力,因此可以从“先验”层面直接参与建模。 这并不意味着不需要数据,而是说数据不再只是“把规则拟合出来”的唯一来源,它也可以用来做校准(calibration)和验证(validation)。
创新点二:把语言本身变成建模介质
SABM 的一个根本变化是:语言不再只是“模型外部的说明文档”,而成为模型内部的操作对象。智能体能读语言、说语言、根据语言调整行为,也因此能模拟更复杂的主观世界。
创新点三:强化异质性与主观性
现实系统中的个体差异,不只体现在年龄、速度、偏好这些数值属性上,更体现在经验、情绪、风险认知、道德判断、身份定位等难量化的层面。SABM 通过 persona(角色设定)与自然语言提示,使这些细微差异更容易被纳入模型。
图8 把 SABM 的适用范围系统化地展开了:从智能体异质性、时间结构、空间结构,到直接交互、间接交互与环境变化,几乎都能被统一进“自然语言驱动”的框架。这张图的价值,在于它不是只讲“能不能做”,而是在尝试给 SABM 建立一套应用地图。
3. 技术细节与实现流程
作者没有把 SABM 说得很玄,而是认真给出了一套可执行的方法论。
图9 表明 SABM 实现通常包括四个阶段:
- 任务定义(task specification)
- 模型设定(model setup)
- 仿真过程(simulation process)
- 结果分析(result analysis)
图10 用一个数字猜测游戏(number-guessing game)示范了 SABM 的最小实现单元。这个例子虽然简单,但非常重要,因为它把记忆、推理、规划、个性化、对话等能力都拆开演示了一遍。
作者在实现层面尤其强调以下方法:
- 记忆(memory):通过历史记录、摘要(summarization)或向量检索(embedding + vector database)弥补 LLM 原生无长期记忆的问题;
- 领域知识(domain knowledge):可显式注入,如二分查找(binary search);
- 少样本学习(few-shot learning):用少量示例校正行为;
- 链式思维/推理(chain-of-thought reasoning):提升决策质量;
- 规划(planning):让智能体先想策略,再行动;
- 个性化(personalization):让不同角色表现出不同决策风格;
- 对话(conversation):模拟多智能体之间的信息传播;
- 模型解释(model interpretation):要求智能体解释“为什么这样做”,把黑箱变成白箱。
4. 设计方法论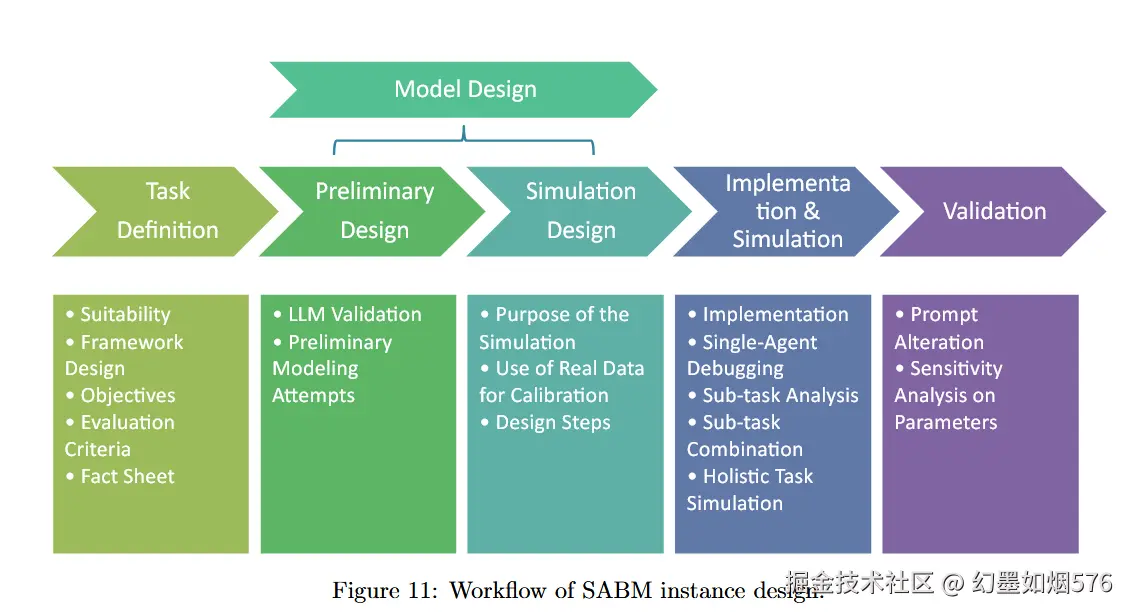
图11 展示了作者提出的 SABM 设计工作流:任务定义、初步设计、仿真设计、实现与仿真、验证。它很像把软件工程、实验设计和社会模拟方法论揉在了一起。
图12 则用数字猜测游戏进一步说明:不同 LLM 的行为质量确实不同。GPT-4 更接近二分查找策略,而 GPT-3.5 表现出更高随机性。这里传递出的信息非常直接——SABM 的上限,很大程度上依赖你选的“引擎”。
5. 技术细节
虽然本文更偏方法论与框架建构,而不是提出某个统一优化目标,但我更倾向于把 SABM 的决策过程写成下面这种抽象形式:
其中:
- 表示时刻 的环境状态;
- 表示智能体记忆(memory);
- 表示 persona(角色设定);
- 表示外部或内置知识(knowledge);
- 表示交互历史(interaction history);
- 表示智能体在该时刻生成的动作(action)。
这个式子不是论文原文给出的正式公式,但它非常适合概括 SABM 的本质:动作不再仅仅由少量数值参数决定,而是由状态、记忆、身份、知识和语言交互共同生成。
四、实验与结果分析
本文的实验不是统一数据集上的 benchmark,而是三个案例研究(case studies),分别对应三类问题:群体疏散、司法决策、经济竞争。
1. 案例一:紧急疏散(Emergency Evacuation)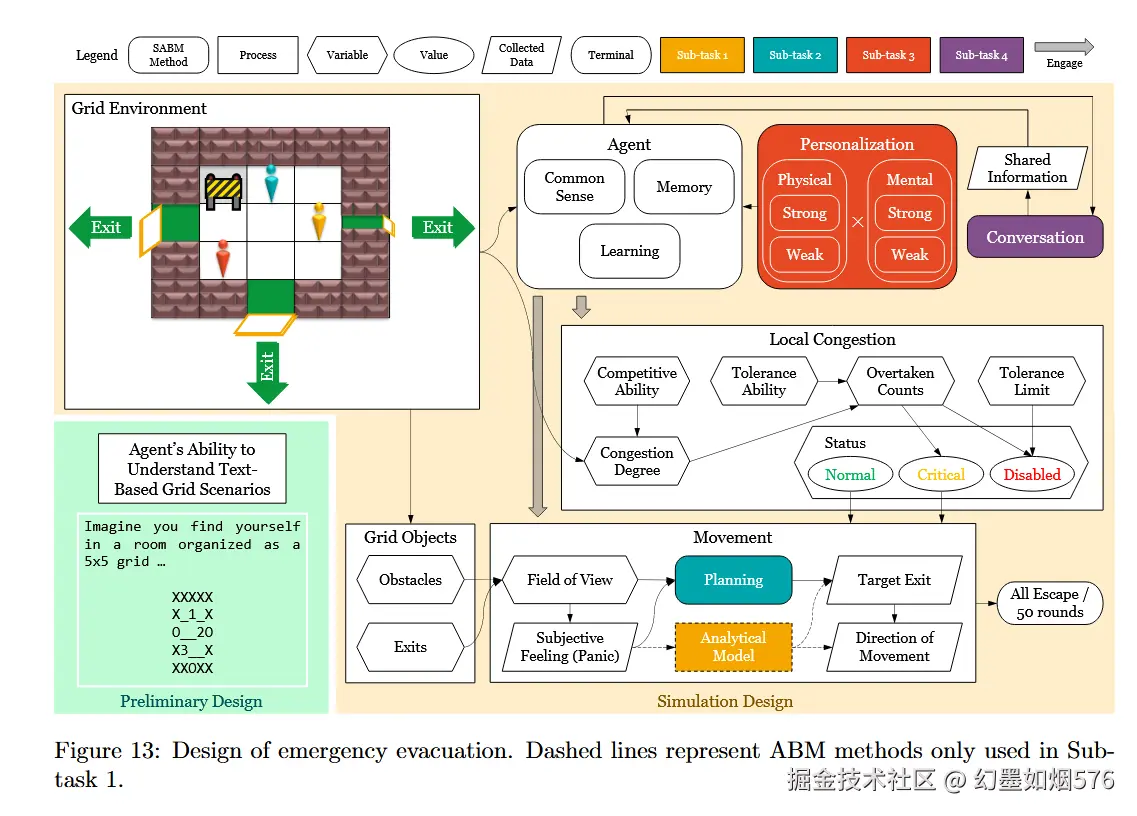
图13 给出了紧急疏散案例的完整结构。作者构建了 33 × 33 的网格环境(grid environment),设置三个出口,并让智能体在看到局部人群信息、出口距离和拥堵程度后,结合自己的身体/心理状态做判断。
图14 与 图15 说明了一个很现实的问题:不是所有 LLM 都能胜任这种“文本化空间理解”。在作者的预设计测试里,GPT-4 能较好理解网格与坐标,GPT-3.5 则表现出明显不稳定,因此后续主实验选择 GPT-4。
图16 与 图17 很值得单独记一下。作者没有一上来就跑大规模多智能体模拟,而是先做 single-agent debugging(单智能体调试),逐步检查坐标理解、路径规划与局部交互是否合理。这种做法非常工程化,也非常实用。
图18 对应子任务 1:作者先让 SABM 尽量复现原有 ABM 里的拥堵/恐慌参数效果。结果显示,SABM 至少可以达到“替代部分参数化设定”的水平。
图19 展示了基础模型在拥堵情境中的表现:智能体会在右侧出口过于拥挤时,主动改道到其他出口。这里最关键的一点不是“它改道了”,而是它并没有被硬编码要求改道,而是在自然语言任务描述下做出了适应性判断。
图20 与 图21 说明了人格化和交流机制的效果:
- 加入 persona 后,不同身体/心理特征群体的疏散效率出现可区分差异;
- 体力强、心理强的群体疏散更快;
- 体力弱、心理弱的群体最慢;
- 引入对话后,不同群体之间的差异有所缩小,作者认为这是“自发协作”带来的结果。
图22 展示 400 个智能体的高密度疏散;图24 则通过一个对话例子说明,个体会受到周围语言信息影响而改变出口选择。这一点非常贴近现实中的“跟随行为”。
图25 给出带障碍物的场景。一个有意思的发现是:障碍物并没有像某些 ABM 文献中那样自然带来更有序的疏散,反而可能阻碍个体从拥堵出口迁移到替代出口。
图26 是我很喜欢的一张图。作者做了类似“提示词敏感性分析”(prompt alteration / sensitivity analysis)的验证:低程度改写、中程度要素变化、高程度目标变化。结果表明,模型对轻微改写相对稳健,但当任务目标被改成“在画廊里慢慢看画再离开”时,行为路径也会显著变化。换句话说,SABM 对“任务语义”是敏感的,这既是能力,也是风险。
2. 案例二:认罪协商(Plea Bargaining)
第二个案例转向司法心理与行为决策。作者模拟被告面对认罪协商时的接受意愿(Willingness to Accept Plea, WTAP),并考察四个因素:
- 实质公平(substantive fairness)
- 自我中心偏差(egocentricity)
- 比较公平(comparative fairness)
- 风险偏好(risk preference)
这个案例的重要性在于,它几乎没有复杂空间交互,但非常依赖“软因素”——也就是传统 ABM 最难处理的那部分人类心理。
论文的结论大致是:
- GPT-4 智能体经过人格化和少样本学习校准后,在若干趋势上更接近人类被试;
- “是否自认有罪”显著影响其是否接受认罪协议;
- 但在不确定 culpability 的情况下,模型并没有完全复现人类实验中那种典型的 egocentricity;
- 这说明 LLM 的“对齐”(alignment)可能既帮了忙,也带来了偏差:它让模型更合乎伦理,但未必更像真实世界中的被试。
3. 案例三:企业定价竞争(Firm Pricing Competition)
第三个案例模拟两个企业在多轮博弈中的定价竞争与合谋(collusion)形成。这里的重点,不是简单比较价格高低,而是观察:
- 没有交流时,是否会出现默契合谋(tacit collusion);
- 有交流时,是否更容易形成显性合谋(explicit collusion / cartel);
- 智能体是否会根据收益结果不断调整策略。
这个案例说明 SABM 不只适合“人类社会心理”问题,也可以进入经济行为与策略互动领域。相比传统基于规则的市场仿真,SABM 的优势在于它能把协商、试探、表述与策略调整统一放进自然语言互动里。
4. 数据集、基线模型与结果总结
- 数据集:
- 本文不是标准 benchmark 论文,没有统一公共数据集。
- 更多依赖既有 ABM 文献设定、问卷实验结果与案例任务构造。
- 基线模型:
- 传统 ABM 设定;
- GPT-3.5 与 GPT-4 的对比。
- 主要结论:
- 定量结果:
- GPT-4 在数字猜测任务中明显优于 GPT-3.5;
- 疏散案例中,不同 persona 会形成稳定的效率差异;
- 认罪协商案例中,GPT-4 经校准后在若干趋势上接近人类实验结果。
- 定性分析:
- SABM 擅长建模自然语言驱动的行为;
- 能把常识、主观判断和交互过程更自然地纳入模拟;
- 但其输出存在随机性、计算开销高、可复现性受模型版本影响等问题。
- 定量结果:
五、总结与展望
1. 论文贡献
我觉得这篇文章最核心的贡献,是完成了三层推进:
- 概念推进:把 LLM 引入复杂系统模拟,系统性提出 SABM;
- 方法推进:把任务定义、建模、调试、验证串成了一整套流程;
- 案例推进:用三个跨领域案例证明,这套框架并非停留在概念层面。
更具体地说,本文真正有分量的地方在于:它把“自然语言”从模拟研究的旁白,变成了模拟研究的内部机制。
2. 个人思考
这篇文章给我最大的启发,是它重新打开了一个过去常被默认关闭的问题:复杂系统模拟,到底能不能更像“真实的人在情境中行动”,而不只是“参数在规则中跳转”? SABM 给出的回答是:可以试着往前走一步。 但我也觉得,SABM 现在还远没有到“可以替代 ABM”的程度。它更像一种高表达力、但高成本、高波动的新范式。尤其有几个问题我认为后续非常关键:
- 可复现性:换一个模型版本,结果可能就变了;
- 可控性:自然语言越灵活,越容易引入不可预期偏差;
- 验证问题:我们如何判断 LLM 真的“理解了行为机制”,而不是只是在生成一个看起来合理的答案;
- 成本与规模:当智能体数量上升时,SABM 的算力和费用问题会很突出;
- 伦理风险:如果模拟对象本身涉及偏见、歧视、犯罪、恐慌等敏感议题,LLM 的价值对齐与数据偏差都会放大影响。
