

OpenAI 刚刚发布 GPT-5.4,这次不只是模型更新,而是把推理、编程、Computer Use 和 Agent 工具调用全部整合到了一个模型里。GPT-5.3 活了不到 48 小时,GPT-5.4 就来了——速度快得让人有点不适应,但能力确实上了一个台阶。
GPT-5.4 是什么
2026 年 3 月 5 日,OpenAI 正式发布 GPT-5.4。同步上线的还有 GPT-5.4 Pro,提供更高性能的推理上限。

官方的定位是"面向专业工作的最强前沿模型":一个模型把 GPT-5.3-Codex 的编程能力、GPT-5.2 的通用推理、以及全新的 Computer Use 能力打包在一起。
在 ChatGPT 里它叫 GPT-5.4 Thinking,在 API 和 Codex 里直接叫 gpt-5.4,Pro 版叫 gpt-5.4-pro。
五个核心能力

OpenAI 对 GPT-5.4 的能力总结很清晰,五项核心:
原生 Computer Use——能写 Playwright 代码操控电脑,读截图、发键鼠操作,在 OSWorld-Verified 上达到 75.0% 成功率,超过人类基线 72.4%。
百万 Token 上下文——Codex 和 API 支持最高 1M token,Agent 跑长任务不用再切割上下文了。
顶级编程能力——在 SWE-Bench Pro 上超过 GPT-5.3-Codex,同时延迟更低。
Tool Search 工具搜索——Agent 调用工具时不再把全部工具定义塞进 prompt,而是按需取用,实测减少 47% token 用量。
更高效的推理——用更少 token 解决更复杂问题,速度比 GPT-5.2 快很多。
跑分一览
| 评测项 | GPT-5.4 | GPT-5.3-Codex | GPT-5.2 |
|---|---|---|---|
| GDPval(专业工作) | 83.0% | — | 70.9% |
| SWE-Bench Pro(编程) | 57.7% | 56.8% | 55.6% |
| OSWorld-Verified(Computer Use) | 75.0% | 74.0% | 47.3% |
| Toolathlon(工具调用) | 54.6% | 51.9% | 46.3% |
| BrowseComp(网页搜索) | 82.7% | 77.3% | 65.8% |
GDPval 测试的是在 44 种职业真实工作场景下(销售 PPT、会计表格、排班表、制造流程图等),GPT-5.4 和行业专业人士相比胜或平的比例达 83%,比 GPT-5.2 的 70.9% 提升明显。
OSWorld 的提升最直观:从 47.3% 跳到 75.0%,超越人类基线,Computer Use 终于真的能用了。
ValsAI 也同步发布了 Vibe Code Bench 数据:

GPT-5.4 以 67.4% 位居第一,比此前最优模型高出 5.7%。这个基准测的是从一段简短描述出发,完整生成一个可运行应用的能力。
Computer Use:超越人类基线
GPT-5.4 的 Computer Use 有两套路子:一是写 Playwright 代码控制浏览器(开发者更熟悉),二是直接接收截图然后发出键鼠操作(更通用)。
更重要的是,行为可以调整。开发者可以通过系统消息设定不同的风险容忍度和确认策略——高风险操作(比如删文件)可以让模型暂停等确认,低风险操作直接执行。这让 Computer Use 真正可以在生产环境里用,而不只是 demo 好看。
官方同步推出了 Playwright Interactive 这个 Codex Skill,让模型在构建 web 或 Electron 应用的同时,直接视觉调试。
Tool Search:解决 Agent 规模化的拦路虎
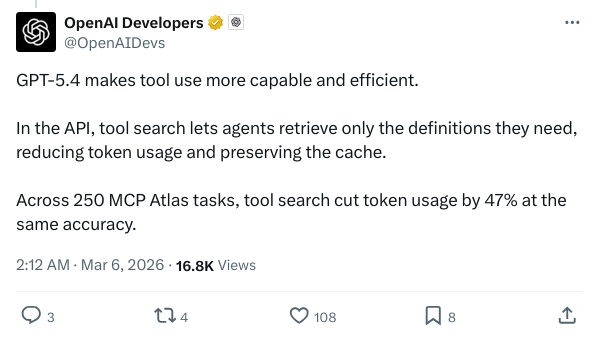
之前 Agent 调用工具有个很头疼的问题:工具多了,所有工具定义都要塞进 prompt,几万 token 就这么浪费了,还推着缓存频繁失效。
Tool Search 的解法是:给模型一个轻量级的工具列表 + 一个搜索能力,需要用哪个工具再去取定义,而不是上来就把全部塞进来。
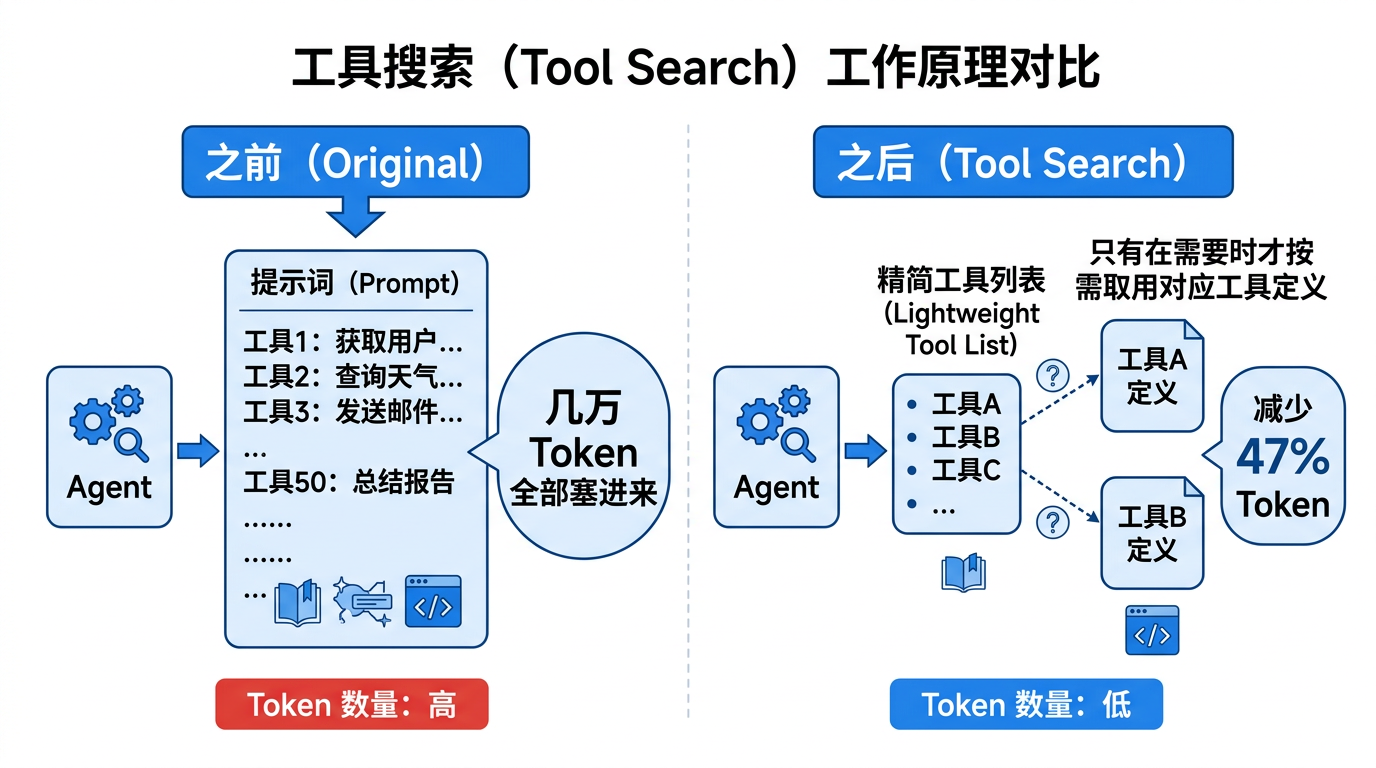
实测数据很说明问题:250 个 MCP Atlas 任务,启用 Tool Search 后,token 用量减少 47%,准确率保持不变。
开发者社区里有人把这个总结得很到位:
"tool search 是大家忽略的那行字——之前 20 个工具就够让 Agent 崩的问题,现在有解了。"
开发者已经在用了:真实 Demo 看什么感觉
GPT-5.4 发布后几小时,X 上已经出现了开发者自己录的实测视频。挑几个有代表性的。
模型自己构建游戏,然后自己打开浏览器测试
@johnolafenwa 在 Codex 里用最喜欢的 prompt 测了一遍,结果让他比较惊讶的不是写代码,而是模型写完以后自己打开浏览器测试,发现问题再迭代,全程没有人干预。

下面是 GPT-5.4 用 Playwright MCP 自测游戏的动态演示——它自己打开游戏,读截图,然后发出操作:
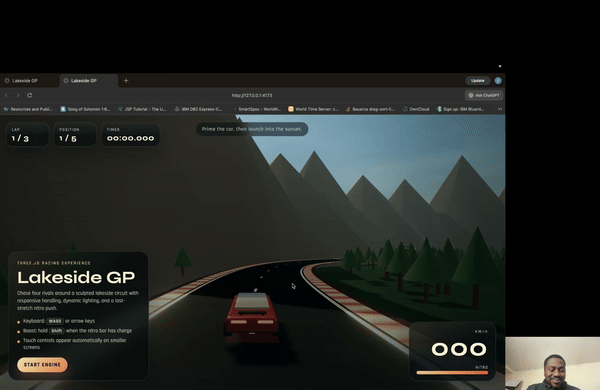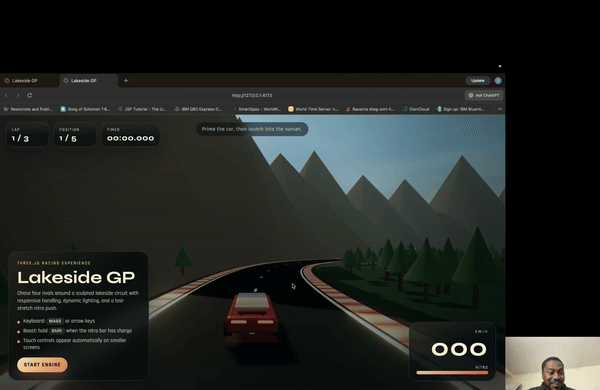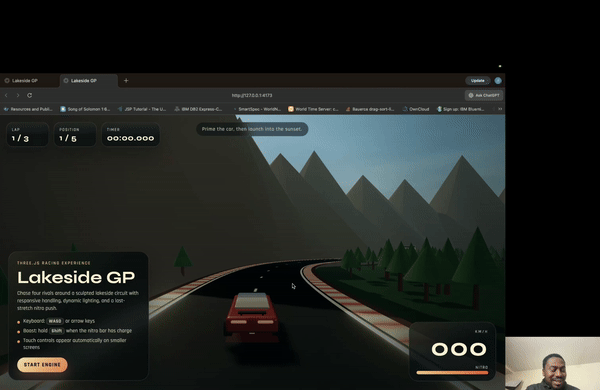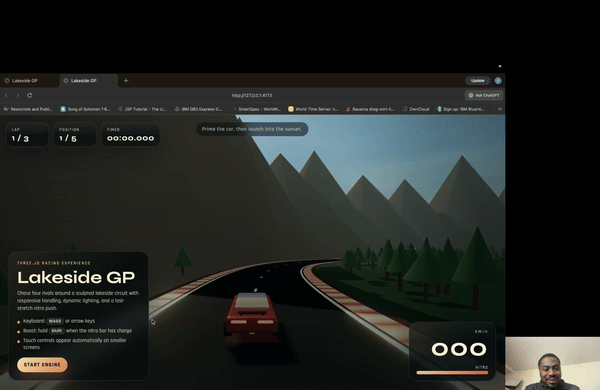
这正是 Computer Use + 编程能力结合后最直接的场景:模型不只是写代码,而是能看到运行效果,然后自己改。
7 个例子,一个 prompt 一个结果
@minchoi 整理了 7 个实际任务,包括构建并可玩的 3D 棋类游戏:

1M token 上下文让这类需要长期保持状态的任务(游戏逻辑、多轮规划)不再需要手动切割和传递上下文。
编程能力:跟 Claude Opus 4.6 的实测对比
GPT-5.4 上线后,社区里出现了不少 vs Claude 的实测。有开发者用同一个 8 阶段 MacOS 应用开发项目做了测试:GPT-5.4 在一小时内完成了所有 8 个阶段,而 Claude Code Opus 4.6 在同样时间只走完了第 2 阶段。

当然这只是单次测试,不代表所有任务上 GPT-5.4 都快这么多。但从模型定位来看,GPT-5.4 明显更适合长流程、多工具、需要不断迭代的任务,而不是单次对话。
Codex 里还加了 /fast 模式,开启后同样的模型和智能水平,token 速度提升最高 1.5x。
在 SWE-Bench Pro 上,GPT-5.4 的 57.7% 超过了 GPT-5.3-Codex(56.8%),同时延迟更低。这个组合——更强且更快——是编程任务里比较少见的。
深度测试者怎么看:优点和短板都说清楚
Matt Shumer 是少数提前拿到测试权限的开发者,他的评测算是这次比较有料的一篇。

他的核心判断是:这是目前世界上最好的模型,而且好的程度让「用哪个模型」这个问题开始显得没那么重要了。
具体说了几点:
标准版已经打爆上一代 Pro 版。他自称是 Pro 模式重度用户,但 GPT-5.4 标准版 + 重度思考,第一次让他放弃了惯性地去开 Pro。这意味着日常使用成本会显著下降。
编程能力基本没有可以说的了。原话是"coding is essentially solved"——在 Codex 里的稳定性让他觉得这块已经没什么可以补充的了。
推理 token 更省。同等质量的结果,用的推理 token 更少,速度更快。他提到之前 OpenAI 模型让他最不满意的就是简单任务也跑得很慢,这次有明显改善。
但他也直接说了两个硬伤:
- ❌ 前端审美远落后于 Opus 4.6 和 Gemini 3.1 Pro。做 UI 的话,GPT-5.4 的视觉感知和审美判断比 Claude 差得明显,如果你在做客户端工作,这个差距会直接影响交付质量
- ❌ 会漏掉真实世界的隐性常识。他举例:让它规划行程,表面看起来完美,但没考虑到那段时间目标地点会被大学生春假占满,需要重新给更多背景才能改正
社区里对「前端审美」这个点的共鸣很高,很多开发者的工作流是:后端逻辑给 GPT,UI 给 Claude。Matt 的评测让这个分工逻辑更清晰了一点。
当然也有人觉得他说得太满。有评论指出 SWE-Bench Pro 57% 并不算"编程问题解决了",更有人提醒这类提前测评本质上是一种流量合作,要打折扣来看。这个判断留给大家自己。
ChatGPT 里的新体验
不只是 API 端有变化,ChatGPT 里的 GPT-5.4 Thinking 也有几个新东西。
最值得关注的是"中途打断"功能:模型在推理过程中,用户可以随时插入新指令或调整方向,不需要等它回答完再重新提问。
这件事听起来小,但实际上改变了深度推理任务的交互模式。之前用 Thinking 模式,你提个问,然后就干等——等它想完了才能告诉它"方向不对"。现在可以实时纠偏,省去了大量无效等待。
另外,GPT-5.4 Thinking 会在开始工作时先给出一个大纲或工作计划,让你知道它准备怎么做。这是学 Codex 的风格——先展示思路,再执行。
深度网页搜索也有提升,特别是需要跨多个来源综合信息的"针尖"类问题,BrowseComp 上跳了 17% 绝对值。
专业工作能力
GPT-5.4 在专业工作场景(GDPval)的提升是 OpenAI 这次着重强调的方向。
内部电子表格基准测试:GPT-5.4 得 87.3%,GPT-5.2 只有 68.4%。PPT 制作上,人类评估者 68% 的时候更偏好 GPT-5.4 的版本,原因是视觉更丰富、图片更有变化。
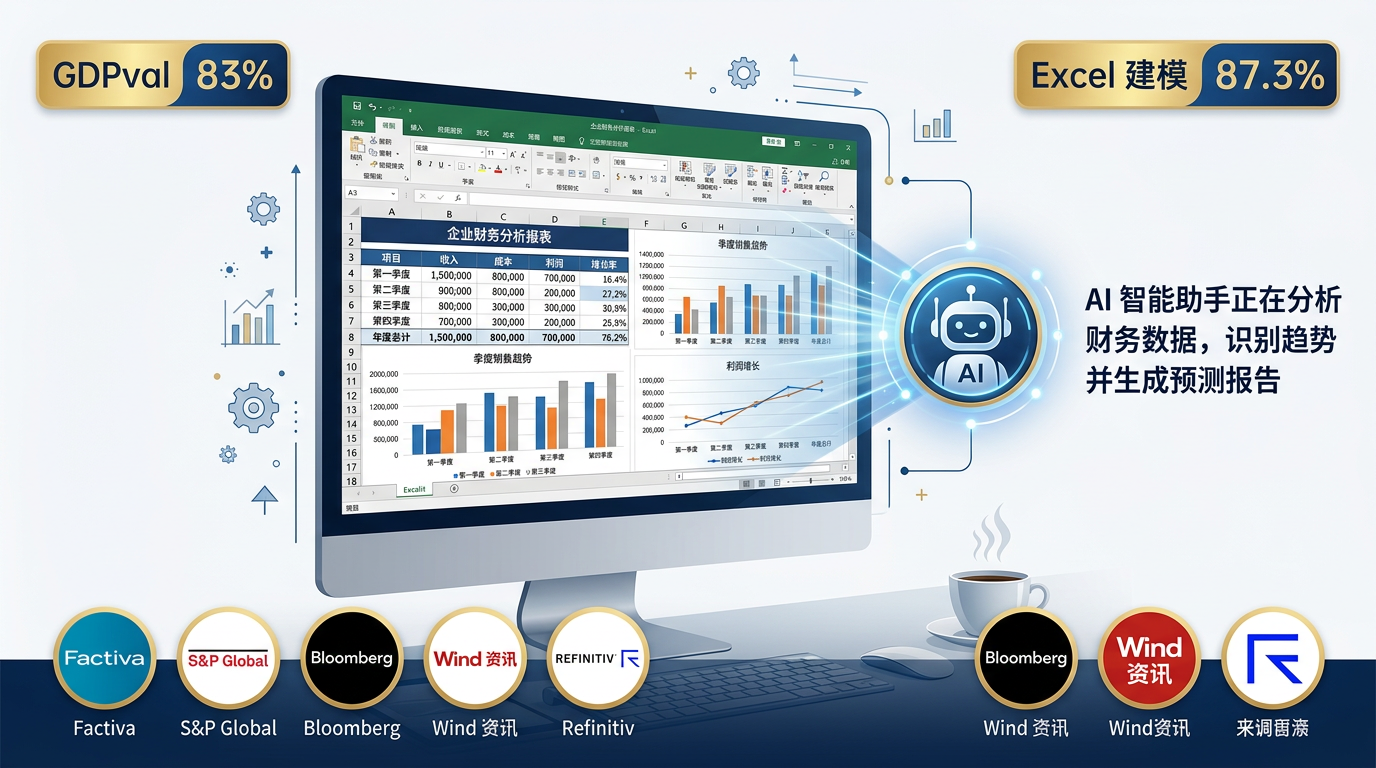
同步上线的还有 ChatGPT for Excel 插件,面向企业用户。Excel、Factiva、Daloopa、S&P Global 等财务数据源的接入,显然是奔着金融分析场景去的。
幻觉下降,事实错误减少 33%
这个数据在官博里比较低调,但其实很重要。
在用户标记了事实错误的 prompt 集合上,GPT-5.4 单条声明出错的概率比 GPT-5.2 低 33%,完整回答含错误的概率低 18%。
对于要把 AI 用在实际工作里的人来说,这个比跑分数字更实在。
开发者怎么接入
API 里模型名:
gpt-5.4— 标准版gpt-5.4-pro— Pro 版
新能力主要是两个 API 参数:
- Computer Use:通过更新后的
computer工具参数调用 - Tool Search:通过新的
tool_search参数启用
图片输入也更新了:新增 original detail 级别,支持最高 10.24M 像素或 6000 像素边长(取低者);high 级别也提升到 2.56M 像素上限,对定位精度和点击准确性有明显提升。
最后说一句
GPT-5.3 活了不到两天就被 GPT-5.4 取代,不少用户在评论区抱怨版本迭代太快、没时间适应。这个情绪可以理解,但换个角度看——能力真的在快速提升。
五个核心改进里,Computer Use 超越人类基线、Tool Search 解决 Agent 规模化成本是实质性突破,不是跑分游戏。1M token 上下文加上中途打断功能,让 GPT-5.4 更像一个能配合你工作节奏的工具,而不是等你提问的对话框。
接下来有意思的问题:Claude Opus 4.6 + GPT-5.4 并行用,什么任务给谁?这个答案在接下来几周会越来越清晰。
参考链接
- OpenAI 官方博客:openai.com/index/intro…
- GPT-5.4 API 文档:developers.openai.com/api/docs/gu…
- Tool Search 使用指南:developers.openai.com/api/docs/gu…
- Playwright Interactive Skill:github.com/openai/skil…
