

Anthropic 刚刚给 Claude 的 skill-creator 加了一套测试框架——写 evals、跑基准测试、A/B 对比两个版本的 Skill,而且全程不需要写一行代码。这意味着,非工程师背景的领域专家,也终于有工具知道自己的 Agent Skill 到底管不管用了。
一个让人尴尬的现实
你花了几个小时写了一个 Agent Skill,测试了几次,感觉还不错。然后模型更新了,你不确定它还能不能用。你改了一个细节,不知道效果是变好还是变差。你加了新 Skill,不知道它会不会和别的 Skill 打架、乱触发。
这是大多数 Skill 作者的日常困境。Anthropic 自己也意识到了这个问题:大多数 Skill 的作者是领域专家,不是工程师,他们懂自己的工作流,但没有工具去验证 Skill 是否真的按预期工作。
于是有了今天这次更新。

先搞清楚:你的 Skill 是哪种?
在讲测试之前,Anthropic 提出了一个很有用的分类框架。
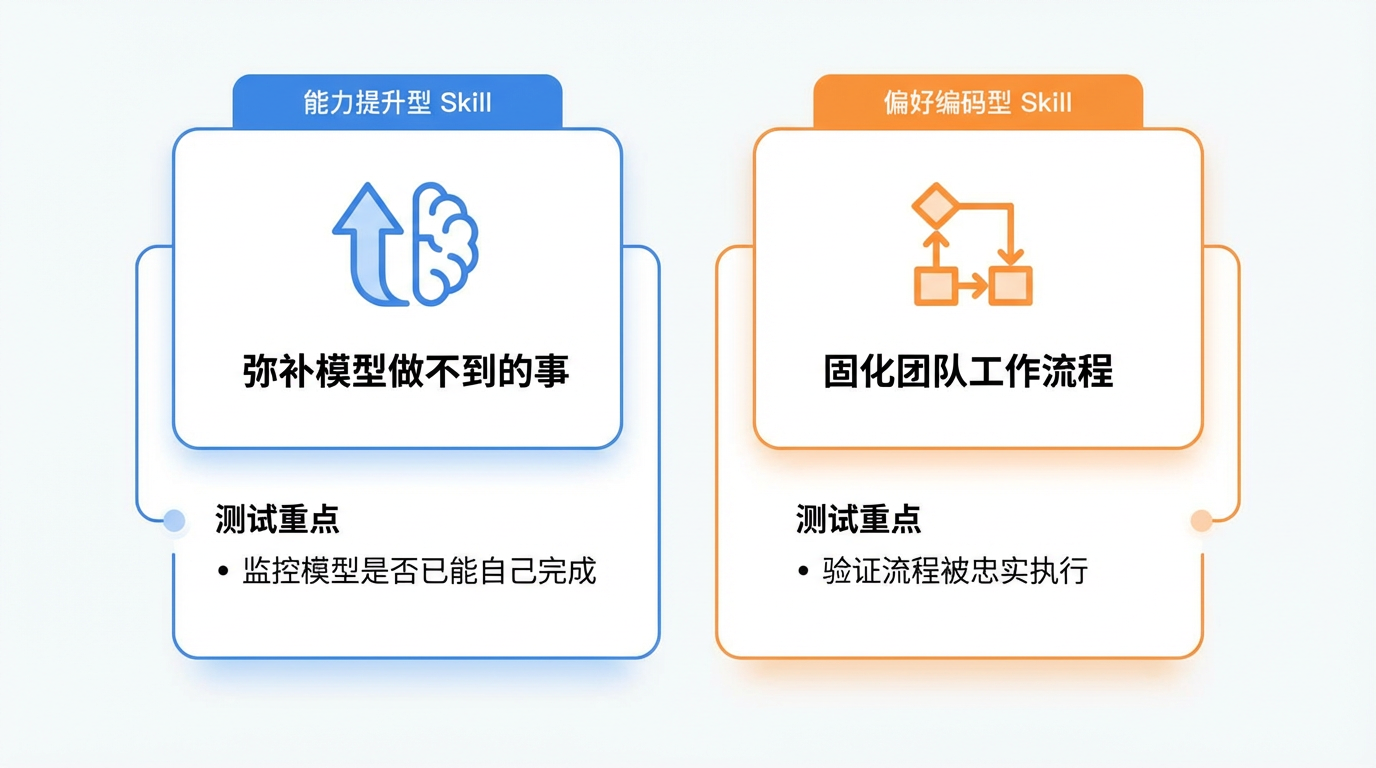
能力提升型 Skill:模型原本做不到或做不稳定的事,通过 Skill 注入技巧和模式来稳定输出。比如 PDF 表单处理——模型需要在没有字段引导的情况下精确定位文字坐标,这是个需要特定技巧的任务。
偏好编码型 Skill:模型每一步都能做,但需要按团队的特定流程排序。比如 NDA 审查需要按照固定标准逐条核对,周报需要按公司模板格式输出——不是模型能力的问题,而是团队流程需要被"编码"进去。
为什么这个分类重要?因为这两种 Skill 的测试重点完全不同:
| 类型 | 测试重点 |
|---|---|
| 能力提升型 | 监控基线模型是否已能自己完成任务(Skill 可能"过时"了) |
| 偏好编码型 | 验证流程是否被忠实执行(而非模型自由发挥) |
这个框架本身就很有价值——它帮你想清楚,你写的 Skill 到底是在弥补模型能力的不足,还是在固化团队的工作方式。
新功能:给 Skill 装上单元测试
Evals:Skill 的"单元测试"
最核心的新功能是 evals 支持。
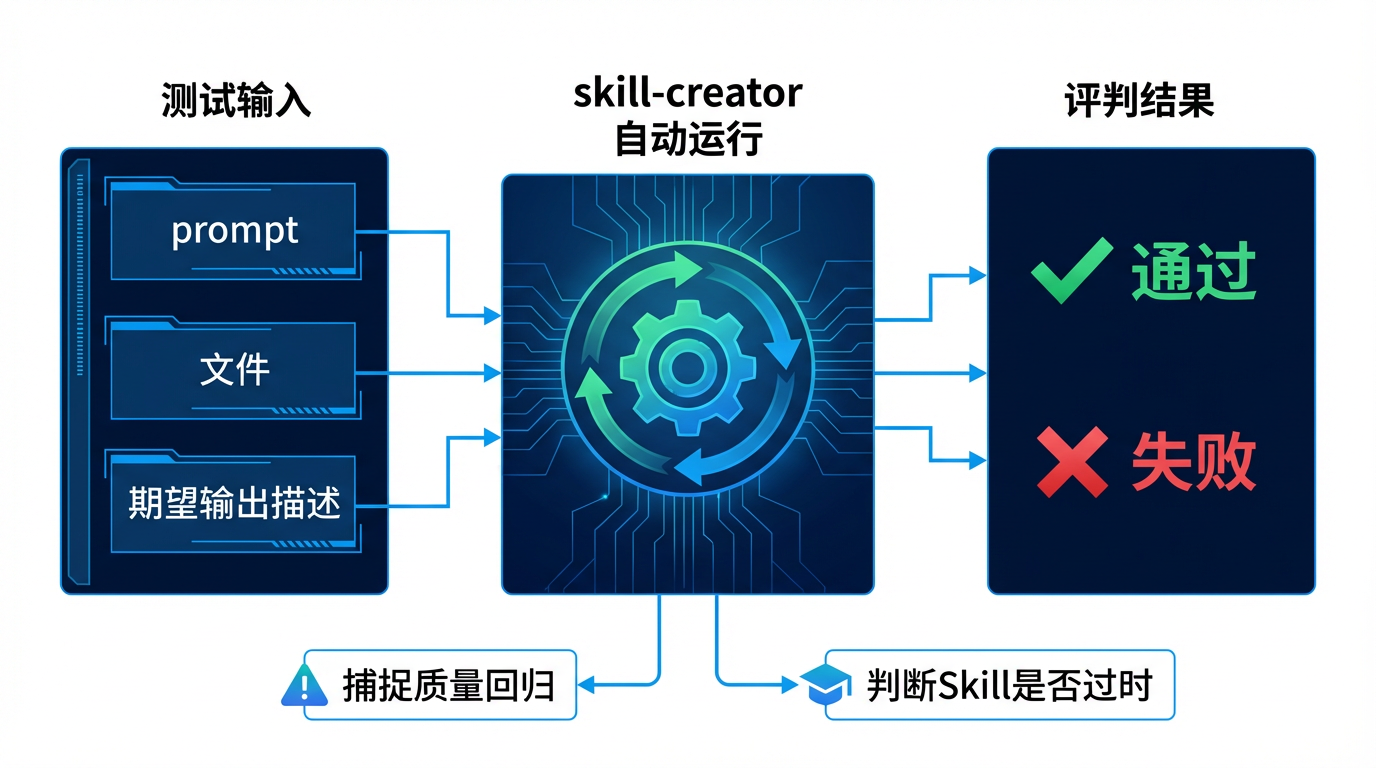
做法很简单:提供一组测试 prompt(加上需要的文件),描述"好的输出应该是什么样子",skill-creator 就会自动运行 Skill 并判断是否达标。
官方举了一个真实案例:PDF Skill 之前无法正确处理没有可填字段的表单——模型需要在没有任何字段引导的情况下把文字放到精确坐标。evals 精准定位了这个失败场景,团队据此修复,将定位逻辑改为"锚定已提取的文字坐标",问题解决。
没有测试,Skill 只是"看起来管用";有了 evals,才是"确切知道管用"。
两个实际用途值得重点关注:
一是捕捉质量回归。模型和基础设施一直在迭代,上个月好好的 Skill,这个月可能行为就变了。在影响到团队工作之前,evals 能给你早期信号。
二是判断 Skill 是否"过时"。主要针对能力提升型 Skill——如果基线模型不加载 Skill 就能直接通过你的 evals,说明这个 Skill 的技巧已经被内化进了模型的默认行为,不再需要了。这不是 Skill 坏了,是它"毕业"了。
Benchmark 模式:可追踪的性能仪表盘
evals 跑完一次是快照,benchmark 模式是让你把快照连成时间线。
它批量运行同一组 evals,输出三个指标:通过率、执行时间、token 消耗。可以在每次模型更新后跑一遍,也可以在每次修改 Skill 前后各跑一次,追踪变化趋势。
结果支持本地存储、接入仪表盘,或直接挂进 CI/CD 流水线——相当于把 Skill 纳入了软件开发的持续集成体系。
多 Agent 并行 + 盲测比较
顺序跑 evals 有两个问题:慢,而且前一个测试的上下文可能污染后一个。新版本用多 Agent 并行解决了这个问题——每个 eval 在独立的干净上下文里运行,有自己的 token 计数和计时,互不干扰。
比较 Agent(Comparator Agent)的工作原理:
同时运行两个版本的 Skill(A vs B,或有 Skill vs 无 Skill),让第三方 Agent 在不知道哪个是哪个的情况下评判输出质量。盲测消除主观偏差,让你知道改动是真的变好了还是只是感觉变好了。
触发描述智能调优
随着 Skill 库扩大,触发描述的精度变得越来越关键。太宽泛会乱触发,太精确会从不触发。
新版 skill-creator 会分析你当前的描述,对比历史触发样本,建议更精准的措辞——同时降低误触发和漏触发。
Anthropic 用自己的 6 个公开文档创建 Skill 测试了这个功能,5 个触发准确率有显著提升。
一个值得想的问题
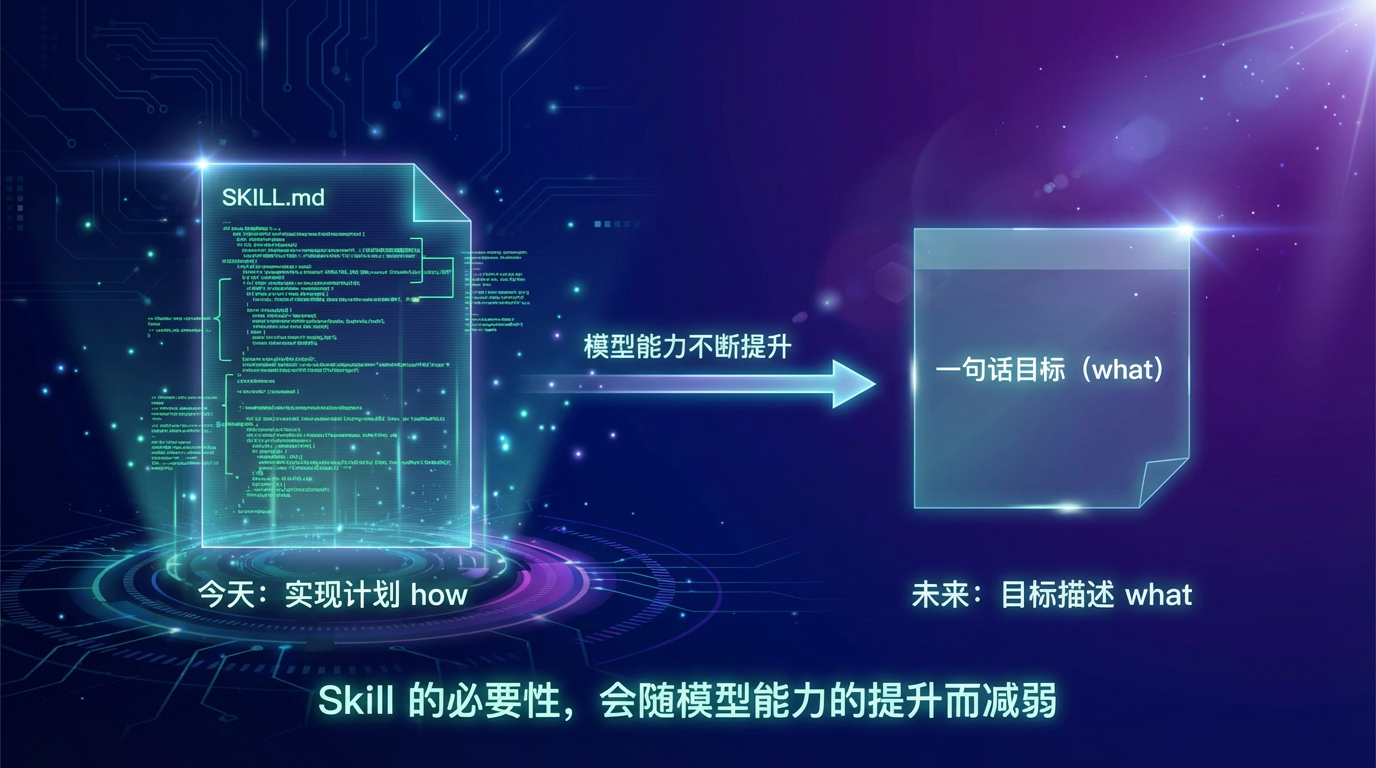
Anthropic 在博客末尾留了一个预判:今天的 SKILL.md 本质上是"实现计划"(how),告诉模型怎么做某件事。随着模型能力越来越强,未来可能只需要"目标描述"(what),模型自己推导实现路径。
这次发布的 evals 框架,正好是这个方向上的一步——因为 evals 描述的是"应该发生什么",而不是"怎么做到"。换句话说,evals 本身就在向 Skill 的未来形态靠近。
当然现在还早,但这个方向值得关注:Skill 作为"实现细节"的必要性,会随着模型能力的提升而逐渐减弱。
怎么用起来
目前所有更新已在 Claude.ai 和 Cowork 上线。
Claude Code 用户可以安装插件:
/plugin marketplace add anthropics/skills
或直接从 GitHub 获取:
skill-creator 本体在:
总结
- 两种 Skill 类型:能力提升型(弥补模型不足)和偏好编码型(固化团队流程),测试重点不同
- Evals:给 Skill 写测试用例,验证在各种输入下是否输出符合预期
- Benchmark 模式:追踪通过率、执行时间、token 消耗,可接入 CI/CD
- 多 Agent 并行 + 比较 Agent:并行跑、盲测比,客观评估改动效果
- 触发描述调优:用数据降低误触发和漏触发
- 未来方向:evals 描述的是"应该发生什么",正向未来 Skill 形态演进
参考链接
- Claude 官方博客:claude.com/blog/improv…
- skill-creator GitHub:github.com/anthropics/…
- Claude Code 插件:github.com/anthropics/…
