

先看最终效果:

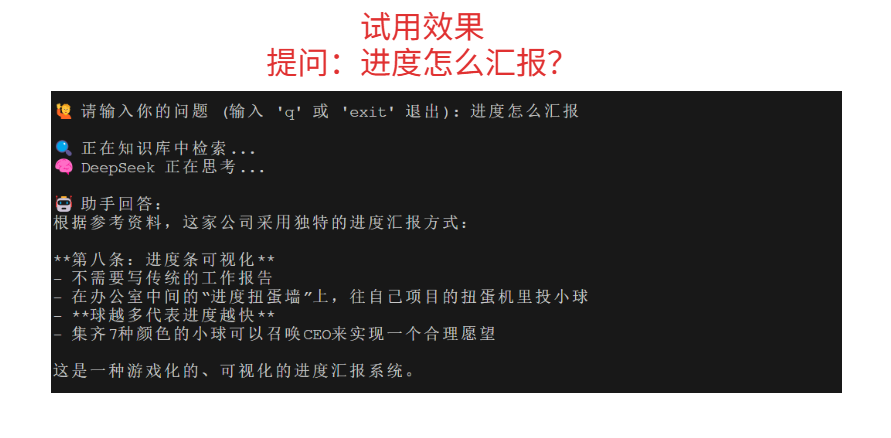
如图所示,上面这些问题的答案明显不是互联网上Deepseek的标准回答,而是基于我们能前面创造的猎奇文档:《不正经有限公司 正经管理办法》 给出的答案。
你可以在这里获取到它的全文:
在经过了长达5节课的理论学习,工具准备,数据准备之后,我们的RAG终于可以实现它的效果了!
这是RAG实战的小结之课,看看我们如何贯通先前的所有准备吧?
一、查询思路
现在,先让我们把用户查询RAG的思路捋清楚,只要思路清楚了,用什么工具,用什么语言都会变得非常容易:
首先,用户输入问题“啥情况下会被派去喂猫?”
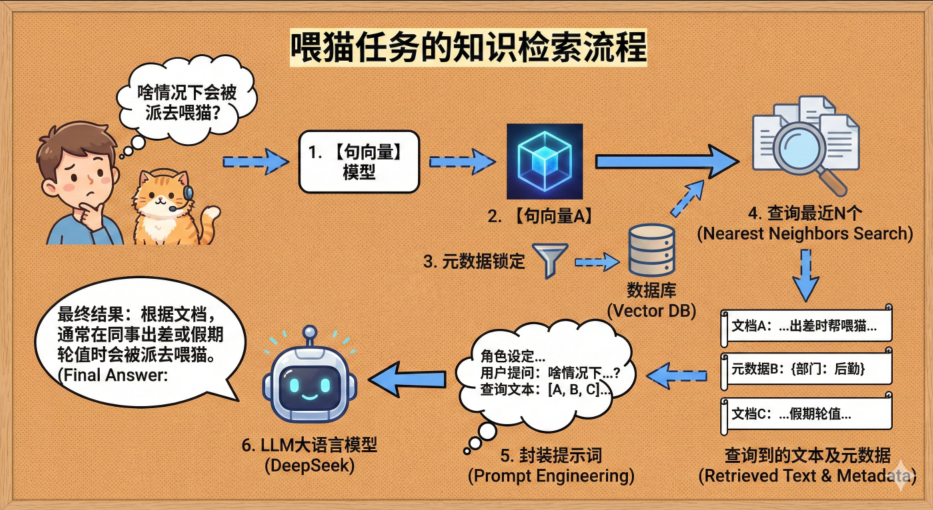
第一步:意图向量化 (Embedding)
计算机是不懂“啥情况下会被派去喂猫?”的含义的,但我们有了Embedding 【句向量模型】,可以成功的把这句话翻译成512维的向量。
调用本地的 bge-small-zh-v1.5 模型,将这句人类语言转化成了一个 512 维的数学坐标(向量)。
第二步:定位语义相似的文本
ChromaDB 拿到了这个代表用户问题的“数学坐标”后,进入其底层的 HNSW(分层可导航小世界)索引图中。 它不比对字面量,而是比对空间距离(余弦相似度)。
它迅速找出了离问题坐标最近的 3 个知识块(Chunk),连同它们入库时绑定的元数据(Metadata,如来源文件名),一起原封不动地捞出来。
第三步:拼装文本
捞出来的 3 个知识块是零散的文本。
在代码中,我们通过一个 for 循环,把这些文本连同它们的来源标签,像拼乐高一样拼接成了一个长字符串 retrieved_context。这就形成了一份完美的“开卷考试参考资料”。
第四步:增强生成
这是最后一步,也就是大模型(DeepSeek)登场的时刻。我们把用户的原始问题,加上刚才拼好的“参考资料”,通过一个精心设计的 Prompt(提示词) 发送给 DeepSeek。DeepSeek 此时不再依赖自己可能产生幻觉的内在记忆,而是死死盯着你给的参考资料,提取出精确的答案返回给用户。
提示词必须包含: - 文档查询者的角色设定和基本要求 - 用户的提问 - 查询到的文本及元数据。
理解这个思路是最重要的,有了它我们就能去使用各种库或者编写代码。
但我们需要注意,如果生产使用的话,通常还会进行两个阶段的优化:
-
在第一步,加入【查询重写 (Query Rewrite)】:系统可以先用一个小模型将这句口语化提问扩充或改写为包含更多关键词的规范表述,再拿去转化为句向量,这样检索出来的结果会更相关。
-
在第三步,加入【重排 (Rerank)】:引入一个专门的 Rerank 模型,对这 N 个片段与用户问题的相关性进行二次精确打分和重新排序,剔除低相关度内容,再喂LLM。这能有效避免 LLM 被无关信息干扰。
但在小文档和简单实践中,我们可以先放下这两步,优先去实现我们的效果。
二、利用 ChromaDB 查询
在查询 Embedding 句向量时,和插入时类似,也是先定义方法实现,然后把实现交给 ChromaDB 另起自行查询。
# ==========================================
# 准备向量数据库的连接
# ==========================================
class OllamaEmbeddingFunction:
def __init__(self, model_name):
self.model_name = model_name
def __call__(self, input):
response = ollama.embed(model=self.model_name, input=input)
return response['embeddings']
def name(self):
return self.model_name
def embed_query(self, input):
return self.__call__(input)
def embed_documents(self, input):
return self.__call__(input)
db_client = chromadb.PersistentClient(path=DB_PATH)
collection = db_client.get_collection(
name=COLLECTION_NAME,
embedding_function=OllamaEmbeddingFunction(model_name=MODEL_NAME)
)
results = collection.query(
query_texts=[user_question],
n_results=3 # 提取最相关的 3 个片段
)
这个results是一个如下结构的数组:
[
{
"distances": 0.9, // 相似度
"documents": "文本xxxx", // 文本切片
"metadata": {
// ... 元数据
}
}
]
三、构建提示词与LLM对话
通过遍历以上的文本,我们可以把元数据中的【章节名】、相似度信息、文本原文组装后,形成一个包含多个可参考文档的长文档,作为【参考文档】。
系统提示词 System Prompt 如下所示:
system_prompt = f"""
你是一个专业的内部知识库问答助手。
请**严格根据**以下<参考资料>中的信息来回答用户的问题。
如果参考资料中没有明确提及该问题的答案,请如实回答“根据现有资料无法得出结论”,绝对不要编造!
<参考资料>
{retrieved_context}
</参考资料>
"""
这就同时包含了【参考文档】和【AI人设】两个核心点了。
只需要再在用户提示词 User Prompt里加上用户的提问,即可向 DeepSeek 发起提问了。(当然也可以是其他更强的LLM)
response = llm_client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_question},
],
temperature=0.1
)
注意这个 temperature 属性。
技术点:
-
temperature (温度值) 控制着 LLM 输出的随机性和创造力。取值范围通常在 0 到 2 之间。
-
写诗、写小说或者你在尝试做讽刺漫画脚本时,你可以把它调高到 0.8 甚至 1.2。
-
但在 RAG 场景下,我们要求的是绝对的忠诚和精准。将温度设为 0.1(甚至 0),能最大程度限制 AI 的发散思维,迫使它老老实实地做“阅读理解”和信息提取。
至此,你已经从零开始,亲手徒步穿越了 RAG 架构的完整生命周期。从利用 LangChain 切割 Markdown、利用本地 Ollama 计算向量、利用 ChromaDB 存储与检索,再到调用 DeepSeek 增强生成,这是一条极具含金量的全栈 AI 链路。
如果要尝试,你可以在 demo 工程里获取代码:
依次执行这两个命令即可:
- 生成向量库(上一章内容)
python .\lesson_09\split_and_save.py
- 查询交互
python .\lesson_09\query.py
五、小结
经过长达六节课的学习和梳理,我们终于完成了一个简单RAG系统的构建!
下一步,我们将前往探索Agent系统中最复杂,也最核心的一个领域:
记忆 Memory。
敬请期待!

