

从工具到团队:Claude Opus 4.6 发布,AI 写代码的时代正式结束了
当 AI 不再是一个人干活,而是一群人协作,意味着什么?
Anthropic 在 2 月 5 日发布了 Claude Opus 4.6。如果你只看标题,会觉得这不过是又一次例行升级 — 跑分更高了,上下文更长了,价格没变。
但这次真正值得关注的,不是模型本身变强了多少,而是 Anthropic 悄悄改变了一个根本假设:AI 不再是一个人在干活了。
发生了什么
2026 年 2 月 5 日,Anthropic 发布 Claude Opus 4.6,同时推出一系列新功能。
先说硬指标:
- GDPval-AA(衡量知识工作能力的基准):超过 GPT-5.2 约 144 Elo,超过上代 Opus 4.5 约 190 Elo,对 GPT-5.2 的胜率约 70%
- Terminal-Bench 2.0(agentic coding 基准):业界最高分
- Humanity's Last Exam(多学科推理):领先所有前沿模型
- BigLaw Bench(法律领域):90.2%
- MRCR v2(百万 token 大海捞针):76% 准确率 — 同场景下 Sonnet 4.5 只有 18.5%
数字很好看。但说实话,如果你关注 AI 行业超过六个月,你应该已经对"跑分又破纪录"这件事免疫了。Nathan Lambert 在 Interconnects 的分析说得很直白:我们已经进入了"后基准测试时代" — 跑分的微小差异根本无法预测真实使用中的体验差别。
所以,跑分放一边。聊点真正重要的。
真正的信号:从"一个 AI"到"一群 AI"
Agent Teams:AI 有队友了
这是 Opus 4.6 发布中最被低估的变化。
过去你用 Claude Code 干活,是一个 agent 从头到尾串行执行。遇到大项目 — 比如审查一个几万行的代码库 — 它就像一个实习生被扔进了巨型仓库,一个文件一个文件地啃。
现在,Claude Code 支持 Agent Teams。你可以把一个大任务拆成多个子任务,分配给多个 agent,它们并行工作、自主协调。
设计很务实,没有花哨的 demo 味:
- 最适合独立、读多写少的任务(代码审查、架构分析、codebase 探索)
- 通过
Shift+Up/Down或 tmux 控制子 agent - 每个 agent 有自己的上下文,互不干扰
听起来像什么?团队分工。
这不是效率优化,这是范式转变。从"AI 是一个很强的工具"变成"AI 是一个能协作的团队"。类比一下:Excel 让一个人能做财务分析,但真正改变公司运作方式的是 ERP 系统 — 让一群人在同一套逻辑下协作。Agent Teams 走的是同一条路。
这也是目前国内外 AI 竞争中一个微妙的分水岭。国内大模型公司还在卷单模型指标 — 谁的 benchmark 更高、谁的上下文更长、谁的价格更低。Anthropic 已经在卷 agent 之间怎么协作了。维度不同了。
100 万 Token 上下文:终于能装下真实世界了
Opus 级别模型首次支持 1M token context window(上下文窗口,beta)。
100 万 token 是什么概念?大约相当于:
- 一整套《哈利·波特》全集(7 本)
- 一个中型 SaaS 产品的核心代码库
- 一家公司半年的会议记录
配合新增的 Context Compaction(上下文压缩) — 对话变长时,模型自动摘要旧的上下文,在不丢失关键信息的前提下延长有效工作时间 — 这意味着 AI 第一次有能力处理"真正的大项目",而不是"玩具大小的 demo"。
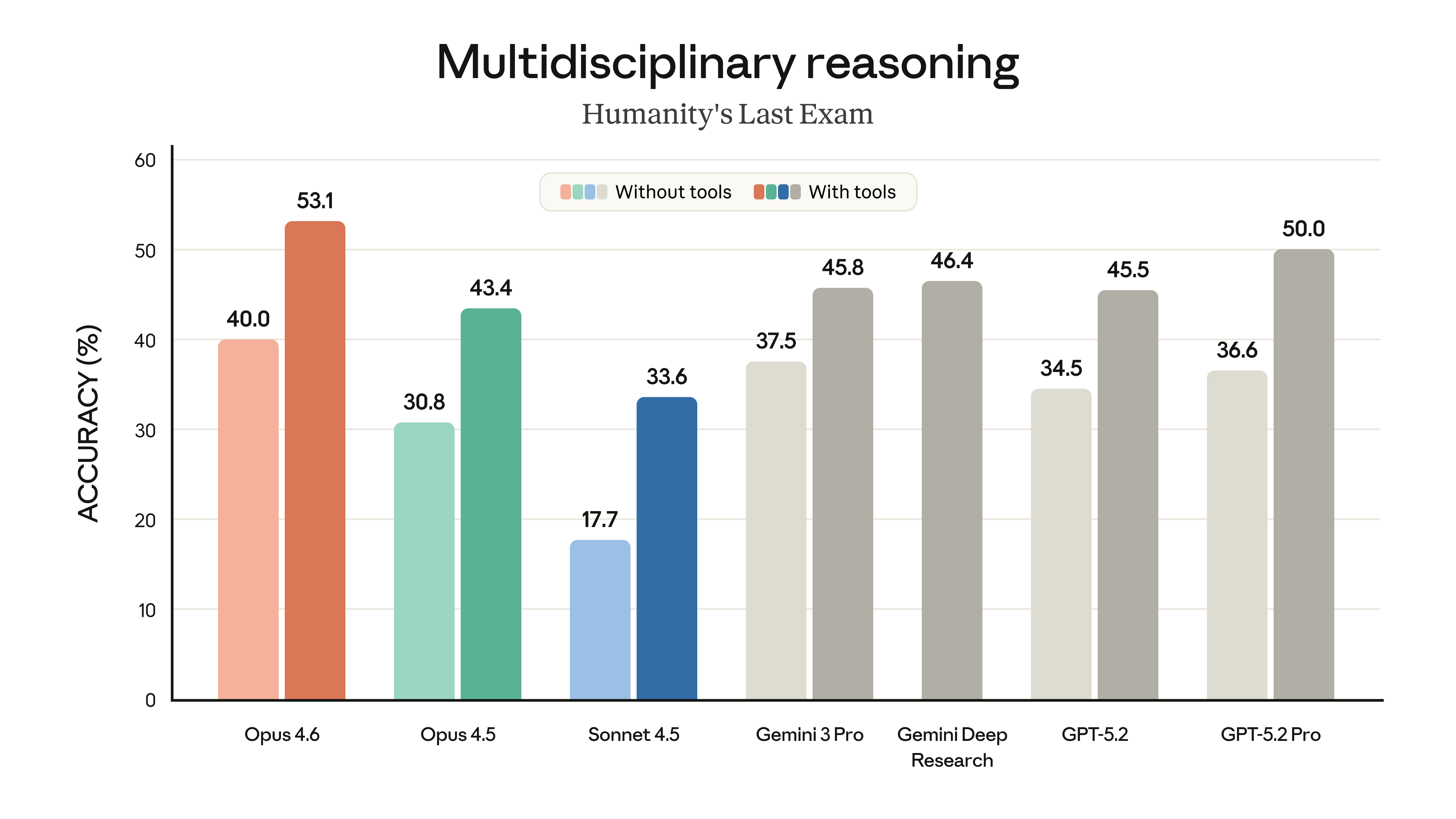
看那个大海捞针测试就知道了:在 100 万 token 里找 8 根"针",Opus 4.6 准确率 76%,Sonnet 4.5 只有 18.5%。不是量变,是质变。
顺便说一句,国内好几家模型也宣称支持百万 token,但实际的多针检索准确率很少公开。76% 这个数字,是个可以拿来对标的硬指标。
Adaptive Thinking:AI 学会了看菜下碟
第三个值得关注的功能是 Adaptive Thinking(自适应思考)。
以前的"思考模式"是二选一:深度思考(慢、贵)或不思考(快、便宜)。Opus 4.6 能自己判断什么时候需要深度推理,什么时候快速回答就够了。你也可以手动设四个档位:low、medium、high(默认)、max。
这解决了一个实际痛点:你不想为"帮我改个变量名"付出深度推理的成本,也不想在"帮我分析竞品商业模式"时得到一个敷衍的回答。现在模型自己能分辨轻重。
背后的设计哲学比功能本身更值得关注:Anthropic 不只是在做更强的模型,而是在做更聪明的资源分配。 知道什么时候该省力,本身就是一种智能。这个思路对 API 成本控制的意义很大 — 目前很多 AI 产品要么永远全力输出(烧钱),要么只有一个档位(没得选),Adaptive Thinking 提供了第三条路。
市场的反应:恐惧与兴奋并存
Opus 4.6 发布后,"claude 4.6" 的搜索趋势直接到了 Breakout — Google Trends 的说法,意味着增长超过 5000%。
但更有意思的是发布前两天的事:2 月 3 日,美国软件和服务类股票遭遇了 2850 亿美元的抛售。多家媒体分析称,投资者担心 AI 工具会颠覆传统企业软件市场。
时间点不是巧合。当 AI 从"帮你写代码"进化到"帮你管理一个项目",受威胁的不再是程序员 — 而是整个软件行业的商业模式。
Notion、GitHub、Replit、Asana、Cognition 等 15 家以上公司第一时间表态支持 Opus 4.6。有意思的是,它们既是合作伙伴,也是潜在的被颠覆者。支持得越积极,说明越怕被甩下车。
用户端?涌入太多,Claude 服务一度过载。"Claude Code Down"、"Claude Status" 搜索词同步飙升。大概是 Anthropic 最甜蜜的烦恼。
定价没变 — 这本身就是信号
Opus 4.6 定价维持不变:25 per million tokens(输入/输出)。超过 200k token 的输入有溢价:37.50。
模型明显变强了,价格没涨。这说明推理效率在提升 — 或者说 Anthropic 愿意用利润换市场份额。在 GPT-5.2 和 Gemini 的竞争压力下,"更强但不更贵"是一个很有攻击性的定价策略。
对开发者来说结论很简单:升级不需要额外成本,没有理由不切。
一句话带走
Opus 4.6 的跑分很好看,但真正的故事是:Anthropic 正在把 AI 从"一个很强的助手"变成"一个能协作的团队"。 这不是下一个版本号的事 — 这是下一个时代的事。
你觉得 Agent Teams 会改变你的工作方式吗?还是说这只是又一个"听起来很酷但用不上"的功能?评论区聊聊。
关注本号,第一时间解读 Anthropic 最新动态。
