

想象一下,你寄送的重要快递被退回了,快递员不会直接丢弃,而是根据你的要求间隔几小时后重新投递,直到成功或达到最大投递次数。Apache DolphinScheduler的任务重试机制就是这种“智能重投”的调度系统版。
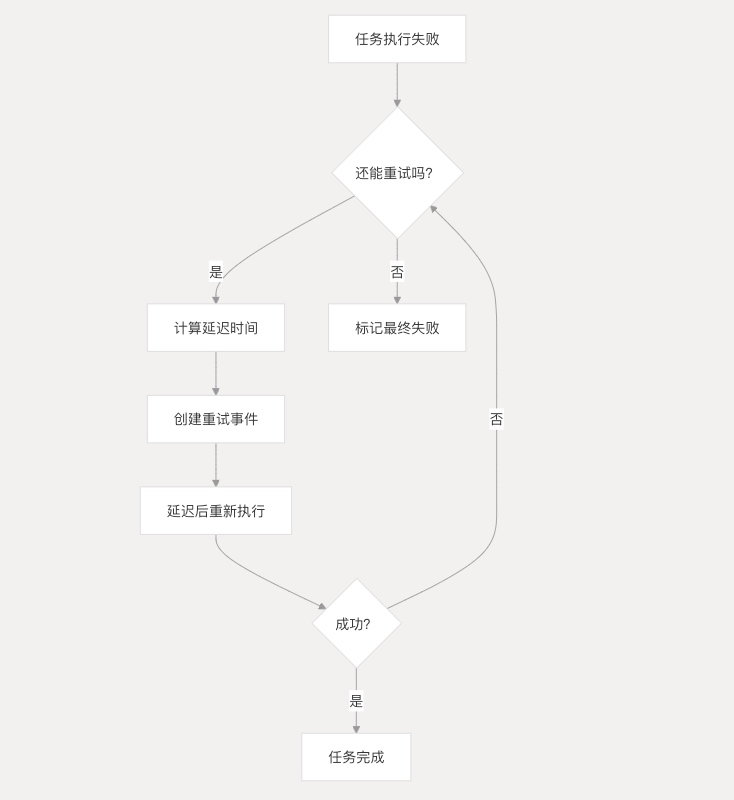
DolphinScheduler提供了完善的任务失败重试机制,支持业务任务节点在执行失败后自动延迟重试,直到成功或达到最大重试次数。该机制通过状态机驱动、事件发布和延迟队列实现,确保任务执行的可靠性。
核心机制:三步重试法
1. 失败时自动触发重试
当任务(如Shell脚本)执行失败时,系统会立即检查两个关键配置:
failRetryTimes:最多重试几次(默认0次)failRetryInterval:每次重试间隔几分钟
这些配置在任务创建时设定,前端表单会将其转换为JSON格式存储。
2. 智能延迟计算
系统不会立即重试,而是计算精确的延迟时间:
// 实际延迟 = 配置间隔 - (当前时间 - 任务结束时间)
long remainingTime = TimeUnit.MINUTES.toMillis(delayTime)
+ System.currentTimeMillis()
- taskInstance.getEndTime().getTime();
这确保无论任务何时失败,都能保持固定的重试间隔。
3. 状态机驱动重试
重试过程由状态机精确控制:
- 失败状态:收到失败事件后,检查是否还能重试
- 重试状态:创建新的任务实例(保持首次提交时间不变)
- 重新执行:发布启动事件,任务重新进入调度队列
关键特性:哪些任务能重试?
✅ 支持重试的业务节点
- Shell脚本任务
- SQL查询任务
- Spark计算任务
- 所有实际执行代码的任务 5
❌ 不支持重试的逻辑节点
- 条件分支节点
- 子流程节点
- 依赖检查节点 这些节点只控制流程走向,不执行具体代码 5 。
实战验证:测试案例
集成测试展示了完整的重试过程:
- 任务A首次失败(retryTimes=0)
- 系统自动重试1次(retryTimes=1)
- 两次任务实例保持相同的firstSubmitTime
- 最终失败后工作流停止 6 。
特殊场景处理
依赖任务等待
如果任务B依赖任务A,当A失败但未达最大重试次数时,B会进入等待状态而非直接失败 7 。
手动干预能力
即使任务正在等待重试,你仍可以:
- 暂停任务(取消后续重试)
- 终止任务(强制停止) 系统会优雅地处理这些中断请求 8 。
容错 vs 重试:重要区别
- 任务重试:任务代码执行失败后的自动重试
- Worker容错:当Worker服务器宕机时,Master接管并重新调度任务(包括Yarn任务) 9
运维建议
- 合理设置重试间隔:避免过于频繁的重试导致系统压力
- 区分任务类型:为关键任务设置更多重试次数
- 监控重试指标:关注retryTimes字段,识别不稳定任务
- 理解逻辑节点限制:不要期望条件分支会自动重试
总结
Apache DolphinScheduler的重试机制就像一个尽职的调度员,在任务失败时不会轻易放弃,而是按照你的要求智能地重新尝试。通过状态机精确控制、延迟计算和事件驱动架构,确保了分布式环境下任务执行的可靠性。记住:只有真正执行代码的业务节点才能享受这种“重投”服务,而逻辑节点则需要你手动处理异常情况。
Notes
- 重试间隔以分钟为单位,实际延迟计算会扣除任务已结束的时间
- 每次重试会创建新的TaskInstance记录,但保持firstSubmitTime不变
- Worker宕机触发的容错重试与任务失败重试是两种不同的机制
- 逻辑节点(如子流程)不支持自动重试,需要手动干预
