

Grok 4.20 beta1 刚在 Arena 上交出了一份让人意外的成绩单:Search Arena 直接登顶第一,Text Arena 排到第四,仅次于 Claude Opus 4-6 和 Gemini 3.1 Pro。更有意思的是,这还只是它的「单 agent」模式——要知道 Grok 4.20 的核心卖点是 4 个 agent 并行推理。

搜索能力:一出场就是第一
Arena.ai 是目前最受认可的 AI 模型盲测排行榜之一,用户在不知道模型身份的情况下对比两个模型的回答,投票选出更好的那个。这种「盲品」机制比跑 benchmark 更接近真实使用体验。
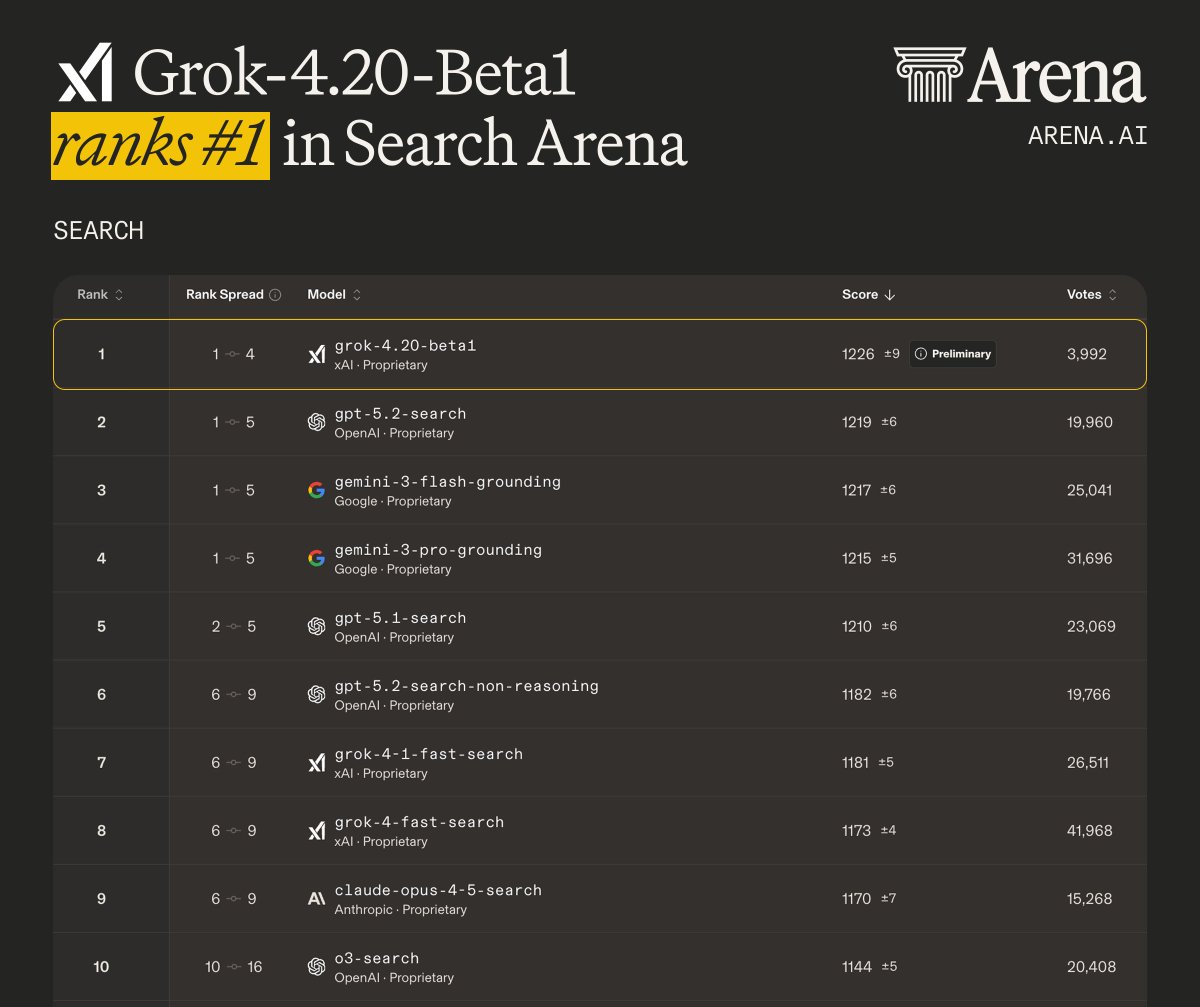
在 Search Arena 排行榜上,Grok-4.20-beta1 以 1226 分拿下第一,领先第二名 GPT-5.2-search 的 1219 分,也超过了 Google 自家的 Gemini-3-flash-grounding(1217 分)和 Gemini-3-pro-grounding(1215 分)。
这个排名有几个值得注意的点:
- 这是一个 beta 版本,投票数只有约 4000 票,标注了「Preliminary」。相比之下,GPT-5.2-search 有近 2 万票,Gemini-3-flash-grounding 有 2.5 万票。随着投票数增加,排名可能会波动
- Grok 测试的是「single agent」模式,也就是关掉了它标志性的多 agent 协作。如果开启 4-agent 模式,表现可能还会不一样
- xAI 在搜索榜上还有 grok-4-1-fast-search(第 7)和 grok-4-fast-search(第 8),说明搜索能力一直是 xAI 重点投入的方向
文本能力:挤进前四
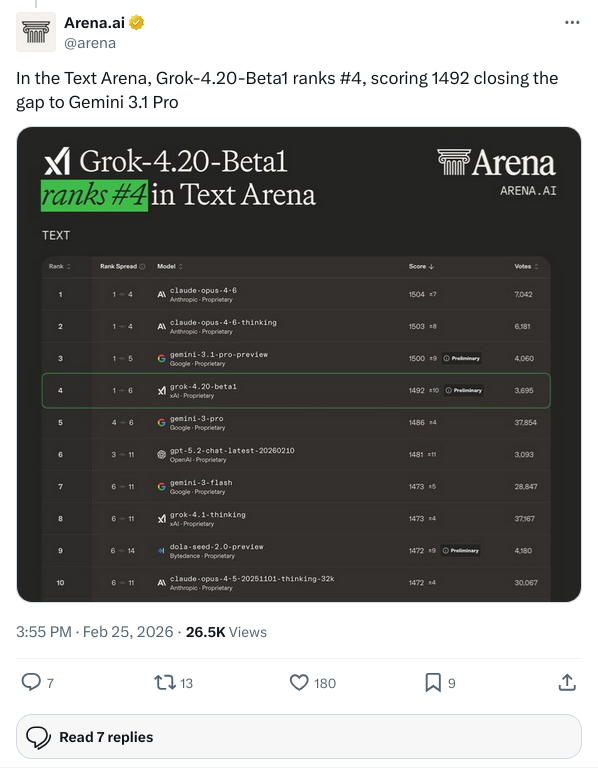
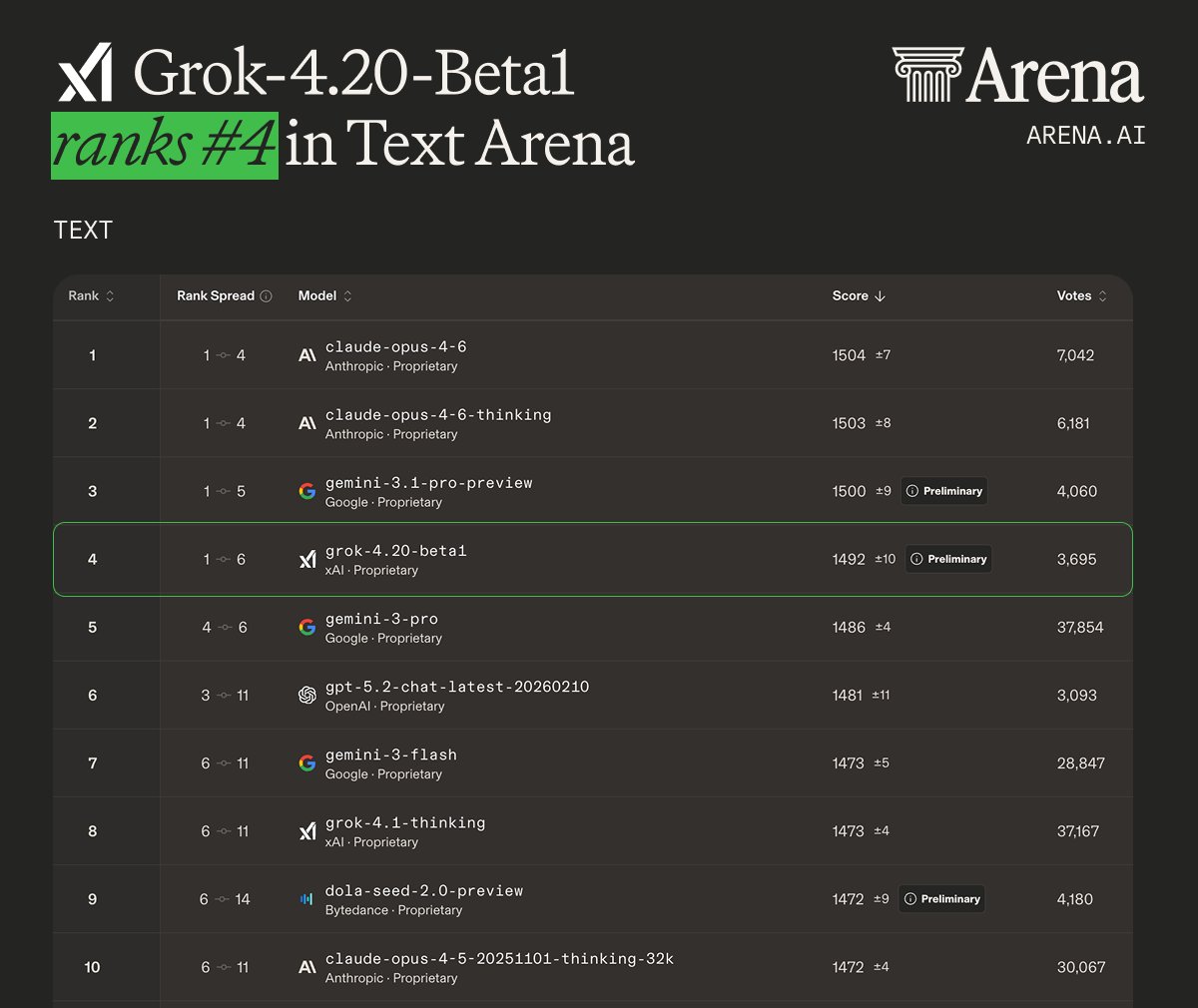
Text Arena 的竞争更激烈。Grok-4.20-beta1 以 1492 分排在第四,前三名分别是 Claude Opus 4-6(1504 分)、Claude Opus 4-6-thinking(1503 分)和 Gemini 3.1 Pro Preview(1500 分)。
从排行榜能看出当前 AI 模型的格局:
| 排名 | 模型 | 分数 | 厂商 |
|---|---|---|---|
| 1 | claude-opus-4-6 | 1504 | Anthropic |
| 2 | claude-opus-4-6-thinking | 1503 | Anthropic |
| 3 | gemini-3.1-pro-preview | 1500 | |
| 4 | grok-4.20-beta1 | 1492 | xAI |
| 5 | gemini-3-pro | 1486 | |
| 6 | gpt-5.2-chat-latest | 1481 | OpenAI |
Anthropic 的 Claude 系列稳坐前两把交椅,Google 的 Gemini 3.1 Pro 紧随其后,Grok 4.20 beta1 插在 Gemini 3.1 Pro 和 Gemini 3 Pro 之间。OpenAI 的 GPT-5.2 反而排到了第六,这个位置多少有点尴尬。
四大 AI 厂商的排名格局正在被打破——xAI 不再是「追赶者」,而是开始在特定领域领跑了。
4-agent 架构:Grok 4.20 的真正杀手锏

Grok 4.20 最大的技术亮点不是某个 benchmark 分数,而是它的原生多 agent 架构。
传统的大模型是一个「大脑」处理所有任务。Grok 4.20 换了个思路:4 个专业化的 agent 并行工作,各司其职:
- Coordinator(协调者):负责任务分解和结果整合
- Researcher(研究者):负责信息检索和事实核查
- Engineer(工程师):负责逻辑推理和代码生成
- Creator(创作者):负责创意内容和表达优化
这四个 agent 不是简单的流水线,而是真正的并行协作——它们会同时处理同一个问题,互相交叉验证,通过内部「讨论」达成共识后再输出最终结果。
这种设计的好处很直接:减少幻觉。当一个 agent 编造了某个事实,其他 agent 在交叉验证时就能发现问题。用社区里一个评论的话说:「未来的推理不是靠更大的脑子,而是靠更好的委员会。」
但这次 Arena 测试用的是 single agent 模式,也就是说排行榜上的成绩是「一个人单打独斗」的结果。这反而让人更好奇:如果开启完整的 4-agent 模式,Grok 4.20 能到什么水平?
社区怎么看
Arena 推文下面的评论区挺有意思,大致分成几派:
看好派认为 xAI 的迭代速度太快了。Grok 4.20 beta 是 2 月 17 号发布的,到现在才一周多就登顶搜索榜。而且 xAI 承诺每周更新,这种「快速迭代」的节奏在大模型领域很少见。
务实派更关注实际体验。有用户说用 Grok 搜索信息「感觉像超能力」,基本不再用 Google 了,尤其是找那些比较冷门的论文和引用。也有人说 Grok 4.20 在写小说大纲方面比 Gemini 3.1 好用,已经退订了 Gemini。
质疑派则指出几个问题:Arena 排名的投票数还太少(不到 4000 票),结论可能不稳定;排行榜成绩和实际使用体验之间往往有差距;而且 Grok 在编程能力方面的表现还没有被充分测试。
说实话,4000 票的 Preliminary 数据确实需要谨慎对待。但即便打个折扣,Grok 4.20 能在搜索领域和 GPT-5.2、Gemini-3 掰手腕,这件事本身就够说明问题了。
更大的图景

把视角拉远一点,Grok 4.20 的 Arena 成绩反映的是整个 AI 行业的一个趋势:顶级模型之间的差距在快速缩小。
Claude Opus 4-6 在 Text Arena 排第一,1504 分;Grok 4.20 beta1 排第四,1492 分。差距只有 12 分。Search Arena 更夸张,前四名挤在 1215-1226 分的 11 分区间里。
这意味着什么?模型选择的决策因素正在从「谁更聪明」转向「谁更便宜、谁更快、谁的生态更好」。当所有模型都足够聪明的时候,价格、延迟、API 易用性、生态集成这些「非智力因素」会变得越来越重要。
xAI 在这方面有一个独特优势:它和 X(Twitter)深度绑定。Grok 能直接访问 X 上的实时信息流,这在搜索场景下是一个天然的数据护城河。Search Arena 登顶,可能跟这个数据优势有直接关系。
xAI 的商业化节奏也挺值得聊聊。2 月初 xAI 被 SpaceX 收购,1 月底刚完成 200 亿美元的 E 轮融资。有了 SpaceX 的资源加持和充足的资金,xAI 的迭代速度可能还会加快。
总结
- Grok 4.20 beta1 在 Search Arena 登顶第一,领先 GPT-5.2 和 Gemini-3
- Text Arena 排第四,仅次于 Claude Opus 4-6 和 Gemini 3.1 Pro
- 以上成绩还是 single agent 模式,4-agent 完整模式的表现值得期待
- 顶级模型之间的差距在快速缩小,竞争焦点正在从「智力」转向「生态和体验」
参考链接
- Arena.ai 排行榜:lmarena.ai/leaderboard
- xAI 官方新闻页:x.ai/news
- Arena.ai 官方推文:x.com/arena/statu…
