

你有没有遇到过这样的场景:线上业务高峰时,一条简单的查询突然拖慢了整个系统,看监控发现 MySQL 在疯狂做全表扫描,CPU 和 IO 直接拉满?其实,90% 的慢查询问题,根源都在索引 —— 要么是没建对,要么是用错了。今天咱们说说MySQL 索引设计和创建的5条黄金准则,从底层原理到实战准则,再到最容易踩的坑,让你的查询真正飞起来嘛。
一、首先搞懂索引到底为啥能提速?
要用好索引,得先知道它的底层逻辑。InnoDB 引擎的索引用的是B + 树结构,和 B 树比起来,它把数据都存在叶子节点,还把叶子节点用双向链表连了起来,这就带来两个核心优势:
- 一是非叶子节点只存键值,同一层级能放下更多索引项,树的高度更低,磁盘 IO 次数就更少;
- 二是叶子节点的双向链表让范围查询、排序查询的效率直接拉满。
你看,没有索引的时候,MySQL 要从磁盘里逐行读数据,这就是全表扫描,数据量一大,IO 开销就非常恐怖了。而有了索引之后,就像查字典的目录,先通过 B + 树快速定位到数据所在的磁盘页,再把整页数据读到内存里,这一下就把查询的时间复杂度从 O (N) 降到了 O (logN),速度自然就上来了。当然了,索引也不是万能的,它会占用额外的磁盘空间,还会拖慢插入、更新、删除的速度,所以建索引必须讲策略,不能乱建。
二、索引设计与创建的 5 条黄金准则
1. 选择性优先:选区分度高的列
索引的选择性,指的是列中不同值的数量和总行数的比值,比值越接近 1,区分度越高,索引的效率就越好。比如身份证号的选择性是 1,几乎每条数据都不一样,用来建索引最合适;但性别列只有男女两个值,选择性极低,建了索引也没啥用,MySQL 大概率还是会走全表扫描。 你可以用这条 SQL 计算列的选择性:
SELECT
COUNT(DISTINCT column_name) * 1.0 / COUNT(*) AS selectivity,
COUNT(DISTINCT column_name) AS distinct_values,
COUNT(*) AS total_rows
FROM table_name;
2. 最左前缀原则:复合索引的核心
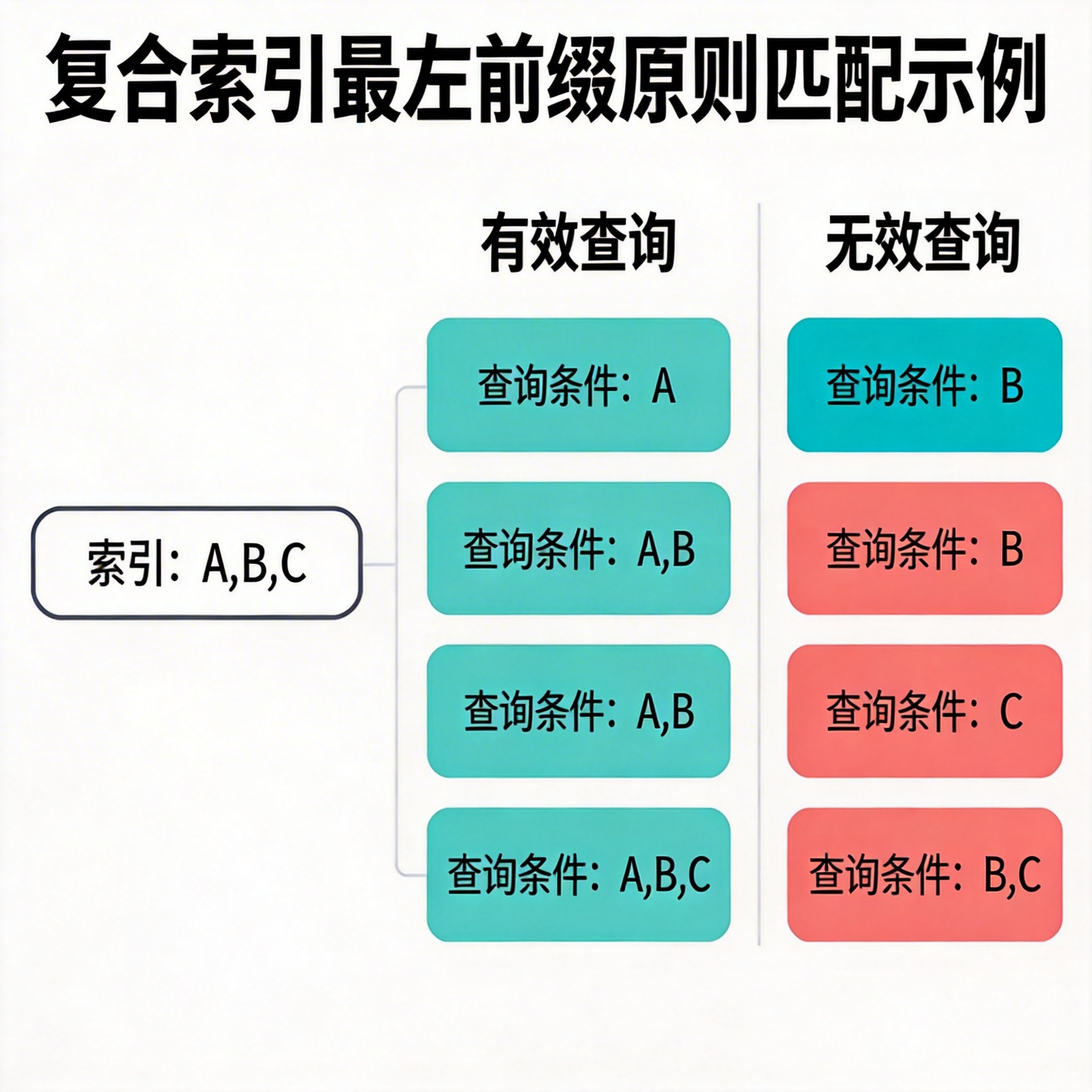
复合索引是多列组合的索引,比如INDEX(a,b,c),它的匹配规则是必须从最左边的列开始连续匹配,支持a、a,b、a,b,c这三种查询条件,但如果直接查b或者b,c,索引就完全失效了。所以创建复合索引时,要把查询频率最高、区分度最高的列放在最左边,比如用户表的查询经常是name+age,那索引就该建(name,age),而不是反过来。
3. 覆盖索引:减少回表的关键
当索引包含了查询需要的所有字段时,就不用再回原表去查数据了,这就是覆盖索引。比如你查SELECT id,name FROM users WHERE name='张三',如果建了INDEX(name,id),那直接从索引里就能拿到所有数据,省掉了一次磁盘 IO,性能能提升 5 到 20 倍呢。设计查询语句时,尽量别用SELECT *,只查需要的字段,更容易触发覆盖索引。
4. 短索引原则:用前缀索引省空间
对于字符串类型的列,比如邮箱、手机号,如果整个字段很长,建索引会占用大量磁盘空间,这时可以用前缀索引,比如INDEX(email(20)),只取邮箱的前 20 个字符建索引。当然了,前缀长度得选好,要保证前缀的选择性和整个列的选择性差不多,别因为省空间导致索引失效,这就得结合业务实际测试了。
5. 适度原则:索引不是越多越好
很多同学觉得索引建得越多,查询就越快,其实这是不对的。一般而言每个表建 3 到 5 个优质索引就够了,索引太多的话,不仅会占用大量磁盘空间,每次插入、更新数据时,MySQL 都要更新所有相关的索引,这会让写操作的速度大幅下降。而且 MySQL 的查询优化器在选择索引时,还要遍历所有索引,反而会增加查询的耗时。
其实用好 MySQL 索引,核心就是一句话:在合适的列上,建合适的索引,用正确的姿势查询。别为了图方便乱建索引,也别因为不了解规则导致索引失效。只要把这些准则吃透,避开那些常见的坑,你的查询速度肯定能上来,数据库的并发性能也会提升一大截。
最后问一句,你在实际业务中遇到过最头疼的索引问题是什么?欢迎在评论区留言讨论。
