

GLM-5:智谱新一代旗舰基座模型
【局限性】当前模型刚更新出来,官方限制并发为1,超过直接就被拒绝了。然后模型返回cluade的问题官方说是估计做了模型混淆的结果。
2026年2月,智谱AI发布了新一代旗舰基座模型——GLM-5。与前代产品相比,GLM-5在模型规模、训练数据和算法架构上都有显著升级,特别是在 Coding 和 Agent 能力上取得了开源 SOTA(State-of-the-Art)表现。
根据智谱AI官方文档介绍,GLM-5 专门面向 Agentic Engineering 打造,能够在复杂系统工程与长程 Agent 任务中提供可靠生产力。
核心规格
| 项目 | 参数 |
|---|---|
| 定位 | 旗舰基座模型 |
| 输入模态 | 文本 |
| 输出模态 | 文本 |
| 上下文窗口 | 200K tokens |
| 最大输出 tokens | 128K |
技术亮点
更大基座,更强智能
GLM-5 在模型规模上实现了显著扩展:
- 参数规模:从 355B(激活 32B)扩展至 744B(激活 40B)
- 预训练数据:从 23T 提升至 28.5T
- 算力投入:更大规模的预训练算力显著提升了通用智能水平
异步强化学习框架
智谱AI构建了全新的"Slime"框架,支持更大模型规模及更复杂的强化学习任务。通过异步智能体强化学习算法,模型能够持续从长程交互中学习,充分激发预训练模型的潜力。
稀疏注意力机制
GLM-5 首次集成了 DeepSeek Sparse Attention,在维持长文本效果无损的同时,大幅降低模型部署成本,提升 Token Efficiency。
核心能力
GLM-5 支持以下核心能力:
- 思考模式:提供多种思考模式,覆盖不同任务需求
- 流式输出:支持实时流式响应,提升用户交互体验
- Function Call:强大的工具调用能力,支持多种外部工具集成
- 上下文缓存:智能缓存机制,优化长对话性能
- 结构化输出:支持 JSON 等结构化格式输出,便于系统集成
- MCP:可灵活调用外部 MCP 工具与数据源,扩展应用场景
性能表现
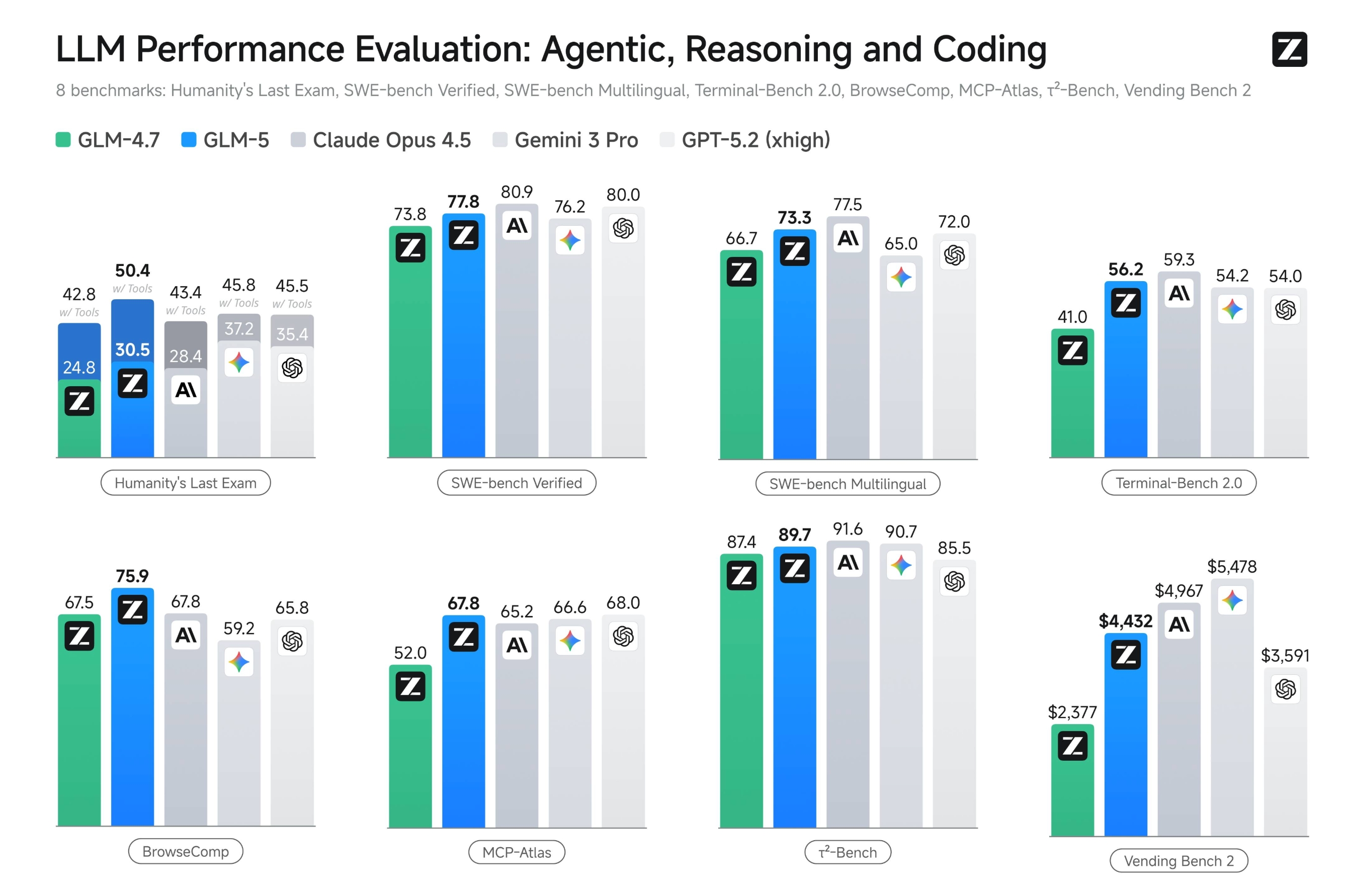
Coding 能力
据智谱AI官方文档,GLM-5 在编程能力上实现了对 Claude Opus 4.5 的对齐,在业内公认的主流基准测试中取得开源模型最高分数:
- SWE-bench-Verified:77.8 分
- Terminal Bench 2.0:56.2 分
两项成绩均为开源模型最高分数,性能表现超过 Gemini 3.0 Pro。
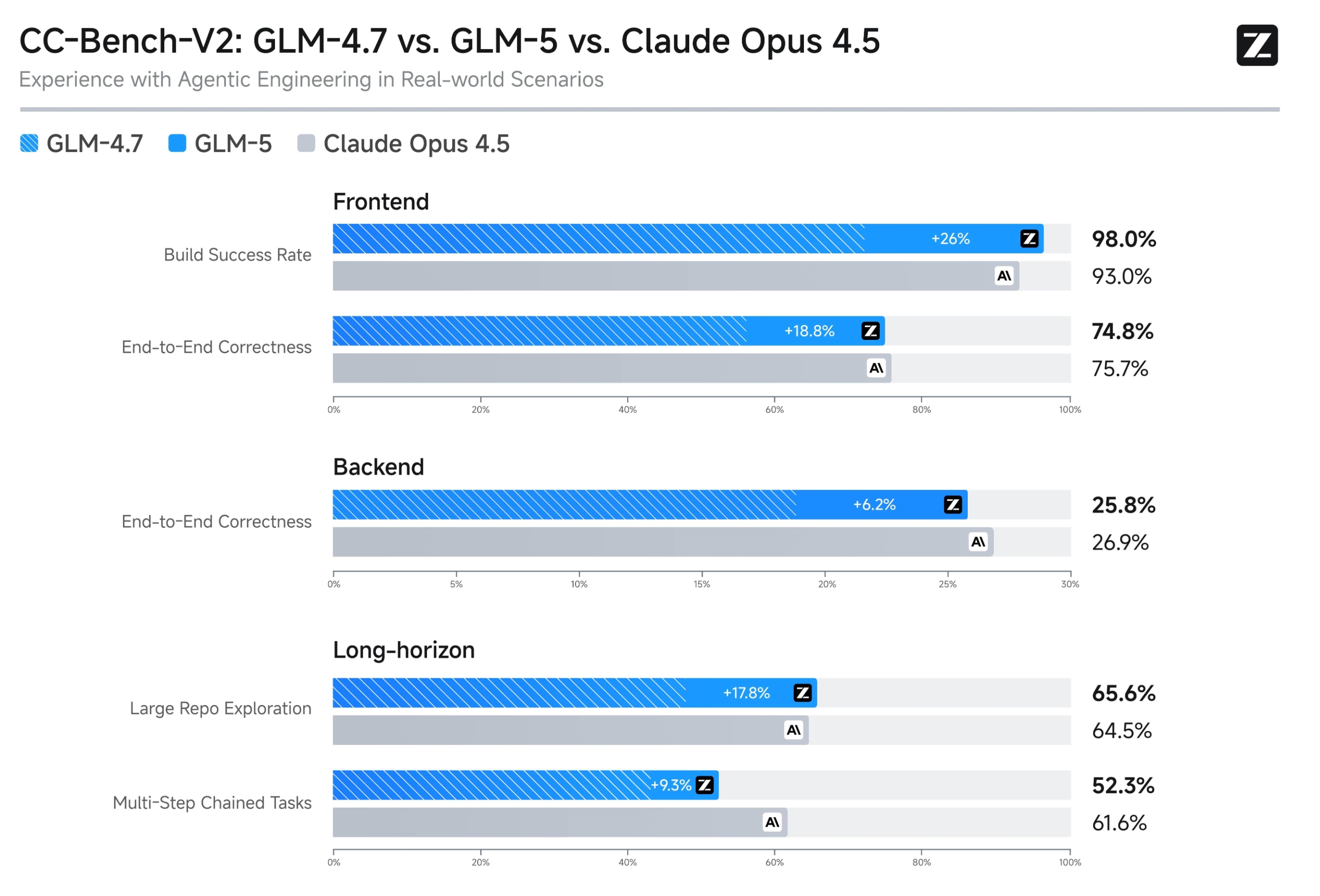
在内部 Claude Code 评估集合中,GLM-5 在前端、后端、长程任务等编程开发任务上显著超越 GLM-4.7,能够以极少的人工干预自主完成 Agentic 长程规划与执行、后端重构和深度调试等系统工程任务。
Agent 能力
GLM-5 在 Agent 能力上实现开源 SOTA,在多个评测基准中取得开源第一:
- BrowseComp(联网检索与信息理解)
- MCP-Atlas(工具调用和多步骤任务执行)
- τ²-Bench(复杂多工具场景下的规划和执行)
这些能力是 Agentic Engineering 的核心:模型不仅要能写代码、完成工程,还要能在长程任务中保持目标一致性、进行资源管理、处理多步骤依赖关系。
应用场景
根据智谱AI官方文档,GLM-5 适用于以下场景:
Agentic Coding
能基于自然语言自动生成可运行代码,覆盖前后端与数据处理等开发环节,显著缩短从需求到产物的迭代周期。
智能体任务
具备自主决策与工具调用能力,可在模糊复杂目标下完成从理解、规划到执行与自检的全流程智能体任务,实现"一句话输入到完整交付物"。
办公场景
通过强大的长程规划与记忆能力,能够稳定完成跨阶段、多步骤、强逻辑关联的复杂办公任务,确保指令遵循度与目标一致性。
角色扮演(RolePlay)
能精准理解并持续保持角色设定,在叙事、情绪和逻辑上保持一致,实现自然、可演进的高沉浸式角色扮演体验。
剧本 / 分镜脚本生成
在长文本一致性与复杂人物塑造上大幅增强,可稳定输出可直接进入制作流程的高质量剧本内容。
翻译
能将正式文本准确转换为符合目标语言表达习惯的专业译文,实现语义、术语与表达的全面对齐。
文本数据提取
可从合同、公告、财报等复杂文本中精准抽取关键字段与逻辑关系,将原始内容稳定转化为可分析的结构化数据,助力企业数据治理与自动化。
信息质检
能精准识别客服工单等复杂文本中的关键信息并自动完成质检与风险识别,大幅提升运营效率。
