

你有没有想过,那些动辄千亿参数的大语言模型,其实每天都在做着重复劳动?它们像极了勤奋但笨拙的学生,每次遇到“苹果”这个词,都要从头推导一遍关于水果、公司、牛顿的关联——哪怕这个问题已经被问过千万次。
现在,这一切都要改变了。
当Transformer学会“走捷径”
传统的大模型运行方式,简直像一场永无止境的马拉松。每个词都要经过几十层注意力机制和全连接层的复杂计算,才能得出最终结果。这种设计让模型变得异常庞大,计算成本高得吓人。
但DeepSeek4团队想出了一个绝妙的主意:为什么不让模型学会“查字典”呢?
Engram技术就是这个想法的完美实现。它在Transformer架构中增加了一条“记忆检索路径”,让模型能够直接从庞大的嵌入表中获取静态的、局部的模式,而不是每次都从头推导。想象一下,你不再需要每次被问到“2+2等于几”时都重新计算,而是可以直接从记忆中调取答案——Engram让AI做到了同样的事情。
这个过程快得惊人。对于每个输入的词元,Engram会从规范化的词元ID中构建后缀N-gram(比如2-gram、3-gram),然后通过哈希函数在O(1)时间内从嵌入表中检索出相应的向量。检索成本保持恒定,即使嵌入表规模扩大到天文数字级别。
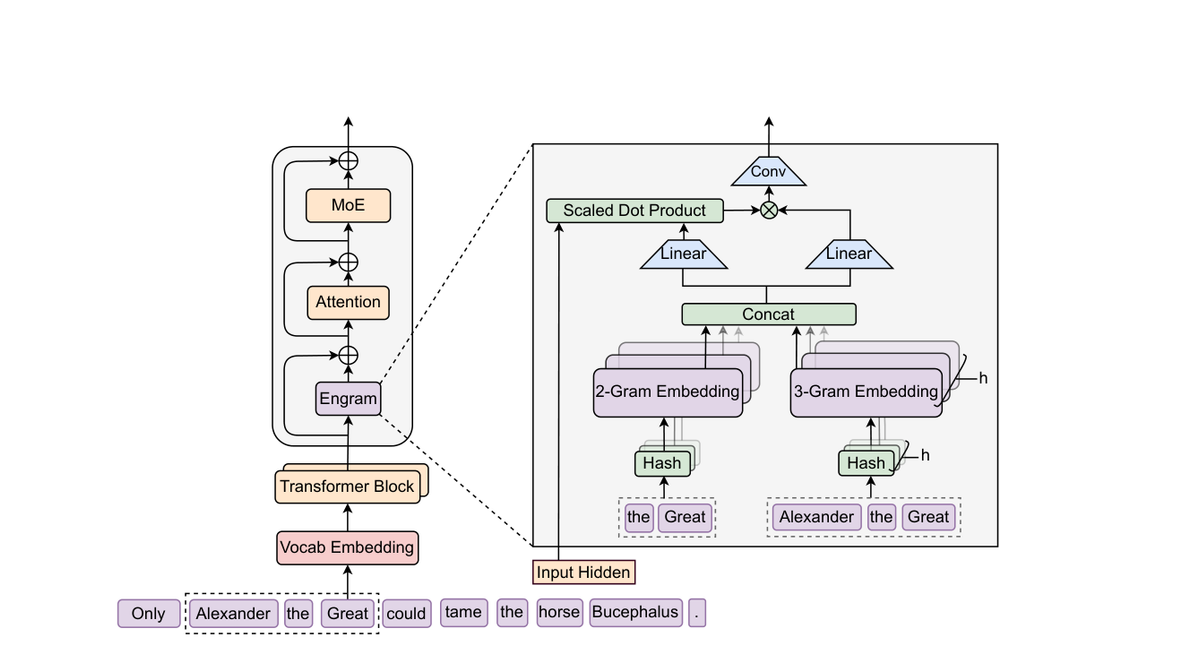
更聪明的是,Engram知道什么时候该相信记忆,什么时候该忽略它。它使用当前的隐藏状态作为上下文,通过一个sigmoid门控机制来决定检索到的记忆应该对当前词元产生多大影响。当记忆与上下文冲突时,门控值会趋向于零——这意味着模型不会盲目相信记忆,而是会做出明智的判断。
那个神奇的“最佳比例”
你可能以为,给模型增加越多的记忆能力就越好。但事实远比这有趣。
DeepSeek4团队发现了一个惊人的规律:在固定的参数和激活计算预算下,Engram与混合专家路由之间存在一个“甜蜜点”。他们尝试将稀疏预算的一部分从额外的专家重新分配到Engram的记忆表中,结果性能呈现出明显的U型曲线。
全部使用专家的设置并不是最优的。相反,将大约20%到25%的稀疏预算分配给Engram,让模型保持约75%到80%的专家路由比例时,验证损失达到了最低点。这个发现打破了“越多越好”的直觉,揭示了AI架构中微妙的平衡艺术。
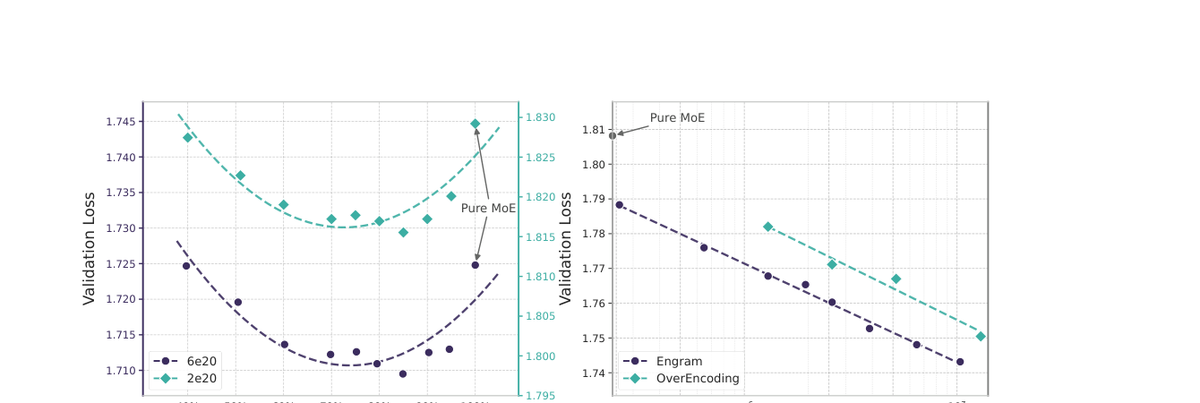
这种设计带来了意想不到的好处。Engram显著减少了早期层对静态模式的重建工作,让前面的层更早做好预测准备。这不仅提升了模型的整体效率,还改善了长上下文行为和推理能力——就好像给模型装上了“预处理器”,让它能更快地理解输入内容的核心。
记忆如何改变AI的思考方式
Engram的运作机制充满了精妙的设计细节。检索过程从将分词器ID压缩为规范形式开始,这使得文本上等价的变体映射到单个ID。这种规范化减少了有效词汇表的占用空间,然后Engram在最近的上下文中构建后缀N-gram。
每个N-gram顺序使用多个独立的哈希头,每个头索引自己的素数大小嵌入表以减少冲突。检索到的向量被连接成一个记忆向量,确保查找成本保持不变,即使表格规模不断扩大。
融合阶段更是展现了设计的精巧。记忆向量被投影为键和值向量,通过RMS归一化的隐藏状态与记忆键的缩放点积计算sigmoid门控。门控之后,一个短深度因果卷积会细化信号,然后将结果添加回残差流中。
这种设计让Engram不仅仅是简单的记忆查找表,而是一个智能的记忆管理系统。它知道什么时候该依赖记忆,什么时候该依靠计算;知道如何平衡速度与准确性;知道如何在不增加计算负担的情况下扩展知识容量。
这不仅仅是技术升级
Engram技术的意义远不止于提升模型效率。它代表了AI发展的一种新思路:不再盲目追求更大的参数规模,而是追求更智能的架构设计。
想象一下未来的AI应用场景。实时对话系统可以瞬间调取常见问题的答案,而不需要每次都进行复杂计算;代码生成工具可以记住常用的编程模式,直接套用而不是重新生成;教育AI能够快速检索知识点,提供更精准的解答。
这种改变是根本性的。Engram让AI从“每次都要重新学习”转向“学会利用已有知识”,这更接近人类的思维方式。我们不会每次看到苹果都重新学习它的所有属性——我们只是从记忆中调取相关信息,然后根据当前情境进行调整。
DeepSeek4的这项创新可能会引发连锁反应。其他研究团队很可能会跟进,开发出各种基于记忆检索的优化技术。AI的进化速度可能会因此再次加速,而我们作为用户,将享受到更快、更智能、更经济的AI服务。
技术的魅力就在于此——一个看似微小的架构改变,却能带来革命性的体验提升。Engram或许只是开始,但它已经为我们描绘了一个令人兴奋的未来:在那里,AI不仅更强大,而且更聪明、更高效、更贴近人类的思维方式。

那个未来,可能比我们想象的来得更快。
