

本文已收录在Github,关注我,紧跟本系列专栏文章,咱们下篇再续!
- 🚀 魔都架构师 | 全网30W技术追随者
- 🔧 大厂分布式系统/数据中台实战专家
- 🏆 主导交易系统百万级流量调优 & 车联网平台架构
- 🧠 AIGC应用开发先行者 | 区块链落地实践者
- 🌍 以技术驱动创新,我们的征途是改变世界!
- 👉 实战干货:编程严选网
为 Qoder 量身定制的强化学习模型
1 引言
为提升 Qoder 端到端编程体验而打造的定制模型——Qwen-Coder-Qoder。
基于 Qwen-Coder 基座,并紧贴 Qoder 的 Agent 框架、工具与场景进行了大规模强化学习训练。面向真实软件工程任务的评测集 Qoder Bench 上,任务解决率超过 Cursor Composer-1,尤其在 Windows 系统下的终端命令准确率方面,领先幅度达到 50%。
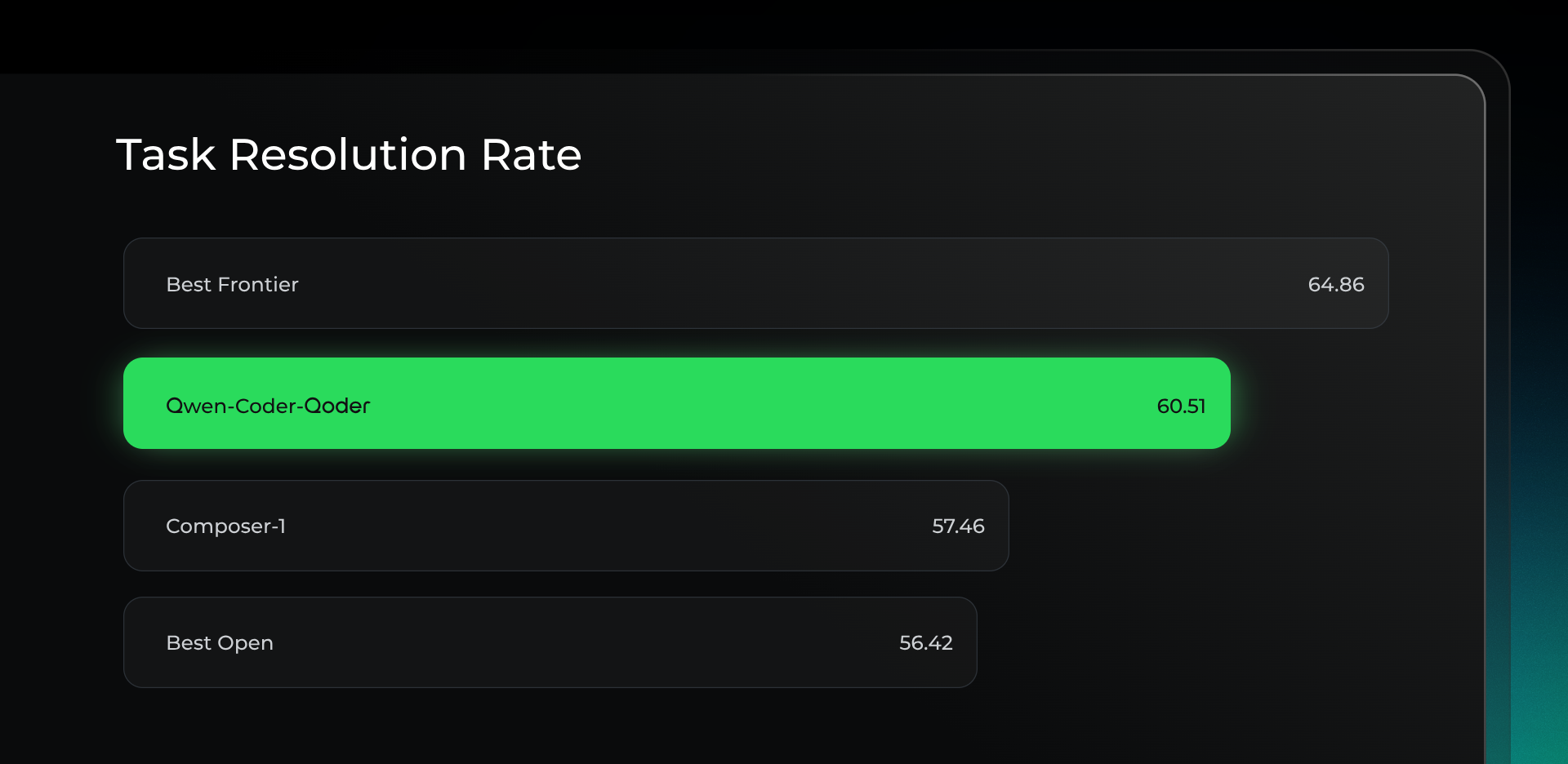
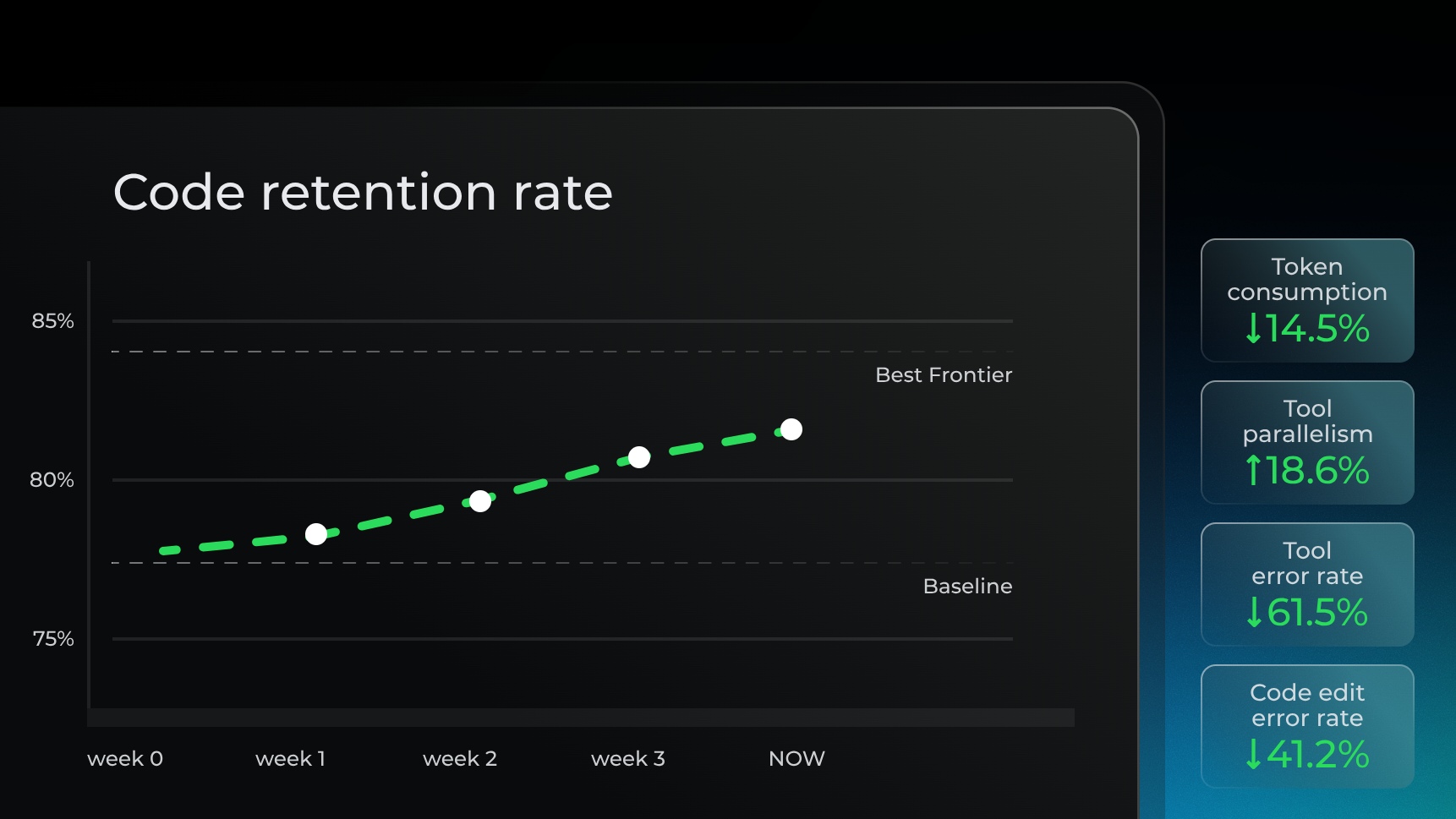
也为 Qoder 的线上用户体验带来了切实的、数据可证的提升。线上代码留存率提升 3.85%,工具异常率下降 61.5%,Token 消耗下降 14.5%,数据整体已接近世界顶级模型水平。
许多方面都展现出更接近资深开发者的"品味"和"思维"。一个优秀的 AI 编程伙伴,不仅要能解决问题,更要解决得漂亮、解决得地道。
- 遵循软件工程规范:许多通用模型在训练时以"解决问题"为唯一目标,倾向于"另辟蹊径",绕开现有框架。而 Qwen-Coder-Qoder 在训练中被引导去严格遵循工程规范,保持与项目一致的代码风格,确保代码质量。
- 理解完整项目上下文:通过学习 Qoder Agent 特有的工具和上下文数据(如代码图谱、项目记忆、Repo Wiki 等),Qwen-Coder-Qoder 能够从全局视角理解代码仓库,精准地使用工具完成任务。
- 高效的并行处理能力:它能够识别逻辑上无依赖关系的工具调用任务,并行执行代码检索、任务规划、多位置代码修改等操作,显著提升执行效率。
- 坚韧的问题解决能力:在面对复杂或棘手问题时,通用模型在多次失败后往往会放弃。而 Qwen-Coder-Qoder 则展现出更强的"开发者思维":持续尝试,直至问题解决。
2 "模型-智能体-产品"的智能进化体系
Qoder 智能进化体系的必然产物。
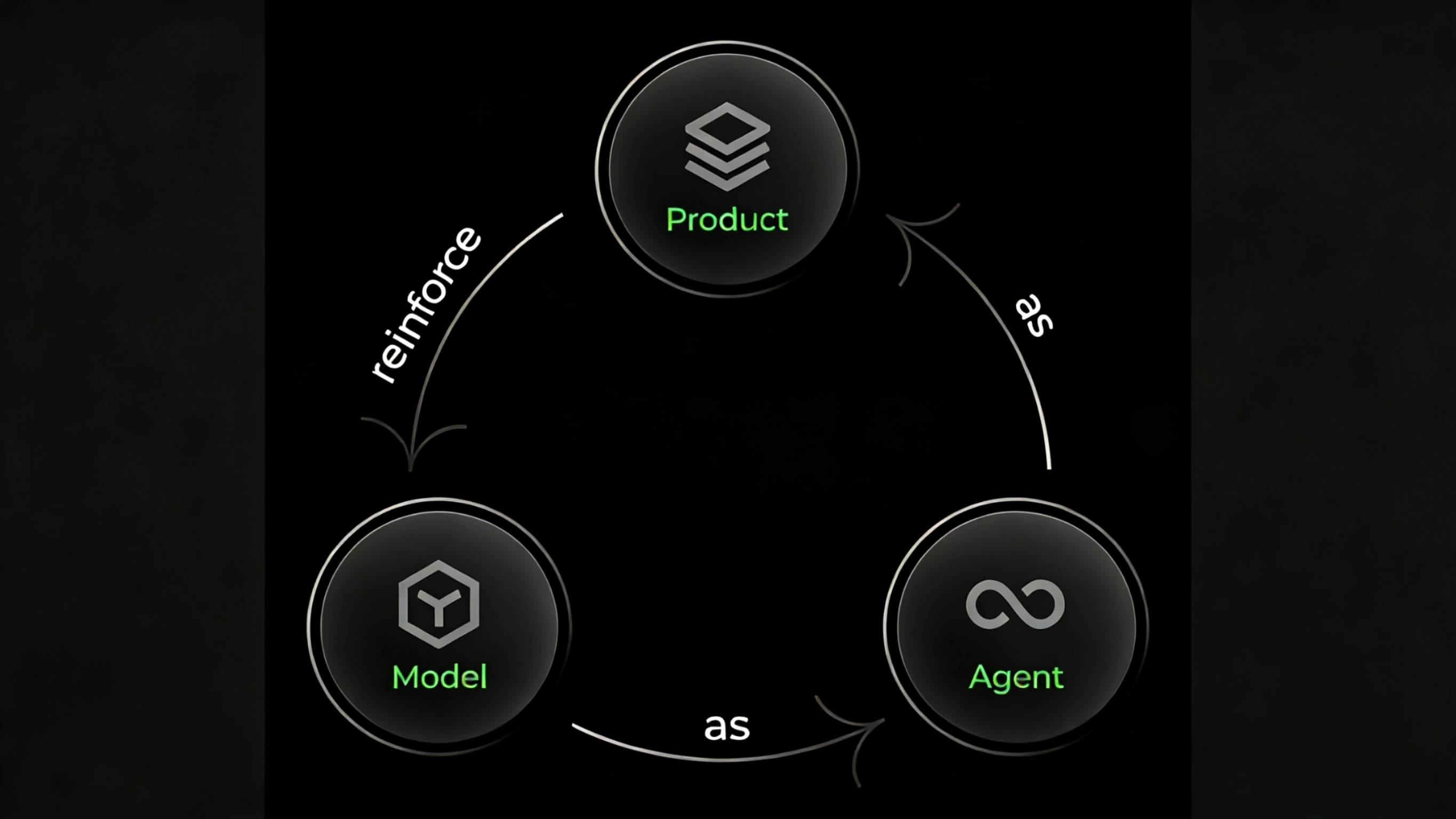
AI Coding正快速发展,着力构建"模型即 Agent,Agent 即产品,产品增强模型"的智能进化体系。模型是这一切基础,将 Qoder Agent 需要的各种能力都训练到 Qwen-Coder-Qoder,这个模型直接驱动 Agent 来执行任务。Agent 是核心,一切功能都围绕 Qoder Agent 展开。产品触达万千用户,可感知用户的真实行为和偏好,从中发掘出"软件工程的最佳开发实践"来作为奖励信号,增强模型的训练。
这形成了一个大模型软件工程智能的进化体系。Qwen-Coder-Qoder 正是基于真实产品环境、真实软件开发任务、真实软件开发奖励而训练的大规模强化学习模型。
3 实现
3.1 真实的 Qoder Agent 作为沙盒环境
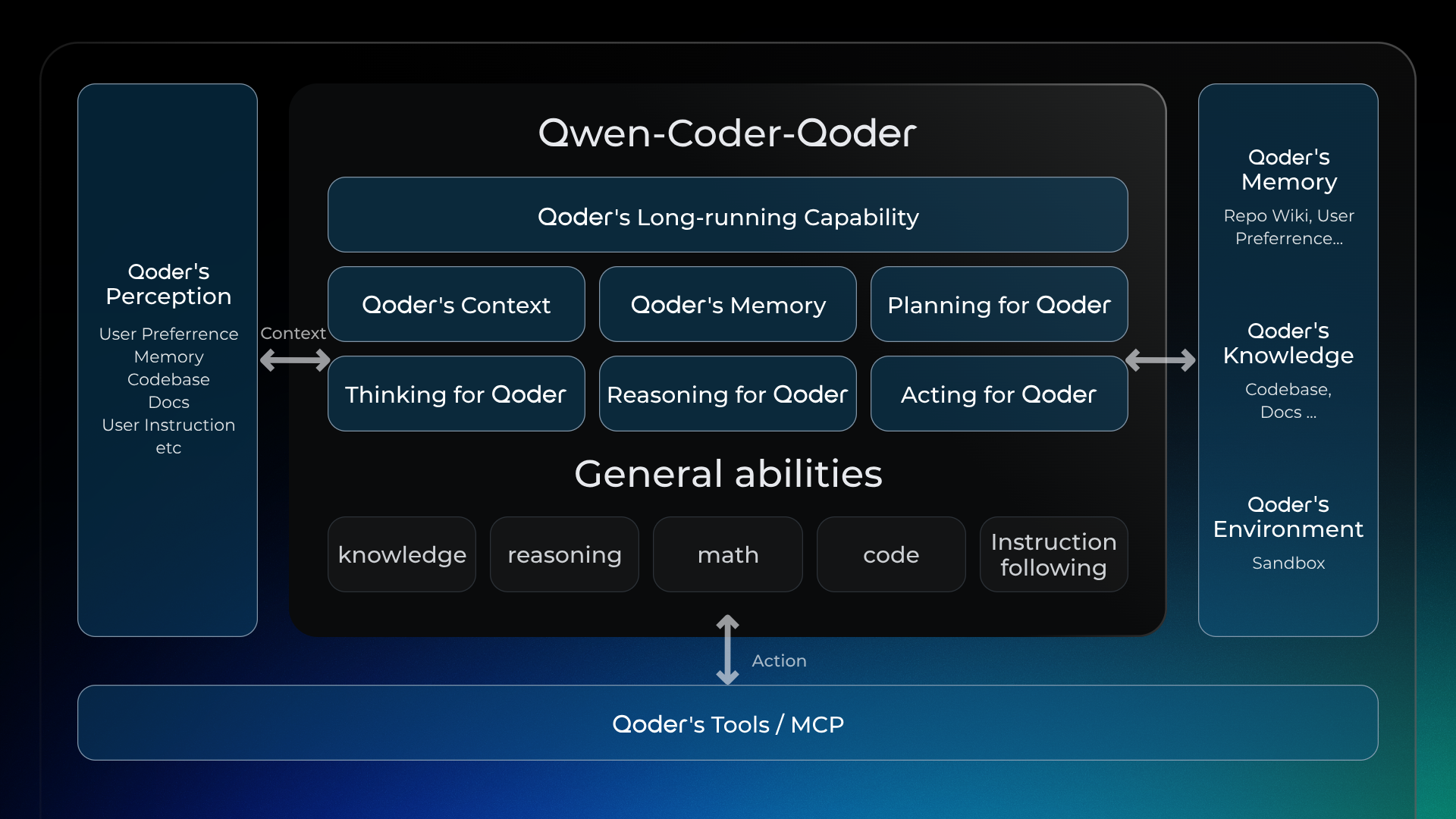
模型充分学习综合使用 Qoder 的 Knowledge、Memory、Tools/MCP、Context 等来解决真实编程任务,相比通用模型,我们的模型和产品能做到最好契合,随模型训练迭代演进,这种优势不断释放价值。还打造了一条完整的自动化可执行环境构建链路,产出大量真实项目的可执行环境。在训练过程中,依靠强大虚拟化容器技术,可快速拉起和销毁数万级别的容器,以满足大规模强化学习训练需求。
3.2 真实软件工程最佳实践作为奖励信号
Reward 在智能体训练中尤重要,我们启用了多种正确性的验证方式,包括单元测试验证、命令行验证、多维任务验证等,确保智能体正确解决问题。
还对过程做更多约束,确保变更符合软件工程规范,如:编码风格、复用性和耦合度等,使解决方案无论是方案思路、编码风格均与资深开发者对齐。
在 Reward 构建过程中,Reward Hacking 是绕不开的话题,如想提高模型并行度,如果只要并行调用就得到奖励,那模型为骗取奖励就会搜索大量不相关或弱相关文件,使并行度大幅提升,但对最终正确性没带来实质贡献。Reward Hacking就是与大模型强化学习"斗智斗勇",为此专门构建了一套 "Rewarder - Attacker" 对抗式审查机制,有效提升 Reward 系统构建的速度和健壮性。
3.3 大规模高效的强化学习训练框架
用 ROLL 训练,通过一系列系统级优化,让数千卡规模集群能够高效完成数千亿参数 MoE LLM 的 RL 后训练。在每轮包含 rollout 与 training 的流程中,rollout 往往占用 70% 以上时间。为提升端到端吞吐:
- 优化 rollout 阶段本身(异步调度减少等待、prefix/KV cache 复用消除冗余计算、冗余环境对抗长尾等)
- 优化 rollout–training 协同(放宽 on-policy 约束、支持跨版本样本生成、training 与 rollout 异步并行、等待时让渡 GPU 给 rollout 等)
综合这些优化,实际获得 10× 以上吞吐提升,显著缩短训练周期。
4 展望
模型即 Agent,Agent 即产品,产品增强模型的智能进化体系打造的初版模型。可见模型对整体端到端体验提升的潜力。
