

什么是 Apache Tika
Apache Tika™ 是 Apache 基金会维护的开源工具包,专注做一件事:通过单一接口检测并提取超过 1000 种文件类型的元数据和结构化文本 。 它不重复造轮子,而是将 Apache POI(Office)、PDFBox(PDF)、Tesseract(OCR)等成熟解析库封装成统一 API,让你“一次集成,全域覆盖”。
核心特性
- 格式覆盖广:支持 Office 全家桶、PDF、HTML、EPUB、Markdown,甚至 JPEG/MP4 等多媒体文件的元数据提取 Apache
- 三模式部署:
- 命令行(CLI):java -jar tika-app.jar --text file.pdf 快速试用
- 服务化(Server):REST API 供多语言调用
- Java 库:Maven 依赖直接集成到应用
- “结构化文本 + 元数据”一并输出:不仅是纯文本,还能拿到标题、作者、页数、Content-Type 等元信息
使用场景
企业搜索
为 Elasticsearch/Solr 提供统一的文档预处理管道,避免为每种格式写解析逻辑
文档管理系统
自动提取标题、作者、创建时间等元数据,实现智能分类与检索
数据湖入湖
将非结构化文档(合同、报告)转为可分析的文本流,喂给 NLP 模型
安全审计
检测文档中隐藏的元数据(如旧版本作者、GPS 位置),规避信息泄露风险
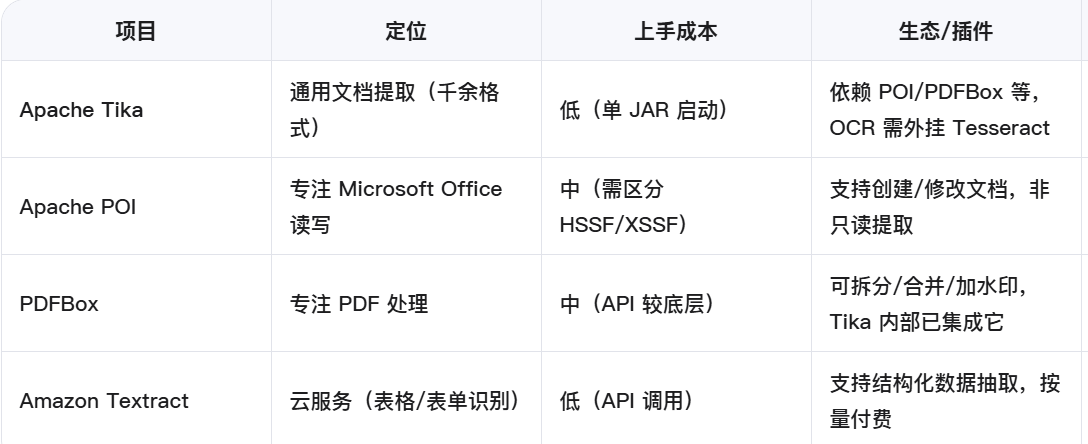
同类型对比
快速上手
从官网下载二进制(或 Maven 仓库 获取 jar),然后对文件抽纯文本:
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers-standard-package</artifactId>
<version>4.x.y</version>
</dependency>
import org.apache.tika.Tika;
Tika tika = new Tika();
String text = tika.parseToString(new File("document.pdf"));
System.out.println(text);
也可以
java -jar tika-app-*.jar --text document.pdf
常用小技巧:
- 只做类型检测:
--detect - 只看元数据:
--metadata - 输入也可以是 URL 或 stdin
总结
Apache Tika 的核心价值不是“性能最强”,而是 降低多格式文档处理的认知负荷: 用一套 API 替代 POI+PDFBox+... 的组合拳,减少维护成本 本地部署无厂商锁定,适合数据敏感场景
