前言
本文介绍了高效判别频域前馈网络(EDFFN),并将其集成到YOLO26中。EDFFN是为解决图像复原中局部信息表征不足和频域计算成本过高问题而提出的。传统方法存在SSM全局信息偏向性和频域FFN高计算成本的问题,EDFFN通过将频域操作位置从FFN中间层迁移到末端,降低了计算成本并保留了性能。其结构包括特征投影与激活、降维与频域转换、判别性频域筛选、逆变换与特征融合。我们将EDFFN集成到YOLO26,注册并配置yaml文件,实验表明改进后的模型有良好表现。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@[TOC]
介绍

摘要
卷积神经网络(CNN)和视觉变换器(Vision Transformers,ViT)在图像复原任务中都取得了优异的性能。虽然 ViT 在有效捕捉长距离依赖关系和输入特征方面通常优于 CNN,但其计算复杂度会随着图像分辨率的提高而呈二次增长,这一限制阻碍了其在高分辨率图像复原中的实际应用。
本文提出了一种简单而有效的视觉状态空间模型(EVSSM)用于图像去模糊,充分利用了状态空间模型(SSM)在处理视觉数据方面的优势。与现有方法采用多个固定方向扫描来提取特征而导致计算成本显著增加不同,我们设计了一种高效的视觉扫描模块,在每个基于 SSM 的子模块前引入多种几何变换,从而在保持高效率的同时捕捉有用的非局部信息。
此外,为了更有效地提取和表示局部信息,我们还提出了一种基于频域的高效判别前馈网络(EDFFN),能够准确估计图像中对清晰图像复原有用的频率信息。
大量实验结果表明,所提出的 EVSSM 在多个基准数据集和真实图像上均优于现有最先进方法,展现出良好的性能表现。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
Efficient Discriminative Frequency Domain-based Feedforward Network(高效判别频域前馈网络),是该研究为解决图像复原中“局部信息表征不足”与“频域计算成本过高”问题而提出的核心组件之一。
一、EDFFN的设计背景
EDFFN的提出主要针对两类关键问题:
- SSM的全局信息偏向性:论文核心框架基于状态空间模型(SSM,如Mamba),其优势是高效建模长程依赖(全局信息),但天然缺乏对局部细节(如纹理、边缘)的精准捕捉——而局部信息对图像去模糊、去雨等复原任务的“清晰度提升”至关重要。
- 传统频域FFN的高计算成本:此前的频域前馈网络(如FFTformer中的DFFN)虽能通过频域筛选保留有用信息,但存在设计缺陷:
DFFN将频域量化矩阵学习放在FFN的中间层,而该层特征通道数通常是输入特征的3~6倍(如DFFN中间层通道数为输入的3倍)。对大通道特征执行快速傅里叶变换(FFT)会产生极高的计算开销,限制模型在高分辨率图像上的实用性。
二、EDFFN的核心改进:降低成本,保留性能
EDFFN的核心创新是调整频域操作的位置,从“FFN中间层”迁移到“FFN末端”,具体逻辑如下:
| 对比维度 | 传统DFFN(FFTformer) | 改进后EDFFN(本文) |
|---|---|---|
| 频域操作位置 | FFN中间层(大通道特征) | FFN末端(通道数=输入特征) |
| 通道数规模 | 输入特征的3~6倍 | 与输入特征一致(如48通道) |
| FFT计算成本 | 高(大通道特征耗时) | 低(小通道特征高效) |
| 量化矩阵学习 | 基于冗余通道,信息利用率低 | 基于紧凑通道,聚焦关键信息 |
这一调整的本质是:利用FFN“先升维增强表征、后降维压缩信息”的特性,在降维后的紧凑特征上执行频域筛选——既避免了大通道FFT的冗余计算,又能精准捕捉对复原有用的频域信息(如高频细节、低频结构)。
三、EDFFN的结构与工作流程
结合论文图1(d)及文字描述,EDFFN的具体结构的流程如下,核心是“线性变换→激活→频域筛选→输出”的闭环:
-
特征投影与激活:
输入特征(来自EVS块的全局信息特征)先通过1×1点卷积(PConv) 完成通道维度调整(升维增强表征),再经过GELU激活函数引入非线性,增强模型对复杂模式的拟合能力。 -
降维与频域转换:
通过另一层1×1点卷积将特征通道数降维至与输入一致,随后对降维后的特征执行离散傅里叶变换(FFT),将空间域信息转换为频域信息(分离高频细节与低频结构)。 -
判别性频域筛选:
引入一个可学习的量化矩阵W,通过“元素-wise乘法”对频域特征进行筛选——矩阵W会自适应学习“哪些频域信息(如高频边缘、低频轮廓)对恢复清晰图像更重要”,抑制噪声或冗余频域成分。 -
逆变换与特征融合:
对筛选后的频域特征执行逆傅里叶变换(IFFT),将其转换回空间域;最后通过归一化(Norm)和残差连接(与EDFFN的输入特征元素相加),输出融合“局部频域细节”与“全局空间信息”的特征,传递给下一层模块。
核心代码
class EDFFN(nn.Module):
def __init__(self, dim, ffn_expansion_factor=2, bias=False):
super(EDFFN, self).__init__()
hidden_features = int(dim * ffn_expansion_factor)
self.patch_size = 8
self.dim = dim
self.project_in = nn.Conv2d(dim, hidden_features * 2, kernel_size=1, bias=bias)
self.dwconv = nn.Conv2d(hidden_features * 2, hidden_features * 2, kernel_size=3, stride=1, padding=1,
groups=hidden_features * 2, bias=bias)
self.fft = nn.Parameter(torch.ones((dim, 1, 1, self.patch_size, self.patch_size // 2 + 1)))
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
def forward(self, x):
x_dtype = x.dtype
x = self.project_in(x)
x1, x2 = self.dwconv(x).chunk(2, dim=1)
x = F.gelu(x1) * x2
x = self.project_out(x)
b, c, h, w = x.shape
h_n = (8 - h % 8) % 8
w_n = (8 - w % 8) % 8
x = torch.nn.functional.pad(x, (0, w_n, 0, h_n), mode='reflect')
x_patch = rearrange(x, 'b c (h patch1) (w patch2) -> b c h w patch1 patch2', patch1=self.patch_size,
patch2=self.patch_size)
x_patch_fft = torch.fft.rfft2(x_patch.float())
x_patch_fft = x_patch_fft * self.fft
x_patch = torch.fft.irfft2(x_patch_fft, s=(self.patch_size, self.patch_size))
x = rearrange(x_patch, 'b c h w patch1 patch2 -> b c (h patch1) (w patch2)', patch1=self.patch_size,
patch2=self.patch_size)
x=x[:,:,:h,:w]
return x.to(x_dtype)
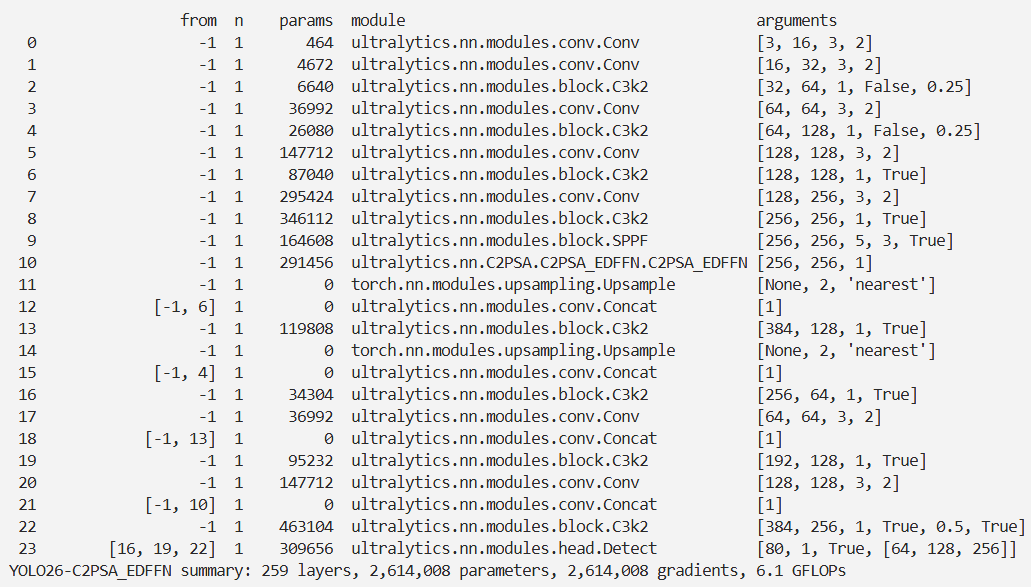
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-C2PSA_EDFFN.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
# optimizer='MuSGD', # 使用MuSGD优化器,会报错
optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-C2PSA_EDFFN',
)
结果