前言
本文介绍了一种创新的白细胞检测方法——多层次特征融合和可变形自注意力 DETR(MFDS - DETR)及其在 YOLO26 中的结合。传统白细胞检测方法耗时且易出错,现代方法也存在局限性。为此设计了高层次筛选特征融合金字塔(HS - FPN),其包含特征选择和融合模块,利用通道注意力模块过滤低层次特征信息并与高层次特征融合,增强特征表达能力;还通过在编码器和解码器引入特定机制解决白细胞特征稀缺问题。我们将相关模块集成进 YOLO26,替换部分模块。经在多个数据集上与其他模型对比,验证了 MFDS - DETR 方法的有效性、优越性和通用性。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@[TOC]
介绍

摘要
本文提出了一种突破性的白细胞检测方法——多层次特征融合和可变形自注意力DETR(MFDS-DETR),旨在革新传统医院血液检测流程中存在的诸多痼疾。传统检测模式中,医务人员需借助显微镜从患者血液显微图像中手动分离白细胞,继而通过自动分类器确定不同类型白细胞的分布情况以辅助临床诊断。此种方法不仅耗费大量人力物力,更因图像质量波动和环境干扰等因素容易产生判读偏差,进而导致分类错误与诊断失准。现有白细胞检测技术在处理特征稀疏的图像样本及应对白细胞尺寸差异方面表现乏力,检测效果往往不尽如人意。
针对上述挑战,我们精心设计了MFDS-DETR检测框架,其核心创新在于两大技术突破:一方面,为应对白细胞尺寸变化问题,我们构建了高层次筛选特征融合金字塔(HS-FPN),实现了多层次特征的智能融合。该模块巧妙地利用高层次特征作为权重指导,通过精密的通道注意力机制对低层次特征进行有效筛选,随后将优化后的特征信息与高层次特征进行深度融合,显著增强了模型的特征表达能力。另一方面,我们创新性地在编码器中引入多尺度可变形自注意模块,并在解码器中融合自注意与交叉可变形注意机制,有效解决了白细胞特征稀缺的难题,极大提升了模型捕获白细胞图像全局特征的能力。
通过在私有WBCDD数据集以及公开的LISC和BCCD基准数据集上与前沿白细胞检测模型的全面比较,充分验证了MFDS-DETR方法的卓越性能、技术优势及广泛适用性。我们的完整源代码及私有WBCCD数据集已在GitHub平台(github.com/JustlfC03/M…
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理

HS-FPN(Hierarchical Scale-based Feature Pyramid Network)是一种用于多尺度特征融合的网络结构,旨在解决白细胞图像中的多尺度挑战,从而提高模型对白细胞的准确识别能力。HS-FPN包括两个主要组件:特征选择模块和特征融合模块。
-
特征选择模块:在特征选择模块中,不同尺度的特征图经过筛选过程。这个过程有助于选择高级和低级特征图中的信息。
-
特征融合模块:在特征融合模块中,经过筛选的特征与高级语义特征进行逐点相加。这种融合方式能够有效地将高级语义信息与低级特征属性相结合,从而提高对白细胞图像的特征表达能力。
HS-FPN利用通道注意(Channel Attention,CA)模块来利用高级语义特征作为权重,以过滤低级特征。这种筛选后的特征与高级语义特征相加,实现了多尺度特征融合,从而提高了模型的特征表达能力。通过这种方式,HS-FPN能够更好地捕获白细胞图像的全面特征信息,从而提高白细胞检测的准确性和效率。
核心代码
import torch
import torch.nn as nn
# 定义HSFPN通道注意力机制类
class HSFPNChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=4, flag=True):
super(HSFPNChannelAttention, self).__init__()
# 自适应平均池化,将输入特征图变为1x1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 自适应最大池化,将输入特征图变为1x1
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 卷积层1,将输入通道数降维
self.conv1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
# ReLU激活函数
self.relu = nn.ReLU()
# 卷积层2,将通道数恢复
self.conv2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
# 标志位,决定输出是否与输入相乘
self.flag = flag
# Sigmoid激活函数
self.sigmoid = nn.Sigmoid()
# 初始化卷积层权重
nn.init.xavier_uniform_(self.conv1.weight)
nn.init.xavier_uniform_(self.conv2.weight)
def forward(self, x):
# 通过平均池化和两层卷积计算通道注意力
avg_out = self.conv2(self.relu(self.conv1(self.avg_pool(x))))
# 通过最大池化和两层卷积计算通道注意力
max_out = self.conv2(self.relu(self.conv1(self.max_pool(x))))
# 将平均池化和最大池化的结果相加
out = avg_out + max_out
# 根据flag决定是否与输入相乘并返回结果
return self.sigmoid(out) * x if self.flag else self.sigmoid(out)
# 定义Multiply类,实现两个输入的元素乘法
class Multiply(nn.Module):
def __init__(self) -> None:
super().__init__()
def forward(self, x):
# 返回两个输入的逐元素乘积
return x[0] * x[1]
# 定义Add类,实现多个输入的求和
class Add(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
# 将多个输入堆叠后沿第一个维度求和
return torch.sum(torch.stack(x, dim=0), dim=0)
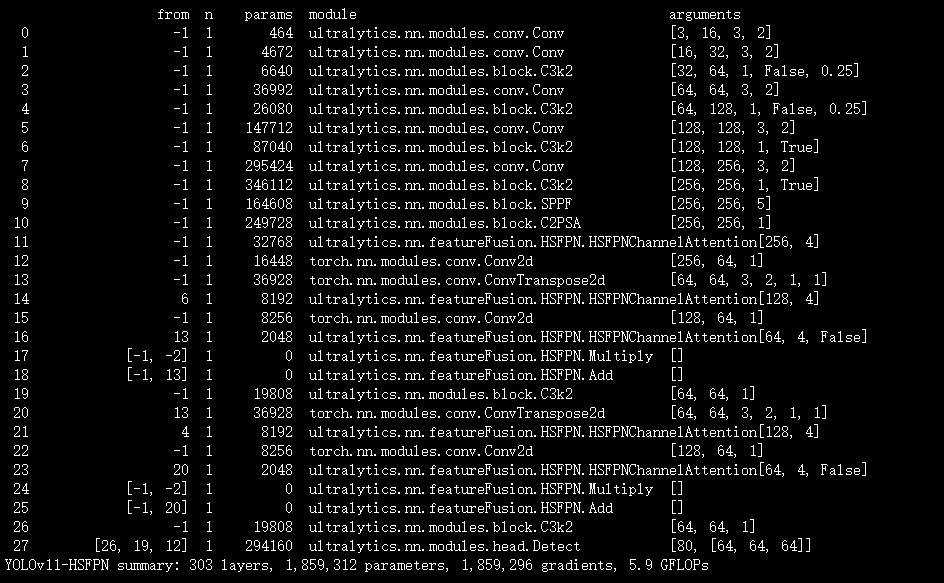
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/YOLO26-HSFPN.yaml')
# 修改为自己的数据集地址
model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='HSFPN',
)
结果