前言
本文介绍了多样分支模块(DBB)在YOLO26中的结合应用。DBB通过组合不同尺度和复杂度的多样化分支来丰富特征空间,增强单一卷积的表示能力,在训练时使用复杂微结构提升性能,推理时转换为单层卷积以保持高效。它能解耦训练和推理结构,具有更好的灵活性和适应性。我们将DBB集成到YOLO26的主干网络中,并进行相关注册和配置。实验表明,DBB在图像分类、目标检测和语义分割任务上均有显著改进。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@[TOC]
介绍

摘要
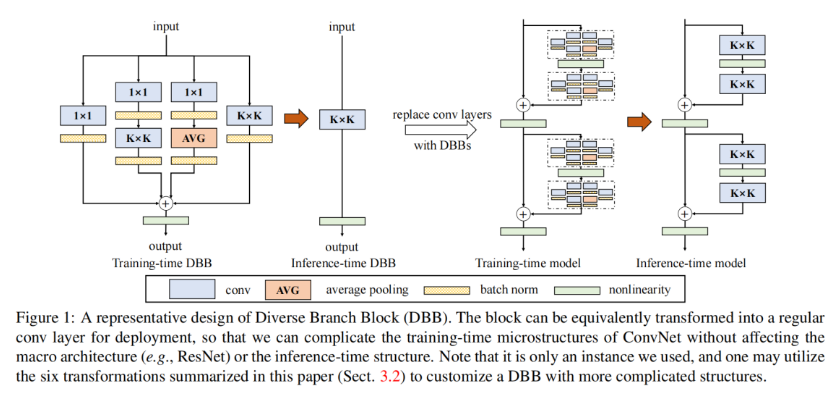
我们提出了一种卷积神经网络(ConvNet)的通用构建模块,旨在不增加推理阶段成本的情况下提高模型性能。该模块被命名为多样分支模块(Diverse Branch Block,DBB),其通过组合不同尺度和复杂度的多样化分支来拓展特征空间,进而增强单一卷积的表示能力,这些分支涵盖卷积序列、多尺度卷积以及平均池化等。训练结束后,DBB能够等效转换为单层卷积以用于模型部署。与新型ConvNet架构的创新有所不同,DBB着重对训练阶段的微结构进行复杂化处理,同时保持宏观架构不变,因而可以直接替代任意架构中的常规卷积层。通过这种方式,模型在训练阶段能够实现更高的性能水平,而在推理阶段则可转换回原始的推理结构进行推理操作。DBB在图像分类(在ImageNet上使top - 1准确率提升了高达1.9%)、目标检测和语义分割等任务中均展现出显著的性能改进。相关的PyTorch代码和模型已发布于:github.com/DingXiaoH/D…
创新点
Diverse Branch Block (DBB) 是一种新提出的卷积神经网络(ConvNet)构建模块,旨在提高模型性能而不增加推理时的计算成本。以下是对 DBB 的详细介绍:
-
设计理念: DBB 的核心思想是通过结合不同规模和复杂度的多条分支来增强单个卷积的表示能力。这种设计使得网络能够在训练阶段利用更复杂的结构,从而丰富特征空间,进而提高模型的性能。
-
训练与推理的分离: DBB 允许在训练时使用复杂的微结构,而在推理时将其转换为原始的卷积层结构。这种方法的好处在于,训练时可以利用更强大的特征提取能力,而在推理时则保持高效的计算性能。这种训练和推理结构的解耦使得 DBB 具有更好的灵活性和适应性。
-
多分支结构: DBB 采用多分支拓扑结构,每个分支可以是不同类型的卷积(如 1×1 卷积和 3×3 卷积)或其他操作(如平均池化)。研究表明,结合具有不同表示能力的分支(例如,一个 1×1 卷积和一个 3×3 卷积)比使用两个强能力的分支(例如两个 3×3 卷积)更有效,这为 ConvNet 的架构设计提供了新的思路。
-
性能提升: 实验结果表明,DBB 在图像分类、目标检测和语义分割等任务上均能显著提高性能。例如,在 ImageNet 数据集上,DBB 提高了最高 1.9% 的 top-1 准确率。
-
实现与应用: DBB 作为一个通用的构建模块,可以被集成到多种 ConvNet 架构中,作为常规卷积层的替代品。其实现代码和模型已在 GitHub 上发布,方便研究人员和开发者使用。
文章链接
论文地址:论文地址
代码地址:代码地址
核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from dbb_transforms import *
def conv_bn(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,
padding_mode='zeros'):
conv_layer = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups,
bias=False, padding_mode=padding_mode)
bn_layer = nn.BatchNorm2d(num_features=out_channels, affine=True)
se = nn.Sequential()
se.add_module('conv', conv_layer)
se.add_module('bn', bn_layer)
return se
class IdentityBasedConv1x1(nn.Conv2d):
def __init__(self, channels, groups=1):
super(IdentityBasedConv1x1, self).__init__(in_channels=channels, out_channels=channels, kernel_size=1, stride=1, padding=0, groups=groups, bias=False)
assert channels % groups == 0
input_dim = channels // groups
id_value = np.zeros((channels, input_dim, 1, 1))
for i in range(channels):
id_value[i, i % input_dim, 0, 0] = 1
self.id_tensor = torch.from_numpy(id_value).type_as(self.weight)
nn.init.zeros_(self.weight)
def forward(self, input):
kernel = self.weight + self.id_tensor.to(self.weight.device)
result = F.conv2d(input, kernel, None, stride=1, padding=0, dilation=self.dilation, groups=self.groups)
return result
def get_actual_kernel(self):
return self.weight + self.id_tensor.to(self.weight.device)
class BNAndPadLayer(nn.Module):
def __init__(self,
pad_pixels,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
track_running_stats=True):
super(BNAndPadLayer, self).__init__()
self.bn = nn.BatchNorm2d(num_features, eps, momentum, affine, track_running_stats)
self.pad_pixels = pad_pixels
def forward(self, input):
output = self.bn(input)
if self.pad_pixels > 0:
if self.bn.affine:
pad_values = self.bn.bias.detach() - self.bn.running_mean * self.bn.weight.detach() / torch.sqrt(self.bn.running_var + self.bn.eps)
else:
pad_values = - self.bn.running_mean / torch.sqrt(self.bn.running_var + self.bn.eps)
output = F.pad(output, [self.pad_pixels] * 4)
pad_values = pad_values.view(1, -1, 1, 1)
output[:, :, 0:self.pad_pixels, :] = pad_values
output[:, :, -self.pad_pixels:, :] = pad_values
output[:, :, :, 0:self.pad_pixels] = pad_values
output[:, :, :, -self.pad_pixels:] = pad_values
return output
@property
def weight(self):
return self.bn.weight
@property
def bias(self):
return self.bn.bias
@property
def running_mean(self):
return self.bn.running_mean
@property
def running_var(self):
return self.bn.running_var
@property
def eps(self):
return self.bn.eps
class DiverseBranchBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1,
internal_channels_1x1_3x3=None,
deploy=False, nonlinear=None, single_init=False):
super(DiverseBranchBlock, self).__init__()
self.deploy = deploy
if nonlinear is None:
self.nonlinear = nn.Identity()
else:
self.nonlinear = nonlinear
self.kernel_size = kernel_size
self.out_channels = out_channels
self.groups = groups
assert padding == kernel_size // 2
if deploy:
self.dbb_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True)
else:
self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups)
self.dbb_avg = nn.Sequential()
if groups < out_channels:
self.dbb_avg.add_module('conv',
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1,
stride=1, padding=0, groups=groups, bias=False))
self.dbb_avg.add_module('bn', BNAndPadLayer(pad_pixels=padding, num_features=out_channels))
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))
self.dbb_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
padding=0, groups=groups)
else:
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=padding))
self.dbb_avg.add_module('avgbn', nn.BatchNorm2d(out_channels))
if internal_channels_1x1_3x3 is None:
internal_channels_1x1_3x3 = in_channels if groups < out_channels else 2 * in_channels # For mobilenet, it is better to have 2X internal channels
self.dbb_1x1_kxk = nn.Sequential()
if internal_channels_1x1_3x3 == in_channels:
self.dbb_1x1_kxk.add_module('idconv1', IdentityBasedConv1x1(channels=in_channels, groups=groups))
else:
self.dbb_1x1_kxk.add_module('conv1', nn.Conv2d(in_channels=in_channels, out_channels=internal_channels_1x1_3x3,
kernel_size=1, stride=1, padding=0, groups=groups, bias=False))
self.dbb_1x1_kxk.add_module('bn1', BNAndPadLayer(pad_pixels=padding, num_features=internal_channels_1x1_3x3, affine=True))
self.dbb_1x1_kxk.add_module('conv2', nn.Conv2d(in_channels=internal_channels_1x1_3x3, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=0, groups=groups, bias=False))
self.dbb_1x1_kxk.add_module('bn2', nn.BatchNorm2d(out_channels))
# The experiments reported in the paper used the default initialization of bn.weight (all as 1). But changing the initialization may be useful in some cases.
if single_init:
# Initialize the bn.weight of dbb_origin as 1 and others as 0. This is not the default setting.
self.single_init()
def get_equivalent_kernel_bias(self):
k_origin, b_origin = transI_fusebn(self.dbb_origin.conv.weight, self.dbb_origin.bn)
if hasattr(self, 'dbb_1x1'):
k_1x1, b_1x1 = transI_fusebn(self.dbb_1x1.conv.weight, self.dbb_1x1.bn)
k_1x1 = transVI_multiscale(k_1x1, self.kernel_size)
else:
k_1x1, b_1x1 = 0, 0
if hasattr(self.dbb_1x1_kxk, 'idconv1'):
k_1x1_kxk_first = self.dbb_1x1_kxk.idconv1.get_actual_kernel()
else:
k_1x1_kxk_first = self.dbb_1x1_kxk.conv1.weight
k_1x1_kxk_first, b_1x1_kxk_first = transI_fusebn(k_1x1_kxk_first, self.dbb_1x1_kxk.bn1)
k_1x1_kxk_second, b_1x1_kxk_second = transI_fusebn(self.dbb_1x1_kxk.conv2.weight, self.dbb_1x1_kxk.bn2)
k_1x1_kxk_merged, b_1x1_kxk_merged = transIII_1x1_kxk(k_1x1_kxk_first, b_1x1_kxk_first, k_1x1_kxk_second, b_1x1_kxk_second, groups=self.groups)
k_avg = transV_avg(self.out_channels, self.kernel_size, self.groups)
k_1x1_avg_second, b_1x1_avg_second = transI_fusebn(k_avg.to(self.dbb_avg.avgbn.weight.device), self.dbb_avg.avgbn)
if hasattr(self.dbb_avg, 'conv'):
k_1x1_avg_first, b_1x1_avg_first = transI_fusebn(self.dbb_avg.conv.weight, self.dbb_avg.bn)
k_1x1_avg_merged, b_1x1_avg_merged = transIII_1x1_kxk(k_1x1_avg_first, b_1x1_avg_first, k_1x1_avg_second, b_1x1_avg_second, groups=self.groups)
else:
k_1x1_avg_merged, b_1x1_avg_merged = k_1x1_avg_second, b_1x1_avg_second
return transII_addbranch((k_origin, k_1x1, k_1x1_kxk_merged, k_1x1_avg_merged), (b_origin, b_1x1, b_1x1_kxk_merged, b_1x1_avg_merged))
def switch_to_deploy(self):
if hasattr(self, 'dbb_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.dbb_reparam = nn.Conv2d(in_channels=self.dbb_origin.conv.in_channels, out_channels=self.dbb_origin.conv.out_channels,
kernel_size=self.dbb_origin.conv.kernel_size, stride=self.dbb_origin.conv.stride,
padding=self.dbb_origin.conv.padding, dilation=self.dbb_origin.conv.dilation, groups=self.dbb_origin.conv.groups, bias=True)
self.dbb_reparam.weight.data = kernel
self.dbb_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('dbb_origin')
self.__delattr__('dbb_avg')
if hasattr(self, 'dbb_1x1'):
self.__delattr__('dbb_1x1')
self.__delattr__('dbb_1x1_kxk')
def forward(self, inputs):
if hasattr(self, 'dbb_reparam'):
return self.nonlinear(self.dbb_reparam(inputs))
out = self.dbb_origin(inputs)
if hasattr(self, 'dbb_1x1'):
out += self.dbb_1x1(inputs)
out += self.dbb_avg(inputs)
out += self.dbb_1x1_kxk(inputs)
return self.nonlinear(out)
def init_gamma(self, gamma_value):
if hasattr(self, "dbb_origin"):
torch.nn.init.constant_(self.dbb_origin.bn.weight, gamma_value)
if hasattr(self, "dbb_1x1"):
torch.nn.init.constant_(self.dbb_1x1.bn.weight, gamma_value)
if hasattr(self, "dbb_avg"):
torch.nn.init.constant_(self.dbb_avg.avgbn.weight, gamma_value)
if hasattr(self, "dbb_1x1_kxk"):
torch.nn.init.constant_(self.dbb_1x1_kxk.bn2.weight, gamma_value)
def single_init(self):
self.init_gamma(0.0)
if hasattr(self, "dbb_origin"):
torch.nn.init.constant_(self.dbb_origin.bn.weight, 1.0)
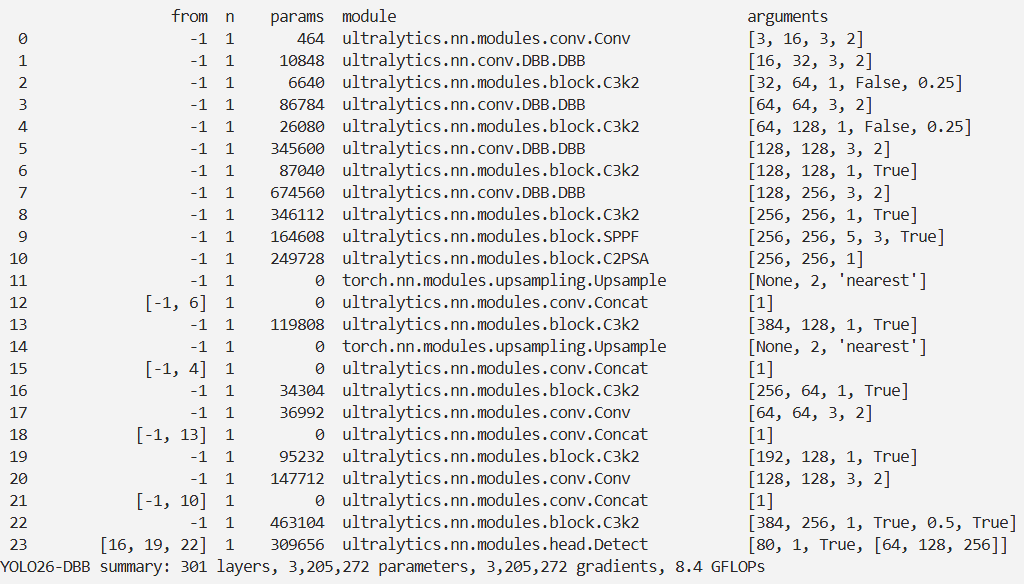
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-DBB.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
# optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-DBB',
)
结果