前言
本文介绍了重新参数化再聚焦卷积(RefConv)在YOLO26中的结合应用。RefConv通过对预训练模型的基础卷积核应用可训练的再聚焦转换,建立参数间连接,利用预训练参数作为先验学习新表示,增强模型表示能力。它能减少通道冗余、平滑损失景观,提升多种基于CNN模型在图像分类、目标检测和语义分割上的性能,且不增加推理成本或改变模型结构。我们将RefConv集成到YOLO26的主干网络中,并进行相关注册和配置。实验结果验证了其有效性。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@[TOC]
介绍

摘要
我们提出了重新参数化再聚焦卷积(Re - parameterized Refocusing Convolution, RefConv)作为常规卷积层的替代方案,这是一个即插即用的模块,能够在不增加推理成本的前提下提升性能。具体而言,针对预训练模型,RefConv会对从预训练模型继承而来的基础卷积核实施可训练的再聚焦转换,以此在参数之间构建联系。例如,深度卷积的RefConv能够将特定通道的卷积核参数与其他卷积核的参数相关联,即便这些参数重新聚焦于模型的其他部分,而非仅仅关注输入特征。从另一视角来看,RefConv借助将预训练参数中编码的表示作为先验信息,并对这些先验进行重新聚焦以学习新的表示,进而增强预训练模型的表示能力。实验结果证实,RefConv能够显著提高多种基于卷积神经网络(CNN)的模型在图像分类(在ImageNet上最高可使top - 1准确率提升1.47%)、目标检测和语义分割等任务上的性能,且不会引入任何额外的推理成本,也不会改变原始模型结构。进一步研究显示,RefConv能够减少通道冗余并使损失景观更加平滑,这为其有效性提供了解释。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
RefConv是一种重新参数化的重聚焦卷积模块,旨在提高卷积神经网络的性能,而无需额外的推断成本。它通过应用可训练的重聚焦变换到预训练模型的基础核来建立参数之间的连接。RefConv可以取代原始的卷积层,使特定通道的卷积核参数与其他卷积核的参数相关联,从而使它们重新聚焦到模型的其他部分,而不仅仅关注输入特征。这样做可以利用预训练参数中编码的表示作为先验,并重新聚焦到这些表示上,从而学习新颖的表示,进一步增强预训练模型的表示能力。
-
重聚焦变换:给定一个预训练模型,RefConv应用可训练的重聚焦变换到继承自预训练模型的基础核上,以建立参数之间的连接。例如,一个深度卷积的RefConv可以将特定通道的卷积核参数与其他卷积核的参数相关联,使它们重新聚焦到模型的其他部分,而不仅仅关注输入特征。
-
增强模型结构的先验:RefConv通过利用预训练参数中编码的表示作为先验,并重新聚焦到这些表示上,学习新颖的表示,从而增强预训练模型的表示能力。这种方法不改变模型结构,而是通过改变卷积核参数之间的关系来提高模型性能。
-
通道冗余减少和损失曲面平滑:RefConv可以减少通道冗余,使损失曲面更加平滑。通过扩大核通道之间的KL散度,减少通道相似性和冗余,RefConv能够学习更多样化的表示,增强模型的表示能力。
核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class RepConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding=None, groups=1,
map_k=3):
super(RepConv, self).__init__()
assert map_k <= kernel_size
# 记录原始卷积核形状
self.origin_kernel_shape = (out_channels, in_channels // groups, kernel_size, kernel_size)
self.register_buffer('weight', torch.zeros(*self.origin_kernel_shape))
G = in_channels * out_channels // (groups ** 2)
self.num_2d_kernels = out_channels * in_channels // groups
self.kernel_size = kernel_size
# 使用 2D 卷积生成映射
self.convmap = nn.Conv2d(in_channels=self.num_2d_kernels,
out_channels=self.num_2d_kernels, kernel_size=map_k, stride=1, padding=map_k // 2,
groups=G, bias=False)
self.bias = None
self.stride = stride
self.groups = groups
if padding is None:
padding = kernel_size // 2
self.padding = padding
def forward(self, inputs):
# 生成权重矩阵
origin_weight = self.weight.view(1, self.num_2d_kernels, self.kernel_size, self.kernel_size)
# 使用卷积映射更新权重
kernel = self.weight + self.convmap(origin_weight).view(*self.origin_kernel_shape)
return F.conv2d(inputs, kernel, stride=self.stride, padding=self.padding, dilation=1, groups=self.groups, bias=self.bias)
class RepConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(RepConvBlock, self).__init__()
# 定义 RepConv 模块
self.conv = RepConv(in_channels, out_channels, kernel_size=3, stride=stride, padding=None, groups=1, map_k=3)
# 批量归一化层
self.bn = nn.BatchNorm2d(out_channels)
# 激活函数
self.act = Hswish()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
class Hswish(nn.Module):
def __init__(self, inplace=True):
super(Hswish, self).__init__()
self.inplace = inplace
def forward(self, x):
# H-swish 激活函数
return x * F.relu6(x + 3., inplace=self.inplace) / 6.
# 测试模块
if __name__ == "__main__":
# 创建 RepConvBlock 实例并进行前向传播测试
block = RepConvBlock(in_channels=3, out_channels=64, stride=1)
x = torch.randn(1, 3, 224, 224)
output = block(x)
print("Output shape:", output.shape)
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-RefConv.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
amp=True,
project='runs/train',
name='yolo26-RefConv',
)
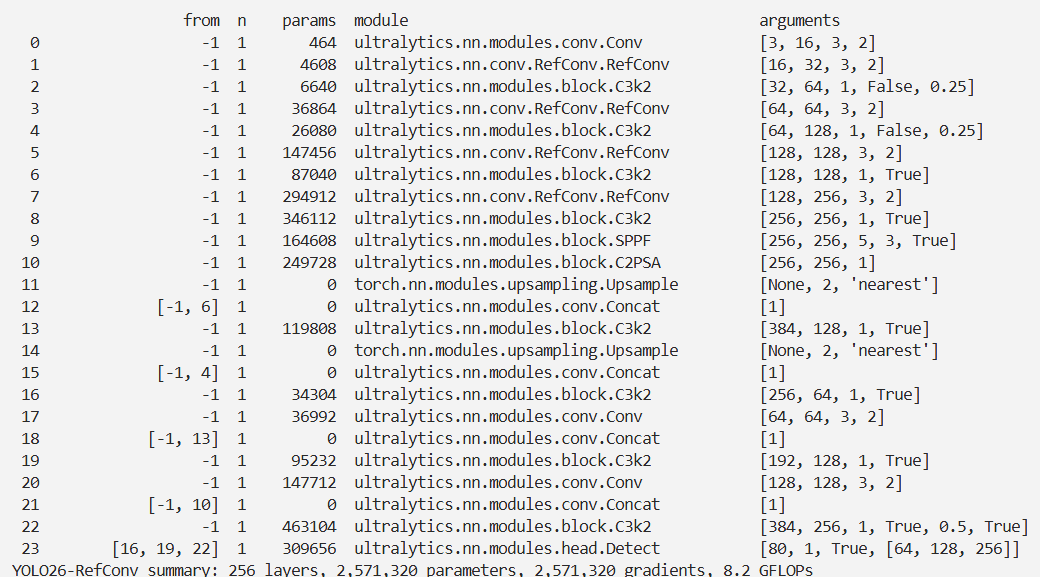
结果