前言
本文介绍了线性可变形卷积(LDConv)在YOLO26中的结合应用。标准卷积存在局部窗口和固定采样形状的缺陷,可变形卷积虽解决了固定采样问题,但参数数量呈平方增长。LDConv通过新的坐标生成算法和偏移量调整,为卷积核提供任意数量的参数和任意采样形状,将参数增长趋势修正为线性增长。我们将LDConv集成到YOLO26的主干网络中,并在相关配置文件中进行设置。在多个代表性数据集上的实验表明,LDConv可替代标准卷积,提升网络性能。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@[TOC]
LDConv介绍
LDConv作者的姊妹篇: 【YOLO26改进-卷积Conv 】 AKConv(可改变核卷积):任意数量的参数和任意采样形状的即插即用的卷积

摘要
基于卷积操作的神经网络在深度学习领域取得了显著的成果,但标准卷积操作存在两个固有的缺陷。一方面,卷积操作仅限于局部窗口,因此无法捕捉其他位置的信息,并且其采样形状是固定的。另一方面,卷积核的大小固定为 ,这是一个固定的正方形形状,且参数的数量通常会随着大小的增加呈平方增长。尽管可变形卷积(Deformable Convolution,Deformable Conv)解决了标准卷积的固定采样问题,但参数数量也会呈平方增长,并且可变形卷积并未探讨不同初始采样形状对网络性能的影响。针对上述问题,本文提出了线性可变形卷积(Linear Deformable Convolution,LDConv),该方法为卷积核提供了任意数量的参数和任意采样形状,以便为网络开销与性能之间的折中提供更丰富的选择。
在LDConv中,定义了一种新的坐标生成算法,用于为任意大小的卷积核生成不同的初始采样位置。为了适应目标的变化,引入了偏移量来调整每个位置上样本的形状。LDConv将标准卷积和可变形卷积中参数数量的增长趋势从平方增长修正为线性增长。与可变形卷积相比,LDConv提供了更丰富的选择,并且当LDConv的参数数量设置为 时,可以等效于可变形卷积。与此不同,本文还探讨了使用LDConv在相同大小和不同初始采样形状下对神经网络的影响。LDConv通过不规则的卷积操作完成高效的特征提取,并为卷积采样形状提供了更多的探索选项。
在COCO2017、VOC 7+12 和 VisDrone-DET2021等代表性数据集上的目标检测实验充分证明了LDConv的优势。LDConv是一个即插即用的卷积操作,可以替代标准卷积操作,从而提高网络性能。相关任务的代码可以在 github.com/CV-ZhangXin… 上找到。
文章链接
论文地址:论文地址
代码地址:代码地址
主要思想
LDConv(线性可变形卷积)是一种新型的卷积操作,旨在改进传统卷积神经网络(CNN),解决标准卷积和早期的可变形卷积的不足之处。以下是LDConv的关键特点和创新点:
动机与传统卷积的局限性
-
标准卷积的限制:
- 传统卷积仅限于固定的采样网格(如3x3、5x5),难以适应不同对象的多样化形状。
- 随着卷积核大小增加,参数数量呈平方增长,导致计算成本和存储需求显著提升。
-
可变形卷积的改进:
- 可变形卷积引入偏移,灵活调整采样位置以适应不同特征区域,但其参数增长仍呈平方趋势,无法实现完全自由的采样形状。
LDConv的创新
LDConv克服了上述不足,引入了可调整的采样形状和参数数量,从而在计算成本和性能之间实现更灵活的平衡。LDConv的核心创新包括:
-
任意采样形状与线性增长的参数数量:
- LDConv允许卷积核具有任意形状的采样点,并使参数数量呈线性增长,这种灵活性更适合硬件资源限制。
-
动态采样位置调整:
- 通过一个新的坐标生成算法,为任意大小的卷积核生成初始采样位置,并根据对象形状动态调整这些位置,使其适应目标的变化。
-
模块化与易于集成:
-
LDConv是一个“即插即用”的卷积模块,可以替代现有网络中的标准卷积操作,从而在目标检测等任务中提升性能。
-
核心代码
class LDConv(nn.Module):
def __init__(self, inc, outc, num_param, stride=1, bias=None):
super(LDConv, self).__init__()
self.num_param = num_param
self.stride = stride
self.conv = nn.Sequential(nn.Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias),nn.BatchNorm2d(outc),nn.SiLU()) # the conv adds the BN and SiLU to compare original Conv in YOLOv5.
self.p_conv = nn.Conv2d(inc, 2 * num_param, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_full_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x):
# N is num_param.
offset = self.p_conv(x)
dtype = offset.data.type()
N = offset.size(1) // 2
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# resampling the features based on the modified coordinates.
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# bilinear
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
x_offset = self._reshape_x_offset(x_offset, self.num_param)
out = self.conv(x_offset)
return out
# generating the inital sampled shapes for the LDConv with different sizes.
def _get_p_n(self, N, dtype):
base_int = round(math.sqrt(self.num_param))
row_number = self.num_param // base_int
mod_number = self.num_param % base_int
p_n_x,p_n_y = torch.meshgrid(
torch.arange(0, row_number),
torch.arange(0,base_int))
p_n_x = torch.flatten(p_n_x)
p_n_y = torch.flatten(p_n_y)
if mod_number > 0:
mod_p_n_x,mod_p_n_y = torch.meshgrid(
torch.arange(row_number,row_number+1),
torch.arange(0,mod_number))
mod_p_n_x = torch.flatten(mod_p_n_x)
mod_p_n_y = torch.flatten(mod_p_n_y)
p_n_x,p_n_y = torch.cat((p_n_x,mod_p_n_x)),torch.cat((p_n_y,mod_p_n_y))
p_n = torch.cat([p_n_x,p_n_y], 0)
p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)
return p_n
# no zero-padding
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(0, h * self.stride, self.stride),
torch.arange(0, w * self.stride, self.stride))
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N] * padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
# Stacking resampled features in the row direction.
@staticmethod
def _reshape_x_offset(x_offset, num_param):
b, c, h, w, n = x_offset.size()
# using Conv3d
# x_offset = x_offset.permute(0,1,4,2,3), then Conv3d(c,c_out, kernel_size =(num_param,1,1),stride=(num_param,1,1),bias= False)
# using 1 × 1 Conv
# x_offset = x_offset.permute(0,1,4,2,3), then, x_offset.view(b,c×num_param,h,w) finally, Conv2d(c×num_param,c_out, kernel_size =1,stride=1,bias= False)
# using the column conv as follow, then, Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias)
x_offset = rearrange(x_offset, 'b c h w n -> b c (h n) w')
return x_offset
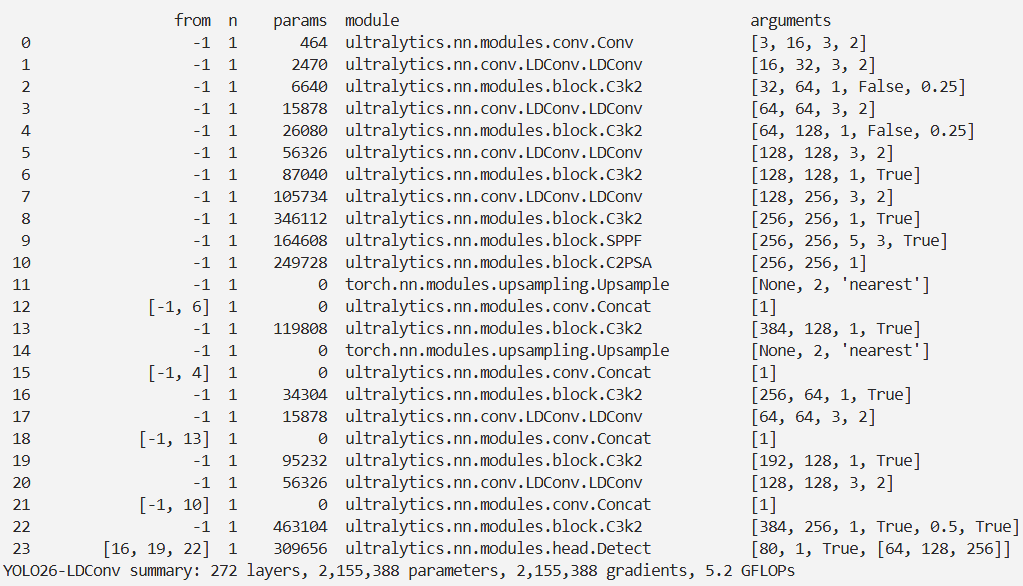
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-LDConv.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
amp=True,
project='runs/train',
name='yolo26-LDConv',
)
结果