前言
本文介绍了焦点调制网络(FocalNets)及其在YOLO26中的结合应用。FocalNets完全用焦点调制模块替代自注意力,该模块由焦点上下文化、门控聚合和逐元素仿射变换组成,能有效建模视觉中的标记交互。它通过局部特征聚焦、全局信息调制和多尺度处理增强模型表达能力。我们将FocalModulation模块集成进YOLO26。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@[TOC]
介绍

摘要
本研究提出焦点调制网络(FocalNets),该网络采用焦点调制模块完全替代自注意力(SA)机制,用于视觉任务中的标记交互建模。焦点调制模块由三个核心组件构成:(i)焦点上下文化组件,通过深度卷积层序列实现从短距离到长距离的视觉上下文编码;(ii)门控聚合组件,选择性将上下文信息聚合至每个查询标记的调制器中;(iii)逐元素仿射变换组件,将调制器注入查询标记。大量实验验证表明,FocalNets展现出卓越的可解释性特征,并在图像分类、目标检测及分割任务中以相近计算成本超越了当前最先进的SA模型(如Swin和Focal Transformers)。具体而言,FocalNets小型与基础版本在ImageNet-1K数据集上分别实现了82.3%和83.9%的top-1准确率;在ImageNet-22K数据集以224×224分辨率预训练后,微调至224×224和384×384分辨率时分别达到86.5%和87.3%的top-1准确率。在目标检测任务中,基于Mask R-CNN框架的FocalNet基础版本以1×训练计划超越Swin对照组2.1个百分点,且已超过采用3×训练计划的Swin模型(49.0对48.5);在语义分割任务中,基于UPerNet框架的FocalNet基础版本在单尺度测试下超越Swin模型2.4个百分点,多尺度测试下同样表现优异(50.5对49.7)。进一步地,采用大型FocalNet与Mask2former组合在ADE20K语义分割任务中达到58.5 mIoU,在COCO全景分割任务中获得57.9 PQ;采用巨型FocalNet与DINO组合在COCO minival和test-dev数据集上分别实现64.3和64.4 mAP,显著超越Swinv2-G和BEIT-3等基于注意力机制的大型模型。这些系统性实验结果充分证明焦点调制机制在视觉计算领域具有重要应用价值与发展潜力。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
Focal Modulation机制旨在结合CNNs和自注意力机制的优点,通过在不同的空间尺度上聚焦(Focal)和调制(Modulation)特征来增强模型的表达能力。具体来说,Focal Modulation包含以下几个关键组件:
-
局部特征聚焦(Local Focalization):
- 通过聚焦机制在局部区域内提取特征,类似于卷积操作。这有助于捕捉局部模式和细节。
-
全局信息调制(Global Modulation):
- 在全局范围内对特征进行调制,类似于自注意力机制。这有助于整合全局上下文信息,使模型能够理解更广泛的特征关系。
-
多尺度处理(Multi-Scale Processing):
- 通过在不同尺度上进行特征提取和调制,Focal Modulation能够同时处理图像中的细节和整体结构。这种多尺度特性使得模型在处理复杂场景时更具鲁棒性。
具体实现
Focal Modulation的具体实现可以通过以下步骤进行:
-
特征提取:
- 使用卷积层或其他局部运算层提取初始特征。
-
局部聚焦:
- 对提取的特征进行局部聚焦操作,可以采用池化(Pooling)或注意力机制来实现。
-
全局调制:
- 利用全局上下文信息对局部聚焦后的特征进行调制。这可以通过全局注意力层或其他全局运算层实现。
-
多尺度融合:
-
将不同尺度上的特征进行融合,通过跳跃连接(Skip Connections)或金字塔结构(Pyramid Structure)来整合多尺度信息。
-
核心代码
class FocalModulation(nn.Module):
""" 焦点调制模块
Args:
dim (int): 输入通道数。
proj_drop (float, optional): 输出的dropout比率。默认值:0.0
focal_level (int): 焦点层级的数量
focal_window (int): 焦点层级1的焦点窗口大小
focal_factor (int, default=2): 增加焦点窗口的步长
use_postln (bool, default=False): 是否使用后调制层归一化
"""
def __init__(self, dim, proj_drop=0., focal_level=2, focal_window=7, focal_factor=2, use_postln=False):
super().__init__()
self.dim = dim
# 焦点调制模块的特定参数
self.focal_level = focal_level
self.focal_window = focal_window
self.focal_factor = focal_factor
self.use_postln = use_postln
# 线性层,输出维度为2*dim+(焦点层级数+1)
self.f = nn.Linear(dim, 2*dim+(self.focal_level+1), bias=True)
# 1x1卷积层,输入和输出通道数均为dim
self.h = nn.Conv2d(dim, dim, kernel_size=1, stride=1, padding=0, groups=1, bias=True)
# GELU激活函数
self.act = nn.GELU()
# 线性层,输入和输出维度均为dim
self.proj = nn.Linear(dim, dim)
# Dropout层,使用给定的丢弃比率
self.proj_drop = nn.Dropout(proj_drop)
# 存储焦点层的列表
self.focal_layers = nn.ModuleList()
if self.use_postln:
# 如果使用后调制层归一化,定义层归一化层
self.ln = nn.LayerNorm(dim)
# 构建每个焦点层
for k in range(self.focal_level):
# 根据层级计算卷积核大小
kernel_size = self.focal_factor*k + self.focal_window
self.focal_layers.append(
nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1, groups=dim,
padding=kernel_size//2, bias=False),
nn.GELU(),
)
)
def forward(self, x):
""" 前向传播函数
Args:
x: 形状为(B, H, W, C)的输入特征
"""
B, nH, nW, C = x.shape
# 通过线性层f,得到形状为(B, H, W, 2*C + 焦点层级数+1)的张量
x = self.f(x)
# 将通道维度移动到第二维,并转换为连续内存布局
x = x.permute(0, 3, 1, 2).contiguous()
# 将张量x拆分为查询q、上下文ctx和门控信号gates
q, ctx, gates = torch.split(x, (C, C, self.focal_level+1), 1)
ctx_all = 0
# 处理每个焦点层级
for l in range(self.focal_level):
ctx = self.focal_layers[l](ctx)
ctx_all = ctx_all + ctx*gates[:, l:l+1]
# 计算全局上下文,并应用激活函数
ctx_global = self.act(ctx.mean(2, keepdim=True).mean(3, keepdim=True))
ctx_all = ctx_all + ctx_global*gates[:,self.focal_level:]
# 查询q与处理后的上下文相乘
x_out = q * self.h(ctx_all)
# 将通道维度移动到最后,并转换为连续内存布局
x_out = x_out.permute(0, 2, 3, 1).contiguous()
# 如果使用后调制层归一化,应用层归一化
if self.use_postln:
x_out = self.ln(x_out)
# 通过线性层和Dropout层
x_out = self.proj(x_out)
x_out = self.proj_drop(x_out)
return x_out
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-FocalModulation.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
# optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-FocalModulation',
)
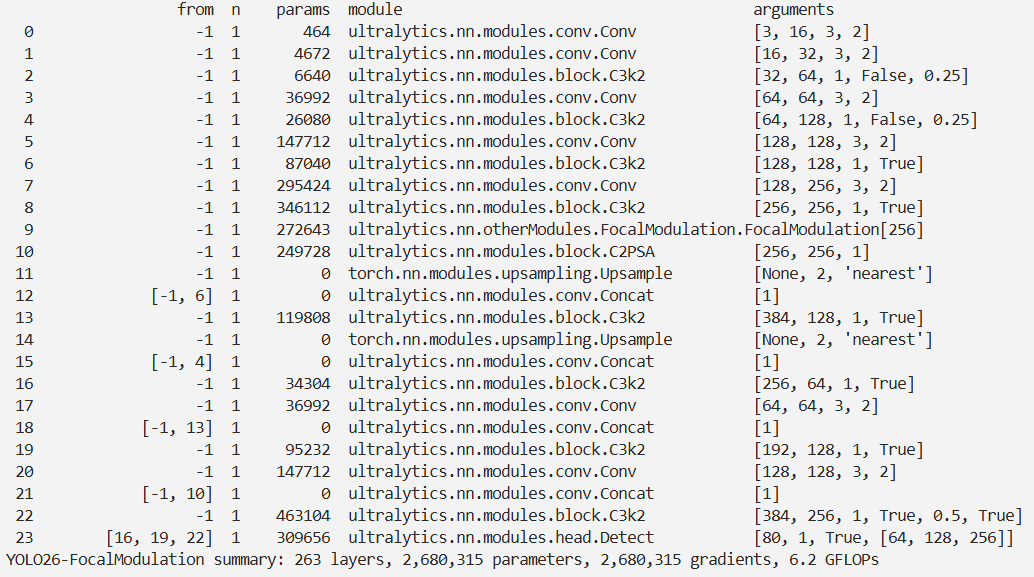
结果