前言
本文介绍了多尺度线性注意力机制MSLA,并将其集成进YOLO26。现有基于CNN和Transformer的医学图像分割方法存在局限性,为解决这些问题,我们提出了MSLAU-Net架构,其中MSLA通过并行多尺度特征提取和低复杂度线性注意力计算,捕获细粒度局部细节与全局长程依赖。我们将MSLA的代码集成到YOLO26中,创建C2PSA_MSLA模块,并在tasks文件中进行注册。实验证明,YOLO26-C2PSA_MSLA在目标检测任务中取得了良好的效果,验证了方法的优越性、有效性和鲁棒性。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@[TOC]
介绍

摘要
精准的医学图像分割能够精确勾勒解剖结构和病理区域,这对于治疗规划、手术导航和疾病监测至关重要。基于 CNN(卷积神经网络)和基于 Transformer 的方法在医学图像分割任务中均取得了显著成效。然而,由于卷积运算的固有局限性,基于 CNN 的方法难以有效捕获全局上下文信息;与此同时,基于 Transformer 的方法存在局部特征建模不足的问题,且面临自注意力机制带来的高计算复杂度挑战。为解决这些局限性,我们提出了一种新颖的混合 CNN-Transformer 架构,命名为 MSLAU-Net,该架构融合了两种范式的优势。所提出的 MSLAU-Net 包含两个核心设计:其一,引入多尺度线性注意力(Multi-Scale Linear Attention, MSLA),旨在高效提取医学图像的多尺度特征,同时以低计算复杂度建模长程依赖关系;其二,采用自上而下的特征聚合机制,通过轻量化结构执行多尺度特征聚合并恢复空间分辨率。在涵盖三种成像模态的基准数据集上开展的大量实验表明,MSLAU-Net 在几乎所有评估指标上均优于其他最先进方法,验证了我们方法的优越性、有效性和鲁棒性。相关代码已开源至:github.com/Monsoon49/M…
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
MSLA(Multi-Scale Linear Attention)是专为医学图像分割设计的多尺度线性注意力机制,核心是通过“并行多尺度特征提取+低复杂度线性注意力计算”,同时捕获细粒度局部细节与全局长程依赖,计算复杂度仅为O(N),解决了传统注意力“单尺度局限”或“高复杂度”的痛点。
一、设计目标
- 弥补现有线性注意力的不足:多数线性注意力仅单尺度运算,无法覆盖医学图像中“微观病灶-宏观器官”的尺度差异。
- 平衡局部与全局建模:结合CNN的多尺度特征提取能力与线性注意力的全局依赖捕获优势。
- 控制计算成本:在提升性能的同时,保持低复杂度,适配医学图像(如CT、MRI)的大尺寸输入场景。
二、核心结构与运算步骤
MSLA的运算流程分为两大核心阶段,整体为并行架构(如图1所示):
1. 多尺度特征提取(Multi-Scale Feature Extraction)
- 输入处理:先将输入特征图 (X \in \mathbb{R}^{\sqrt{N} \times \sqrt{N} \times C}) 沿通道维度(C)拆分为4个等份,每份维度为 (\mathbb{R}^{\sqrt{N} \times \sqrt{N} \times \frac{C}{4}})。
- 并行深度卷积:4个分支分别采用不同尺寸的深度卷积(depth-wise convolution)提取多尺度特征:
- 小核(3×3):捕捉细粒度细节(如微小病灶、组织边缘)。
- 中核(5×5、7×7):平衡局部结构与区域关联。
- 大核(9×9):捕获宏观轮廓(如器官整体形态)。
- 残差融合:每个分支的卷积输出与原始输入特征通过残差连接相加,再经过ReLU激活,增强特征表达能力,公式为:
(\overline{X}i = f{k_i \times k_i}^{dwc}(X_i) + X_i)((i=1,2,3,4),(k_i=2i+1) 对应3×3/5×5/7×7/9×9)。
2. 线性注意力计算(Linear Attention Computation)
基于Efficient Attention实现低复杂度全局建模,步骤如下:
- 特征重塑:将每个分支的特征图 (\overline{X}_i) 重塑为token形式 (\overline{X}_i^r \in \mathbb{R}^{N \times \frac{C}{4}}),适配注意力计算。
- Q/K/V投影:通过可学习的线性投影矩阵 (W_{i,h}^q、W_{i,h}^k、W_{i,h}^v),将 (\overline{X}_i^r) 转化为查询(Q)、键(K)、值(V),维度均为 (\mathbb{R}^{N \times d})(d为每个注意力头的维度)。
- 线性注意力运算:重构计算顺序(利用矩阵乘法结合律),将传统自注意力的 ((QK)V) 改为 (Q(KV)),复杂度从O(N²)降至O(N);同时通过映射函数 (\phi(Q) = \sigma_{row}(Q))、(\phi(K) = \sigma_{col}(K))(行/列Softmax)保持与Softmax注意力相近的表征能力。
- 多头融合:每个分支采用多头注意力(multi-head attention),输出通过线性变换 (W_i^O) 融合所有头的特征。
- 跨分支融合:将4个分支的输出特征沿通道维度拼接,再通过1×1卷积压缩通道至原始维度C,最终重塑为token形式 (O \in \mathbb{R}^{N \times C}),完成MSLA模块的整体运算。
核心代码
class MSLA(nn.Module):
def __init__(self, dim, num_heads):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.dw_conv_3x3 = DepthwiseConv(dim // 4, kernel_size=3)
self.dw_conv_5x5 = DepthwiseConv(dim // 4, kernel_size=5)
self.dw_conv_7x7 = DepthwiseConv(dim // 4, kernel_size=7)
self.dw_conv_9x9 = DepthwiseConv(dim // 4, kernel_size=9)
self.linear_attention = LinearAttention(dim = dim // 4, num_heads = num_heads)
self.final_conv = nn.Conv2d(dim, dim, 1)
self.scale_weights = nn.Parameter(torch.ones(4), requires_grad=True)
def forward(self, input_):
b, n, c = input_.shape
h = int(n ** 0.5)
w = int(n ** 0.5)
input_reshaped = input_.view(b, c, h, w)
split_size = c // 4
x_3x3 = input_reshaped[:, :split_size, :, :]
x_5x5 = input_reshaped[:, split_size:2 * split_size, :, :]
x_7x7 = input_reshaped[:, 2 * split_size:3 * split_size:, :, :]
x_9x9 = input_reshaped[:, 3 * split_size:, :, :]
x_3x3 = self.dw_conv_3x3(x_3x3)
x_5x5 = self.dw_conv_5x5(x_5x5)
x_7x7 = self.dw_conv_7x7(x_7x7)
x_9x9 = self.dw_conv_9x9(x_9x9)
att_3x3 = self.linear_attention(x_3x3)
att_5x5 = self.linear_attention(x_5x5)
att_7x7 = self.linear_attention(x_7x7)
att_9x9 = self.linear_attention(x_9x9)
processed_input = torch.cat([
att_3x3 * self.scale_weights[0],
att_5x5 * self.scale_weights[1],
att_7x7 * self.scale_weights[2],
att_9x9 * self.scale_weights[3]
], dim=1)
final_output = self.final_conv(processed_input)
output_reshaped = final_output.reshape(b, n, self.dim)
return output_reshaped
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-C2PSA_MSLA.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
# optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-C2PSA_MSLA',
)
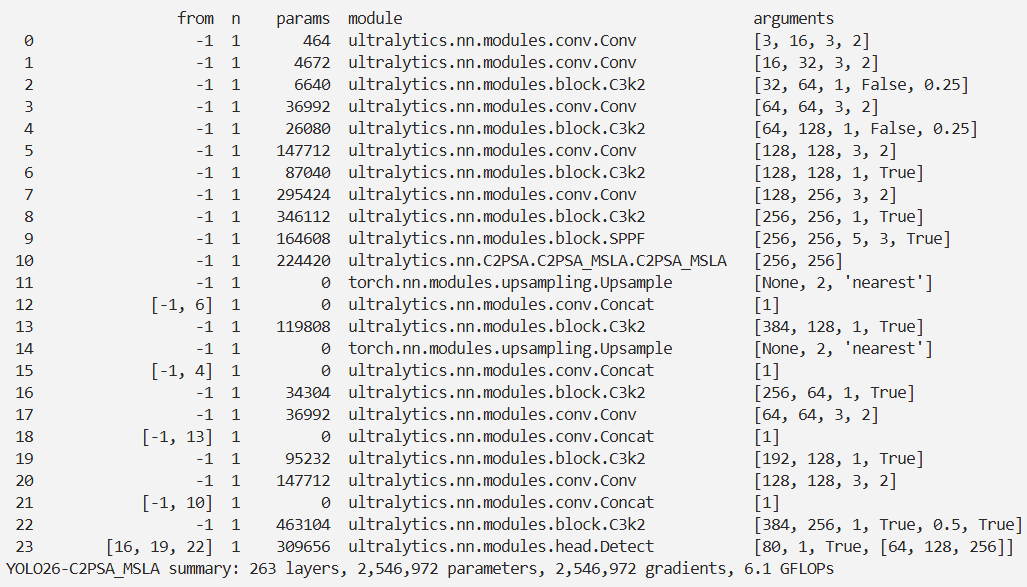
结果