

06、你的第一款AI 思维范式:ReAct
都2026年了,还有人在说 AI 不会算数?
那他的知识结构已经落伍了!
一、链接LLM和Function的桥梁:思维范式
大语言模型(LLM)的出厂设置其实是一个“接龙机器”。
如果你问它:“23 乘以 45 等于多少?”
它并不是像计算器那样在后台运算,而是根据概率在“猜”下一个字是什么。这更像人类的直觉,这导致它经常一本正经地胡说八道。
这就是幻觉问题的根本所在,也是为什么幻觉问题难以解决的原因所在。
思维范式的出现,就是为了强行把 AI 的这种“直觉”拉回到 “逻辑推演” 上来。
二、什么是【思维范式】?
思维范式就是一套强制性的规定,它规定了 AI 在回答问题之前,必须遵循的思考路径和格式结构。
简单来说,拒绝AI 想到啥说啥。
它规定了 AI 在回答问题之前,必须遵循的思考路径和格式结构:
输入 -> 特定结构的思考流程 -> 输出
这里,我们举个例子:
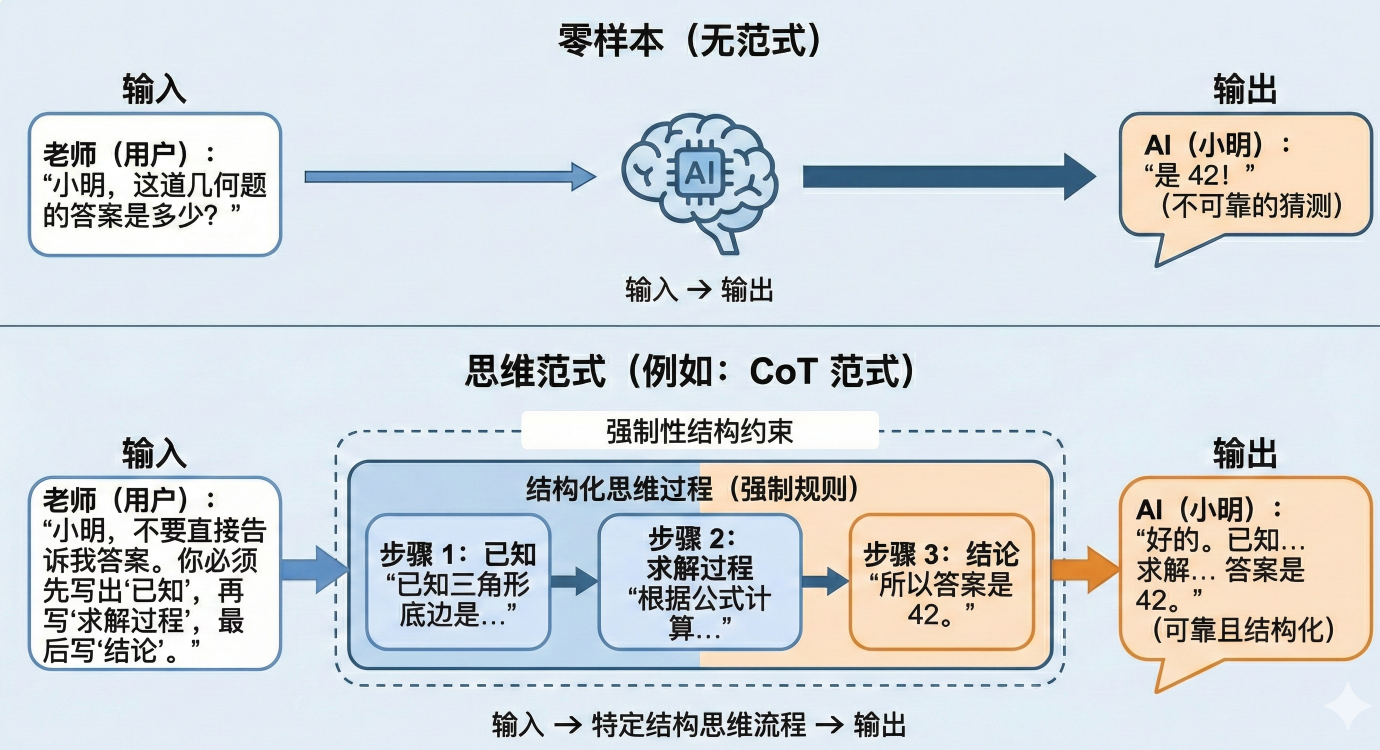
上图这个示意图,解释了【无范式】和【有范式】的AI,在面对计算题时的根本行为差异。
三、一个标准的“思维范式”包含什么?
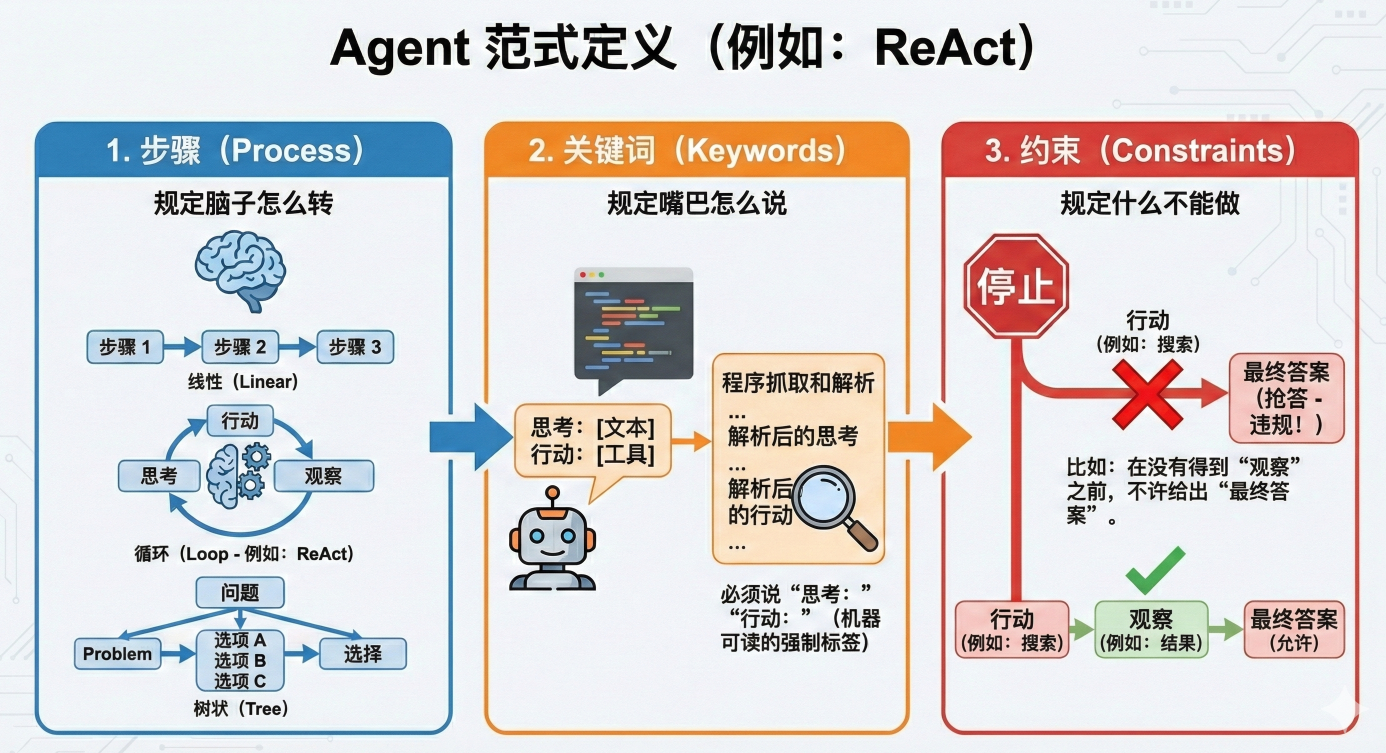
在 Agent 开发中,当我们说我们采用了一种范式(比如 ReAct),意味着我们在代码和提示词里规定了以下三点:
-
特定的步骤(Process): 规定脑子怎么转。是线性的(一步步想)?还是循环的(想-做-想-做)?还是树状的(想出三个方案选一个)?
-
特定的关键词(Keywords): 规定嘴巴怎么说。必须说 Thought:,必须说 Action:。这不仅是给人看的,更是为了方便程序抓取和解析。
-
特定的约束(Constraints): 规定什么不能做。比如“在没有得到 Observation 之前,不许给出 Final Answer”。
基于以上条件,我们可以得出:
AI 的“脑回路”是可以被塑造的,不同的范式适合干不同的活:
CoT 范式(链式思考): 适合做数学题、逻辑推理。强迫它一步步走,防止跳跃。
ReAct 范式(反应式): 适合干活、查资料。强迫它动一下手、看一眼结果。
ToT 范式(树状思考): 适合写小说、搞创意。强迫它多想几个方案,选最好的。
“思维范式”就是我们人类为了让 AI 这种“概率机器”能够像人一样严谨地处理复杂任务,而发明的一套套“紧箍咒”和“流程图”。
四:所以为什么是 ReAct
在 ReAct 出现之前,LLM 主要面临两种极端困境:
-
光想不做(纯推理,如 Chain of Thought): 模型可以写出优美的逻辑推导,但它像个被关在黑盒里的哲学家,无法获取外部世界的实时信息。它会一本正经地告诉你“2024年的奥运会冠军是...”(幻觉),因为它不知道今天其实才2023年。
-
光做不想(纯执行): 简单的脚本可以让模型调用 API,但如果没有推理过程,模型就像无头苍蝇。一旦 API 报错,它不知道该重试、修改参数还是放弃。
ReAct (Reasoning + Acting) 的诞生,就是为了解决这个问题。它的核心哲学非常简单且深刻:
每一次行动之前,都要先思考;每一次行动之后,都要观察结果。
五、ReAct 的特点
ReAct 不仅仅是一个虚无缥缈的“思想”,它在工程实现上已经形成了一套严密的标准规范。
在 LangChain 等框架中(以 hwchase17/react 为代表),它表现为一个无限循环的 While Loop:
二、 深度解构:ReAct 的标准“三步舞” 正如我们之前讨论的,ReAct 不仅仅是一个虚无缥缈的“思想”,它在工程实现上已经形成了一套严密的标准规范。在 LangChain 等框架中(以 hwchase17/react 为代表),它表现为一个无限循环的 While Loop:
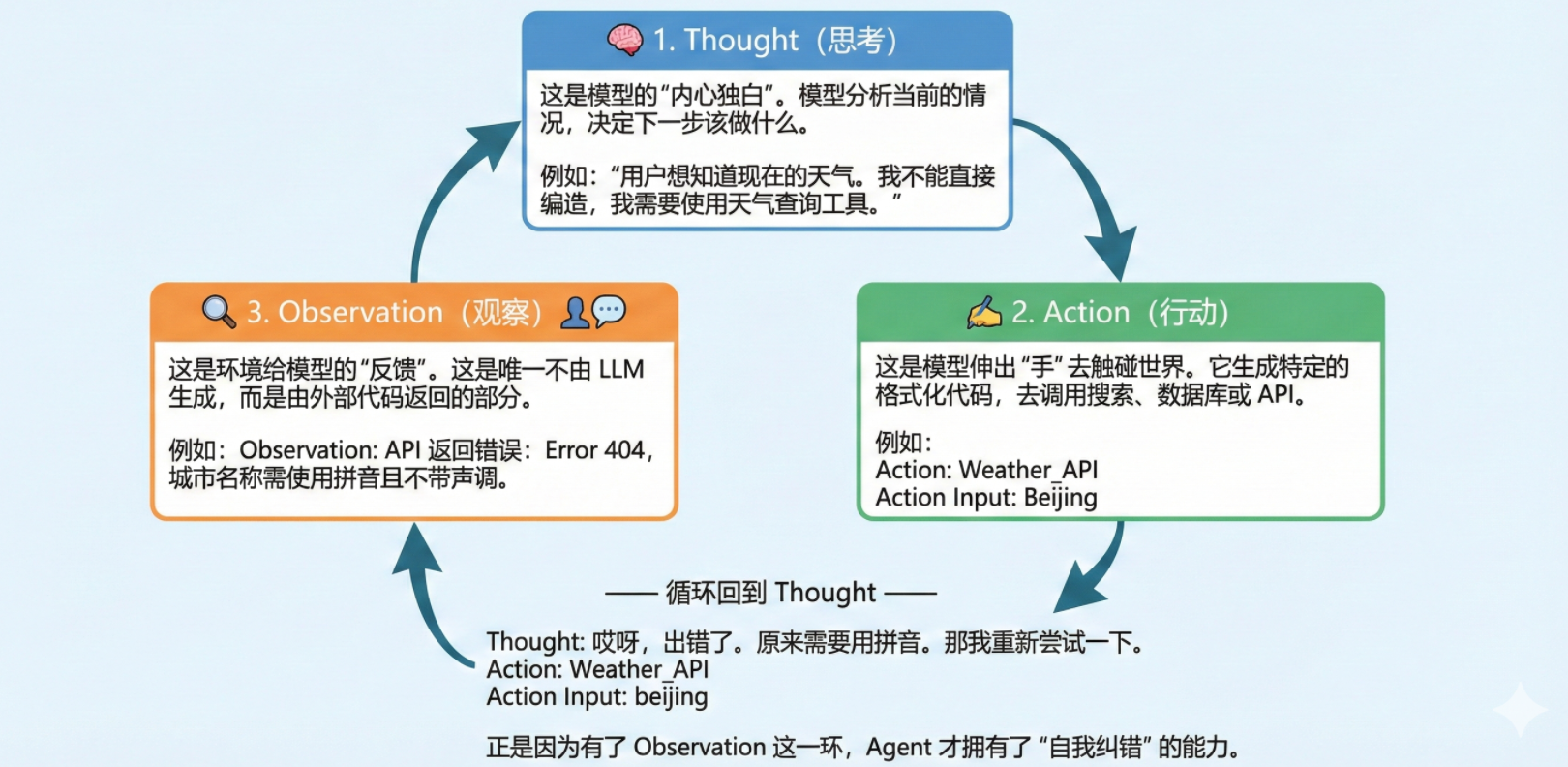
- Thought(思考) 这是模型的“内心独白”。模型分析当前的情况,决定下一步该做什么。
“用户想知道现在的天气。我不能直接编造,我需要使用天气查询工具。”
- Action(行动) 这是模型伸出“手”去触碰世界。它生成特定的格式化代码,去调用搜索、数据库或 API。
行动: 调用Weather_API 参数:北京
- Observation(观察) 这是环境给模型的“反馈”。这是唯一不由 LLM 生成,而是由外部代码返回的部分。
观察: API 返回错误:Error 404,城市名称需使用拼音。
—— 循环回到 Thought 思考 ——
思考: 哎呀,出错了。原来需要用拼音。那我重新尝试一下。 > 行动: 调用Weather_API 参数 beijing
正是因为有了 Observation(观察) 这一环,Agent 才拥有了“自我纠错”的能力。
六、认识一下其他流行的【思维范式】
掌握了 ReAct 只是入门。在解决更复杂的问题时,AI 科学家们还发明了其他思维范式。我们可以将 ReAct 作为坐标原点,看看其他的流派:
| 思维范式 | 核心逻辑 | 适用场景 | 优缺点对比 |
|---|---|---|---|
| CoT (Chain of Thought) | 纯思考 一步步推理 -> 答案 | 纯逻辑数学题、常识推理 | ❌ 无法联网,有幻觉 ✅ 速度快,无需工具 |
| ReAct | 边想边做 思考-行动-观察 -> 循环 | 资料检索、API 调用、通用助理 | ✅ 容错率高,最稳健 ❌ 步骤多,消耗 Token,速度慢 |
| Plan-and-Solve (AutoGPT式) | 先计划,后执行 列出任务清单 -> 逐个击破 | 复杂长任务(如:写一个游戏) | ✅ 全局观强,不迷路 ❌ 灵活性差,计划赶不上变化 |
| Reflexion | 事后反思 执行 -> 失败 -> 反思原因 -> 重试 | 编写代码、高难度解题 | ✅ 自我进化能力强 ❌ 极其消耗 Token |
| ToT (Tree of Thoughts) | 思维树 生成多个方案 -> 选最好的 -> 继续 | 创意写作、解谜(24点游戏) | ✅ 探索性最强,能找到最优解 ❌ 极慢,工程复杂度高 |
七、ReAct 的现状:从“显学”到“本能”
我们在开发中经常提到 hwchase17/react 这个提示词模板,它在很长一段时间内是 Agent 的标准配置。
但在 2024 年以后的新时代,事情发生了一点微妙的变化:
-
对于开源/小模型: ReAct 依然是绝对标准。你需要明确地在 Prompt 里写上 "Question/Thought/Action" 的格式要求,模型才能听懂。
-
对于顶尖模型(GPT-4o, Claude 3.5): ReAct 正在被内化。通过 Native Function Calling(原生函数调用),模型已经把“思考-行动”的循环刻在了权重里。你不再需要写复杂的 ReAct 提示词,直接给它工具,它就会自动展现出类似 ReAct 的行为。
无论技术如何迭代,ReAct 都是理解 AI Agent 运行机制的“钥匙”。
当你第一次看到控制台里打印出: Thought: 我需要搜索一下... Observation: 搜索到了结果... Final Answer: 答案是...
那一刻,你构建的不仅仅是一段代码,而是一个拥有了感知(Observation)和行动(Action)能力的初级数字生命。这就是 ReAct 的魅力所在。
八、如写写代码?
因为本章第七节内容的原因,现在的 DeepSeek(以及 GPT-4、Claude 3.5)已经把 ReAct 的能力“吃”进了模型内部,变成了本能,不再需要你用“说明书”(提示词)去教它了。
这个技术叫做 Native Function Calling(原生函数调用)。欸?和我们上一章的内容结合起来了。
在目前,一个标准的 ReAct 场景下的伪代码,大概是这样的:
def run_native_agent(query, tools_map, tools_schema):
# 初始化消息历史
messages = [{"role": "user", "content": query}]
while step < max_steps:
# 1. API 调用 (直接传 tools,模型内部处理 ReAct 逻辑)
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools_schema
)
msg = response.choices[0].message
# 2. 终止条件:如果没有工具调用请求,说明是最终答案
if not msg.tool_calls:
return msg.content
# 3. 记录意图:将模型 "想调工具" 的决定压入历史
messages.append(msg)
# 4. 执行与反馈 (Acting + Observation)
for tool in msg.tool_calls:
# 自动解析 JSON 参数
func_name = tool.function.name
args = json.loads(tool.function.arguments)
# 执行本地代码
result = tools_map[func_name](**args)
# 闭环:以 "tool" 角色回填观察结果
messages.append({
"role": "tool",
"tool_call_id": tool.id, # ID 必须对应
"content": str(result)
})
# 循环继续,下一轮 API 调用时模型就能看到 tool 的结果
对,是一个 while 循环,因此,ReAct又有人把它称为“ReAct Loop”。
中文暂时没有特别权威的叫法,我习惯叫它:
思动循环。
下一步预告
经过两节课知识的武装,我们已经变得非常强大。
下节课,我们将直接使用本节课和上节课学到的知识进行实战!
目标:
一个可以帮你自动规整桌面的桌面小秘书!
敬请期待!

