

今天凌晨,AI 圈炸了。
OpenAI 和 Anthropic 几乎同时发布新一代编程模型——这不是巧合,这是一场正面硬刚。
GPT-5.3-Codex:全面碾压
OpenAI 这次直接甩出了三张王炸:
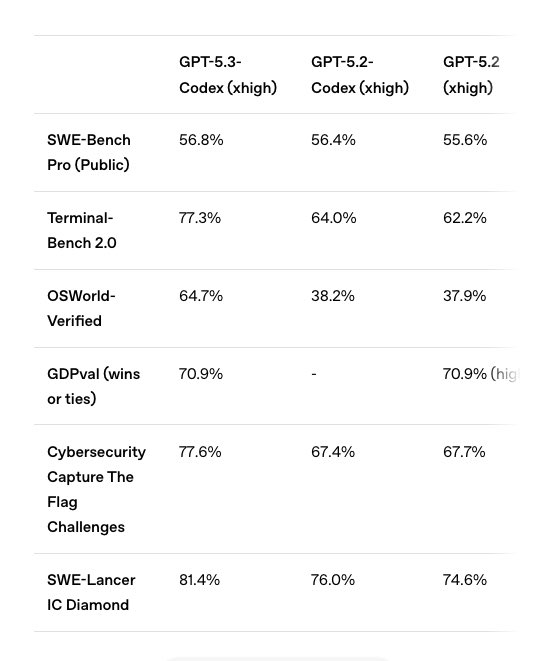
SOTA 霸榜——在 SWE-Bench Pro 和 Terminal-Bench 两大权威评测上达到全新 SOTA(State of the Art),业界第一实至名归。
Token 减半——同样的任务,token 消耗直接减半。这意味着什么?成本腰斩,速度翻倍。
长时任务 + 实时干预——这是本次最大亮点。模型支持长时任务执行,中途你可以随时介入引导,而且不会丢失上下文。AI 写到一半你觉得方向偏了?随时调整,无缝衔接。
速度提升 25%——整体推理速度提升四分之一。
自己帮自己 debug——模型具备了自我调试和部署能力,写完代码自己测,自己修 bug,自己部署。一条龙服务。
Claude Opus 4.6:以智取胜
Anthropic 的打法完全不同,他们追求的是"智能"而非单纯的"快"。
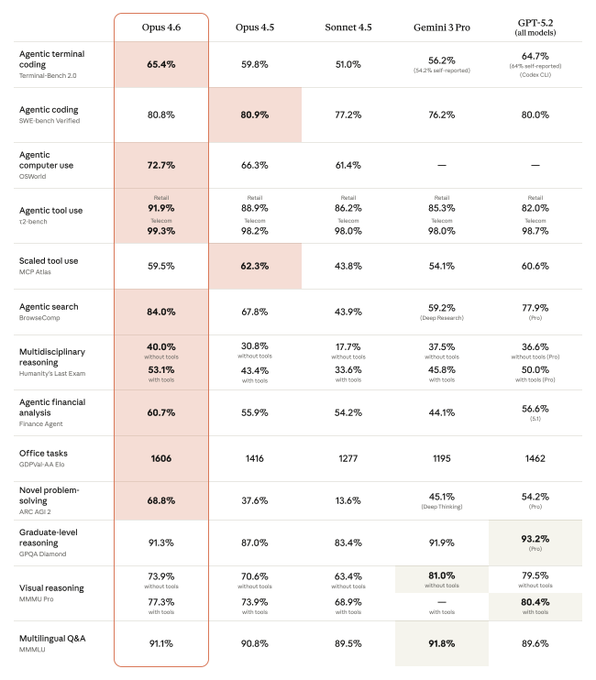
100 万 token 上下文——这是首个达到此级别的 Opus 模型。什么概念?可以一次性喂进去几十本技术书。
上下文翻 5 倍——相比上一代,上下文容量直接提升 5 倍。
记忆力提升近 4 倍——能够记住更多信息,在超长对话中依然保持连贯。
多代理协作——这是 Claude Code 的杀手锏。多个 AI 代理协同工作,分工明确,效率倍增。
知道自己该什么时候深度思考——这听起来有点玄,但实际意义重大。模型具备了"元认知"能力,知道什么时候该快,什么时候该慢,什么时候该停下来深入思考。
谁更强?
如果用一句话总结:
GPT-5.3-Codex 是一把快刀——评测数据碾压、token 效率翻倍、速度快、能自己 debug。适合追求极致性能的场景。
Claude Opus 4.6 是一位智者——超长上下文、多代理协作、懂得何时思考。适合需要深度推理和长期任务管理的场景。
但说实话,对于我们开发者来说,这场竞争没有输家。
AI 编程的能力正在以肉眼可见的速度进化,无论是 OpenAI 还是 Anthropic,都在推着整个行业向前狂奔。
好消息是:我们可以坐享其成。
欢迎关注公众号 FishTech Notes,一块交流使用心得!
