


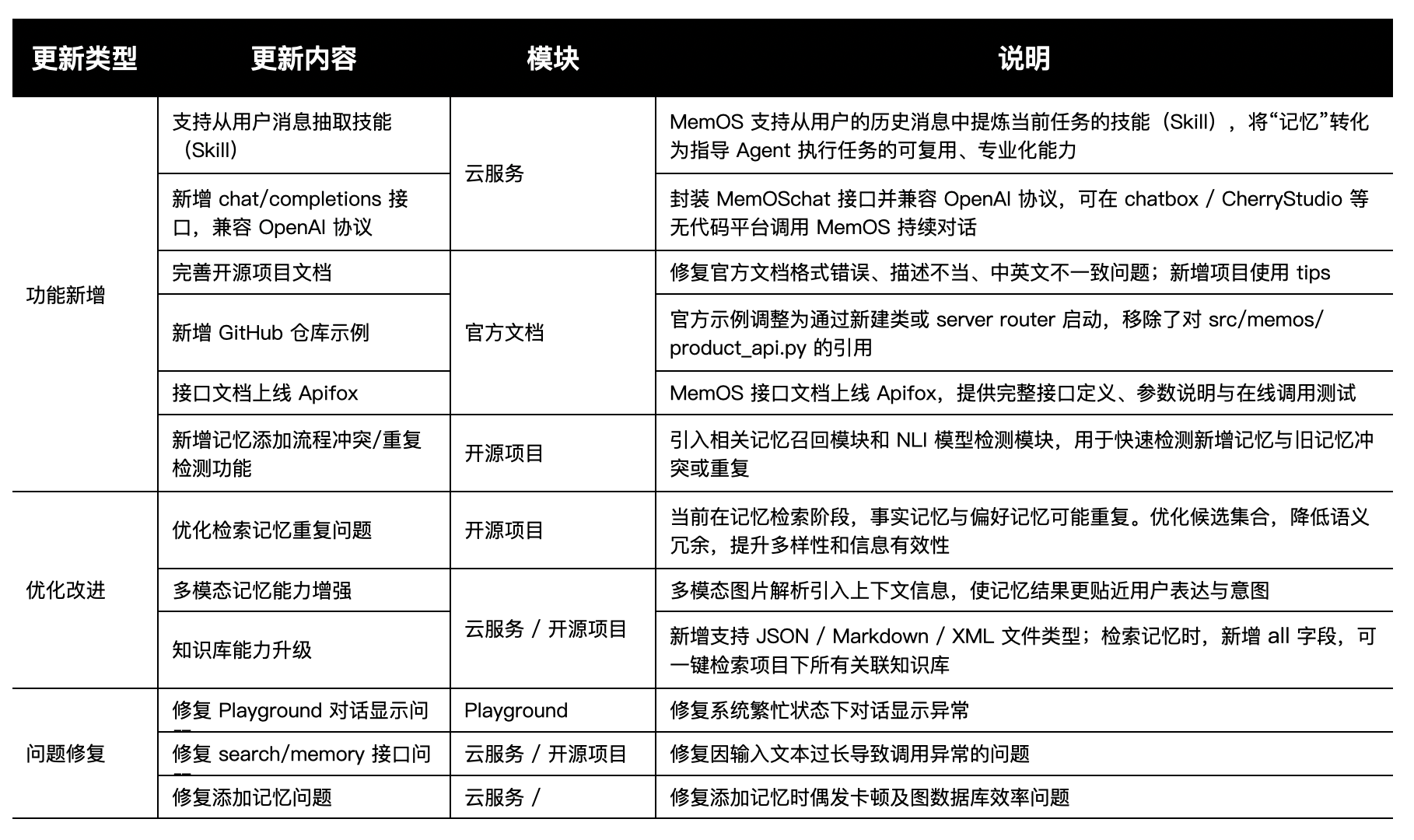
本次更新,MemOS 对记忆和知识管理能力进行了多方面提升,让系统更加“聪明”和“贴心”。
我们围绕 “技能化记忆(Skill)能力” 与 “记忆系统算法与工程能力升级” 两条主线,对云服务和开源项目进行了优化。本次更新不仅引入了 从用户历史消息自动生成 Skill 的能力,还在多模态记忆、检索优化、知识库支持、接口体系和工程文档等方面进行了全面升级。
本次发布汇总
1. 文档更全、示例更详细
本次更新完成了对 MemOS 开源仓库和官网文档 的集中更新与校准,目标是:
- 所有官方 examples 在新架构下可直接运行;
- 官网文档与最新代码行为完全对齐;
- 修复隐藏 bug,降低踩坑成本。
更新内容:
- 修复文档格式错误、描述偏差、中英文不一致;
- 新增使用 tips 和工程实践建议;
- 示例工程调整为通过新建类或 server router 启动;
- 移除对旧 product_api.py 的直接依赖。
👉 开源项目官方文档:www.memos-docs.openmem.net/cn/open_sou…
👉 GitHub 项目示例: www.github.com/MemTensor/M…
2. 从“记忆”到“技能(Skill)”:
从用户历史消息中自动抽取技能(Skill)
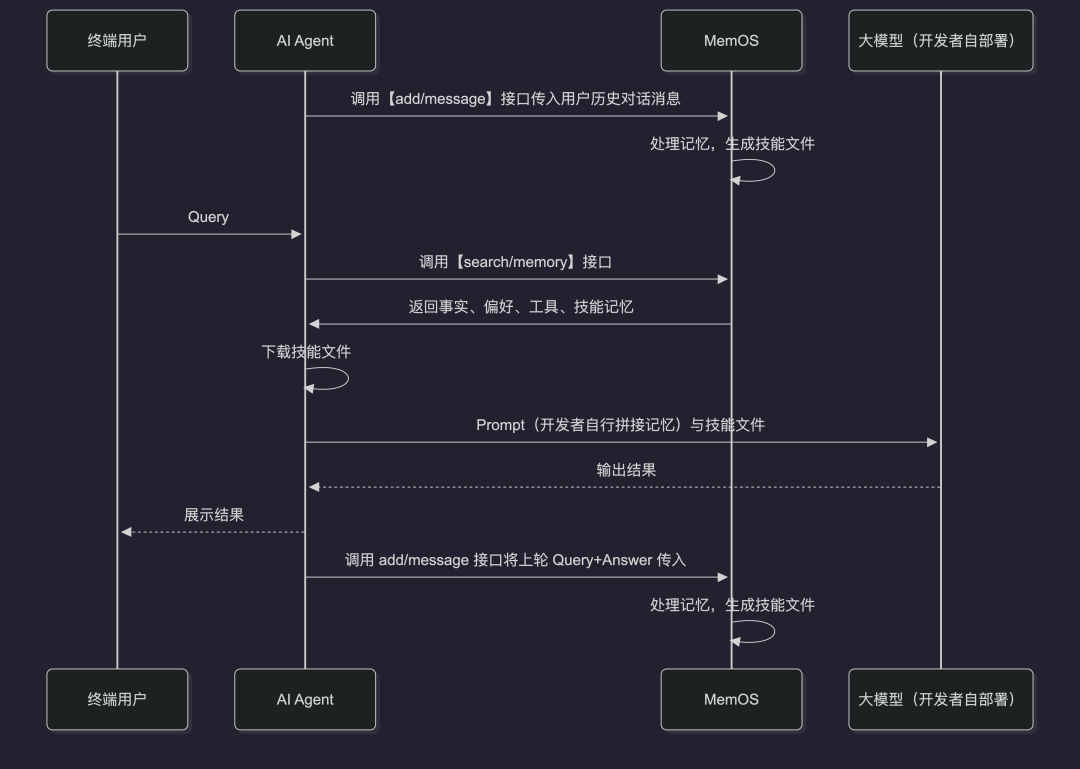
现在,
MemOS 已支持 Skill,用于将长期对话中沉淀的任务经验,转化为可复用、可执行的 Agent 能力单元。
Skill 已在 MemOS 的核心记忆流程中集成,可在不改变现有 Agent 架构的前提下使用。
系统可从长期对话中识别任务模式与解决路径,将零散记忆转化为可复用、结构化的执行能力模块,使记忆不再只是上下文数据,而成为指导 Agent 行为的专业能力资产。
转化路径:
用户历史对话 → 任务结构抽取 → 能力模式归纳 → Skill 生成 → Agent 调度执行
使用教程:一次把「做事经验」变成能力:MemOS Skill 上线啦!
3. 多模态记忆能力增强
在真实对话中,图片通常与文本和历史对话高度相关。此前图片解析缺乏上下文约束,容易导致记忆碎片化。
我们针对 Mem Reader 的多模态记忆处理能力进行了优化全面升级,不仅文字,图片信息也能被系统理解,还能结合对话上下文形成记忆,让助手对你的需求理解更准确。
3.1 多模态图片解析引入上下文信息
- 在图片解析阶段注入对话上下文(context);
- LLM 在分析图片时结合:
- 用户当前输入文本;
- 历史对话内容;
- 输出更贴近语义的图片记忆。
3.2 记忆结果更贴近用户表达与意图
- 抽取图像客观信息;
- 同步捕捉用户当前语境的主观表达;
- 保留可长期使用的偏好/行为线索。
添加消息示例(片段):
"messages": [
{"role": "user","content":"我是小王。"},
{"role": "assistant","content":"小王,你好!你在做什么?"},
{"role": "user","content": [{"type": "text","text": "我发给你,我正在吃水果.这是我的最爱"}]},
{"role": "user","content": [{"type": "image_url","image_url": {"url": "https://cdn.memtensor.com.cn/img/mango-picture_compressed.jpeg"# 一张芒果的图片}}]}
]
检索记忆示例:
[conv:session_id_001] id=0507ede9-b53a-43e1-b6b6-3026361eaacb | memory=用户提到正在吃水果,并表示这是他们的最爱,结合图像内容,推测用户可能对芒果有特别的喜好或情感连接。
[conv:session_id_001] id=5456095a-f7f1-4dd7-bb22-9bc0aa40edae | memory=在2026年1月23日下午2:27,小王提到他正在吃水果,并表示这是他的最爱。同时,他分享了一张水果的图片。
[conv:session_id_001] id=f2e26d24-2353-45f4-916d-03d52a2eb590 | memory=图像中展示了一只完整的芒果和一部分已切块的芒果,切块呈现出鲜亮的黄色,表面光滑,整体看起来新鲜可口。旁边还有几片芒果果肉和一个小碗,碗中装有切好的芒果块,周围有绿色的叶子作为点缀,营造出自然的氛围。
4. 检索记忆去重与多样性优化
记忆检索现在变得更加智能,系统会自动去掉重复或冲突的信息,让回答更精准、更有用。
之前在记忆检索阶段,同一事实或主题可能被多次召回,导致冗余记录、信息密度下降、下游生成重复内容等问题。
本次优化降低了语义重复,提高了候选集合多样性和有效信息覆盖。升级后的核心流程如下:
1. 候选召回
给定 Query,系统返回一组候选记忆(包含相关性分数和 embedding)。在保证整体相关性的前提下,选出 Top-K 结果,尽量避免内部语义重复,同时确保重要信息覆盖。
2. MMR 去重与排序
- 使用 MMR(Maximal Marginal Relevance)对候选集合做选集和重排。
- 在“相关性”和“多样性”之间平衡,避免相关性低的项被多样性惩罚过度压制。
3. 关键策略
- 先多取,再去重:扩大候选池,避免 Top-K 早期被同簇占满;
- 相关性优先预选:高相关候选先保留,避免多样性惩罚压制重要信息;
- 输出顺序按相关性:MMR 只决定选集,最终结果按原始相关性排序,让下游先看到最关键证据。
5. 记忆冲突 / 重复检测
系统现在可以自动判断新增的对话或信息是否与已有记忆重复或冲突。
当你多次告诉助手同一件事或者修正之前的偏好时,MemOS 会自动整合信息,去掉重复、保留最新状态。现在,每次查询或使用记忆时得到的结果会更加精准,避免出现前后矛盾的回答。
新增模块:
- 相关记忆召回模块;
- NLI 冲突检测模块。
开源示例:
# 1. 初始化 (假设 graph_db 和 embedder 已经准备好)
retriever = PreUpdateRetriever(graph_db, embedder)
# 2. 构造查询对象
source = SourceMessage(role="user", lang="en")
metadata = TreeNodeTextualMemoryMetadata(sources=[source], memory_type="WorkingMemory")
item = TextualMemoryItem(memory="I like apples", metadata=metadata)
# 3. 执行检索
# user_name: 用户ID
# top_k: 返回结果数量
results = retriever.retrieve(item, user_name="alice", top_k=5)
# 4. 查看结果
for res in results:
print(res.memory)
NLI Server 启动:
"""
首先需要启动 server:
### 1. Basic Start
\`\`\`bash
python -m memos.extras.nli\_model.server.serve
\`\`\`
### 2. Configuration
You can configure the server by editing config.py:
- \`HOST\`: The host to bind to (default: \`0.0.0.0\`)
- \`PORT\`: The port to bind to (default: \`32532\`)
- \`NLI\_DEVICE\`: The device to run the model on.
- \`cuda\` (Default, uses cuda:0if available, else fallback to mps/cpu)
- \`cuda:0\` (Specific GPU)
- \`mps\` (Apple Silicon)
- \`cpu\` (CPU)
"""
# 调用 client
base\_url="http://127.0.0.1:32532" # server 的位置
client = NLIClient(base\_url=base\_url)
source = "I like apples."
targets = ["I love fruit.", "I hate apples."]
results = client.compare\_one\_to\_many(source, targets)
6. 知识库能力升级
现在,我们支持更多文档类型,并可以跨项目统一搜索,可以更方便的获取信息。同时新增接口支持无代码平台调用,让你使用更简单、流畅:
- 支持 JSON / Markdown / XML 文件类型;
- 检索新增
all字段,可一键跨项目知识库检索。
调用示例(片段):
{
"query": "我国庆想出去玩,帮我推荐个没去过的城市,以及没住过的酒店品牌",
"user\_id": "memos\_user\_123",
"conversation\_id": "0928",
"knowledgebase\_ids":[
"all"
]
}
7. chat/completions 接口,兼容 OpenAI 协议
现在 MemOS 可以像 OpenAI 接口一样被调用,这意味着你可以在多种无代码 AI 平台上直接和助手对话,无需写代码就能体验持续对话功能,使用更简单、更流畅。
- 封装 MemOS chat 接口
- 无需代码即可在 Chatbox / CherryStudio 等平台使用
调用示例:
client = OpenAI(api_key="mpg-xxxxxx", base_url="https://memos.memtensor.cn/api/openmem/v1")
stream = client.chat.completions.create(
model="deepseek-r1",
messages=[{"role": "user", "content": "你好,你还记得我是谁吗"}],
stream=True,
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
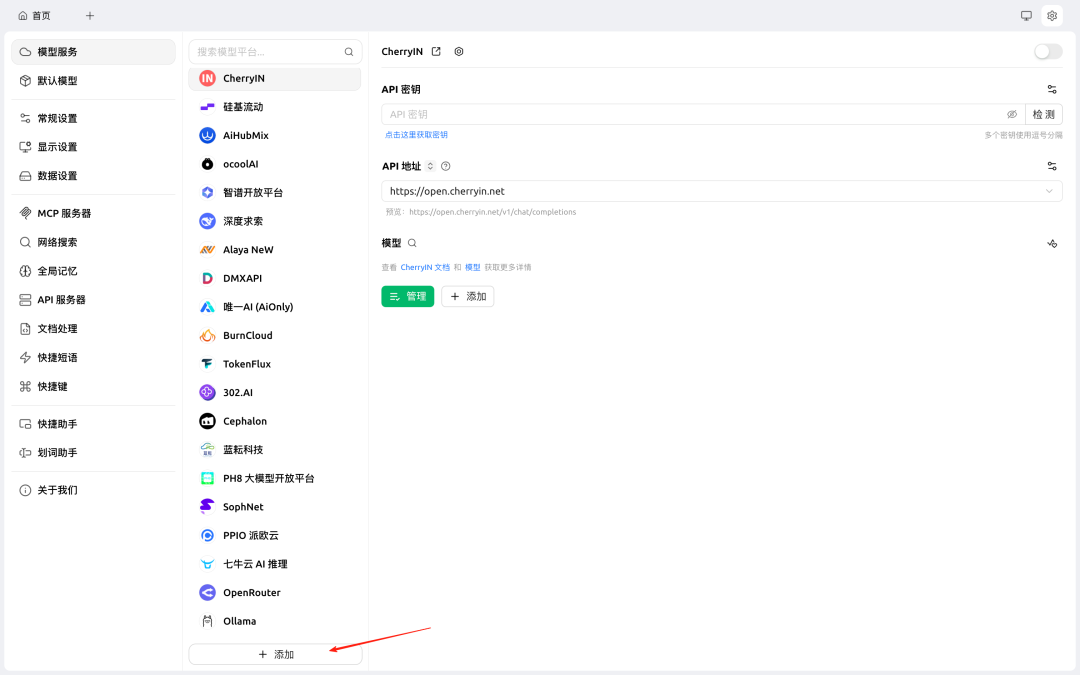
cherrystudio 使用示例
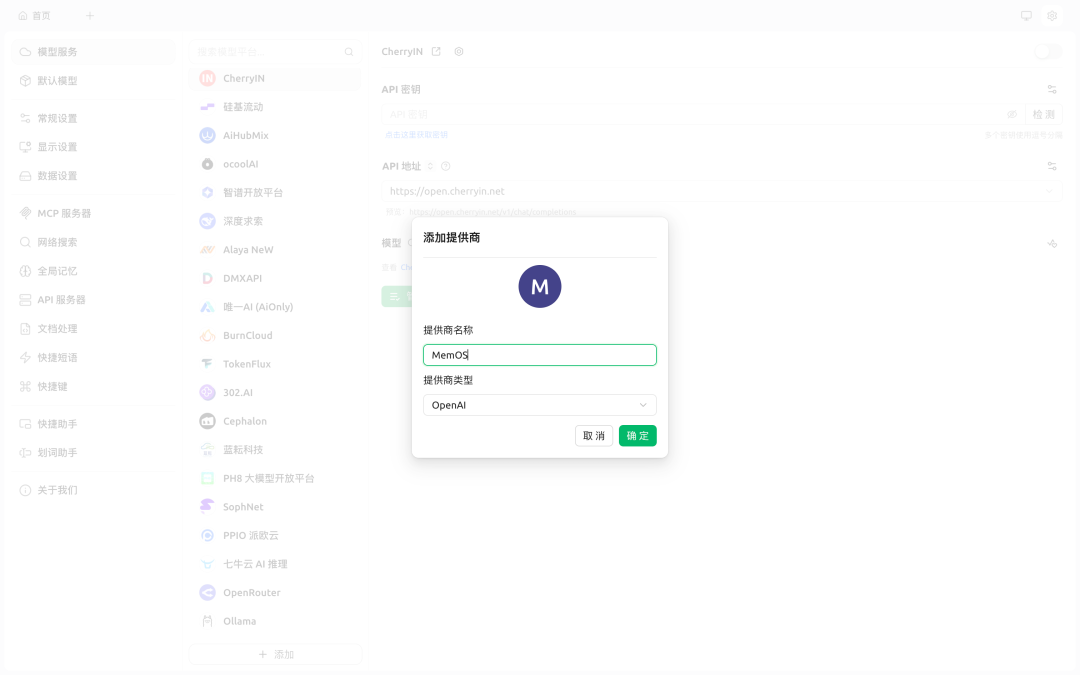
Step 1: 打开设置,点击添加模型平台,填写
- 提供商名称 - MemOS;
- 提供商类型 - OpenAI。
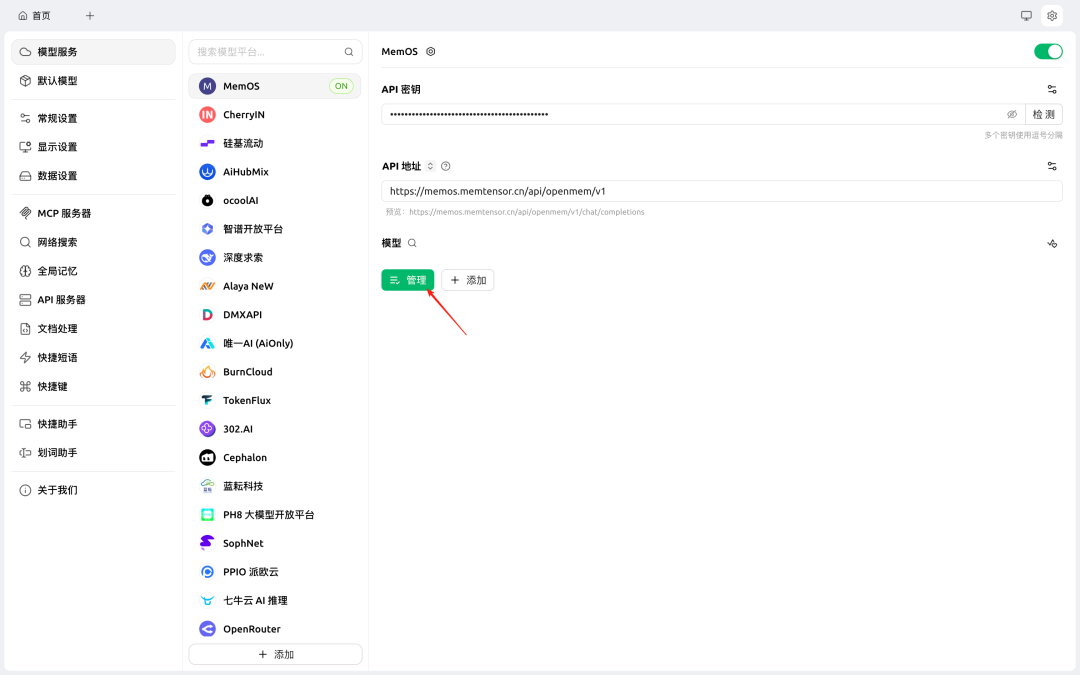
Step 2: 填写密钥、地址
- API 密钥:从控制台获取 API Key;
- API 地址:memos.memtensor.cn/api/openmem…。
- 点击管理模型,添加所有选项
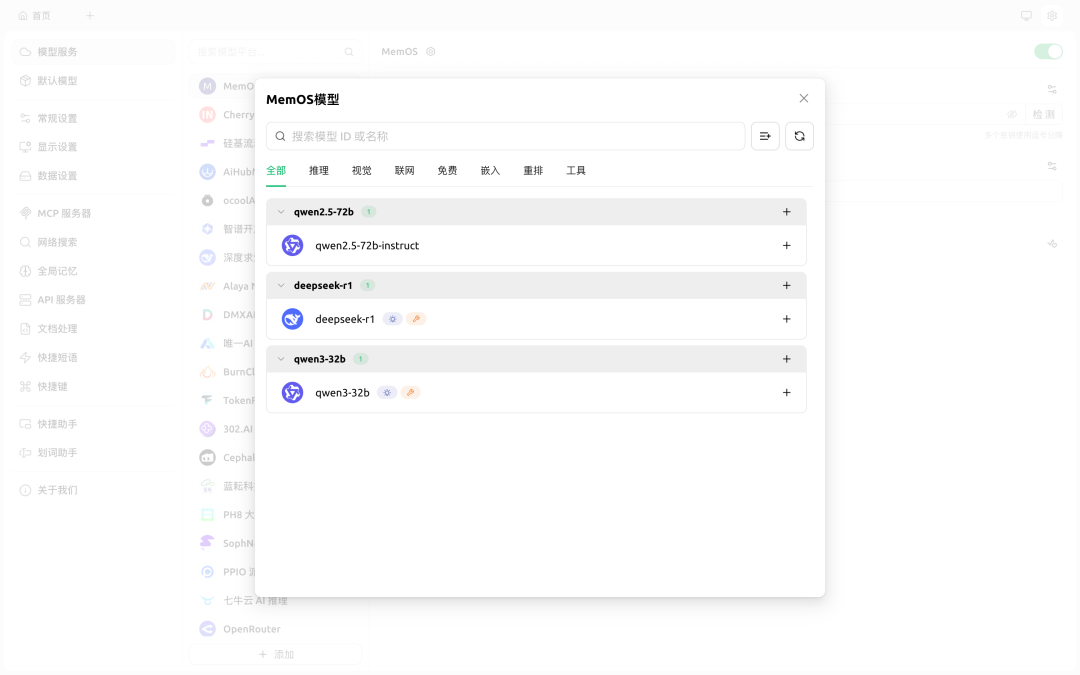
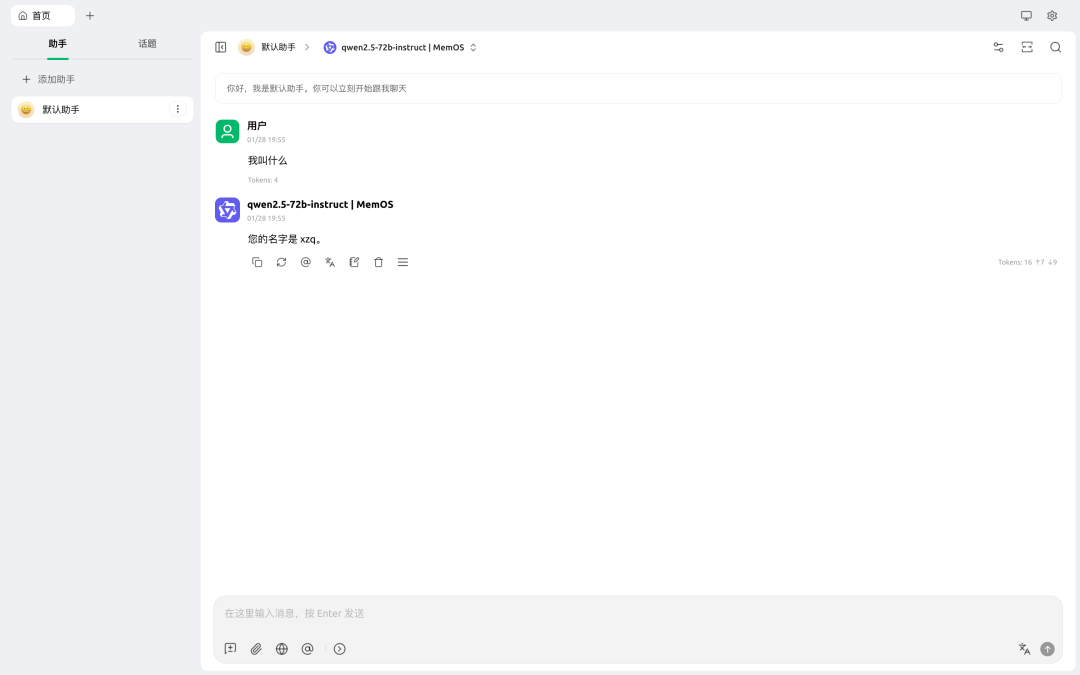
Step 3: 现在你可以和助手聊天了,它将始终“记得你”。
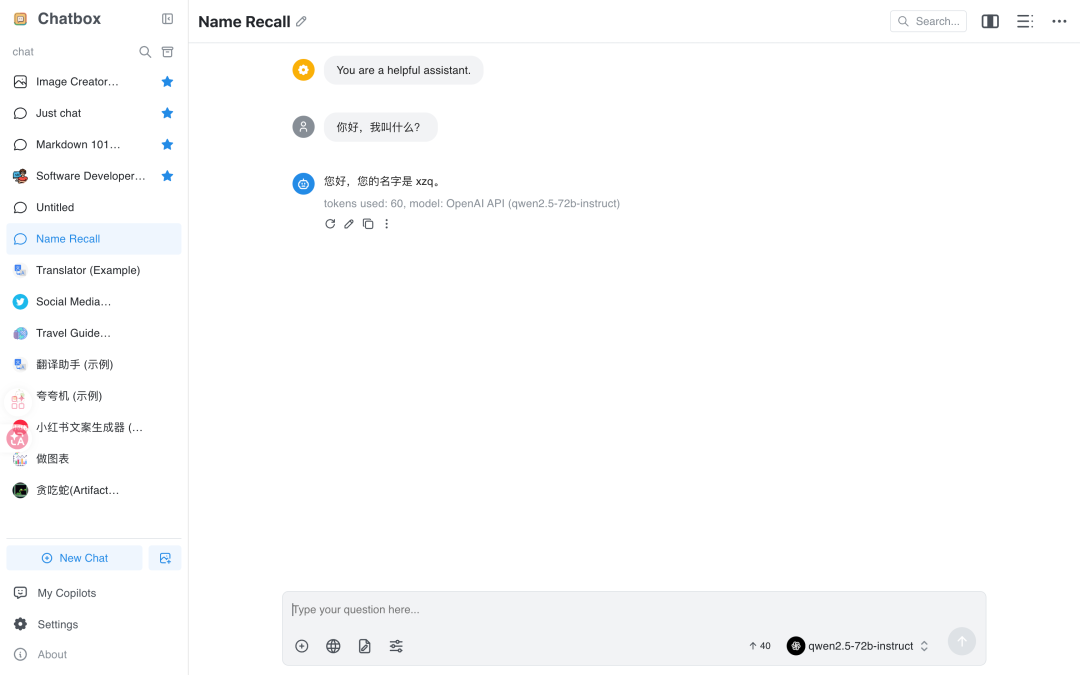
chatbox 使用示例‸
Step 1: 参考以上方式,在 Chatbox 中配置 MemOS,同样可以完成对话。
8. MemOS 接口文档上线 Apifox
MemOS 提供了一个在线文档和调试平台,开发者可以直接查看系统功能、测试接口和参数设置。即便是第一次使用 MemOS 的用户,现在也可以更容易的了解系统能做什么、快速尝试新功能!
👉 欢迎点赞、收藏:5iwo3tluvy.apifox.cn
9. 开源社区更新(CHANGE LOG)
New Features / 新功能
- 官网开源文档更新;
- GitHub 仓库示例更新;
- 知识库支持 JSON / Markdown / XML;
- 接口文档上线 Apifox;
- 新增 add 时相关记忆召回模块;
- 新增 NLI 模型支持冲突/重复检测。
Improvements / 改进
- 多模态记忆能力增强(图文协同处理);
- 知识库检索支持
all字段; - 减少检索阶段事实记忆与偏好记忆重复。
Bug Fixes / 缺陷修复
- 修复添加阶段去重效率问题;
- 修复检索长文本输入异常。
✨ 老规矩!
🚀 一键体验云平台
立即进入 MemOS 云平台,体验毫秒级记忆与偏好召回能力。
memos-dashboard.openmem.net/quickstart/…
💾 如果你喜欢我们的工作,请一键三连:
⭐️ Star 🍴 Fork 👀 Watch
并欢迎通过 Issue 提交你的使用反馈、优化建议或 Bug 报告。
关于 MemOS
MemOS 为 AI 应用构建统一的记忆管理平台,让智能系统如大脑般拥有灵活、可迁移、可共享的长期记忆和即时记忆。
作为记忆张量首次提出“记忆调度”架构的 AI 记忆操作系统,我们希望通过 MemOS 全面重构模型记忆资源的生命周期管理,为智能系统提供高效且灵活的记忆管理能力。
