前言
本文介绍了高斯上下文变换器(GCT)模块在YOLO26中的结合应用。GCT是一种新型通道注意力模块,其核心假设全局上下文与注意力激活关系预先确定,通过全局上下文聚合、归一化和高斯上下文激励三个操作实现。它有参数自由的GCT - B0和可学习标准差的GCT - B1两个版本。我们将GCT集成到YOLO26的检测头中,并进行相关注册和配置。实验表明,GCT能在ImageNet和MS COCO等基准测试中,为各种骨干网络和检测器带来性能提升。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@[TOC]
介绍

摘要
近期,大量通道注意力模块被提出,旨在增强深度卷积神经网络(CNN)的表示能力。这些方法通常借助全连接层或线性变换来学习全局上下文与注意力激活之间的关系。然而,我们的实验证实,即便引入大量参数,这些注意力模块或许仍难以出色地学习这种关系。本文中,我们假定这种关系是预先确定的。基于该假设,我们提出了一种简单且高效的通道注意力模块,即高斯上下文变换器(Gaussian Context Transformer,GCT),其利用满足预设关系的高斯函数实现上下文特征的激发。依据高斯函数的标准差是否可学习,我们开发了GCT的两个版本:GCT - B0和GCT - B1。GCT - B0是一个无参数的通道注意力模块,通过固定标准差来实现,它直接将全局上下文映射到注意力激活,无需进行学习;与之相对,GCT - B1是一个有参数的版本,其自适应地学习标准差以提升映射能力。在ImageNet和MS COCO基准测试上开展的大量实验显示,我们的GCT在各类深度CNN和检测器上均能实现稳定的性能提升。与一系列最先进的通道注意力模块(如SE和ECA)相比,我们的GCT在有效性和效率方面均更具优势。
文章链接
论文地址:论文地址
**代码地址:**代码地址
基本原理
Gaussian Context Transformer(GCT)是一种新型的通道注意力模块,旨在提高深度卷积神经网络(CNN)的表现力。该方法由Ruan等人提出,主要通过使用高斯函数来实现上下文特征的激励,从而简化了传统通道注意力机制的复杂性。
主要内容
-
研究背景: 传统的通道注意力模块通常通过全连接层或线性变换来学习全局上下文与注意力激活之间的关系。然而,研究表明,尽管引入了许多参数,这些注意力模块可能并未有效学习这种关系。
-
核心假设: GCT的核心假设是,全局上下文与注意力激活之间的关系是预先确定的,而不是通过学习获得的。基于这一假设,GCT提出了一种简单而高效的通道注意力机制。
-
GCT的结构: GCT由三个主要操作组成:
- 全局上下文聚合(GCA):通过全局平均池化来获取通道级别的统计信息,以帮助网络捕捉长距离依赖关系。
- 归一化:对聚合后的全局上下文进行归一化处理。
- 高斯上下文激励(GCE):使用高斯函数对全局上下文进行激励,公式为: 其中,是高斯函数的标准差,可以是常数或可学习的参数。
-
参数自由的GCT: 当标准差为常数时,GCT被称为GCT-B0,这是一种参数自由的通道注意力模块。研究表明,GCT-B0在多个任务上表现优异,且参数和计算量几乎没有增加。
-
实验结果: 在ImageNet和MS COCO等基准测试上进行的综合实验表明,GCT在各种骨干网络和检测器上均能显著提高性能,超越了其他通道注意力模块。
核心代码
class GCT(nn.Module):
def __init__(self, channels, c=2, eps=1e-5):
super().__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.eps = eps
self.c = c
def forward(self, x):
y = self.avgpool(x)
mean = y.mean(dim=1, keepdim=True)
mean_x2 = (y ** 2).mean(dim=1, keepdim=True)
var = mean_x2 - mean ** 2
y_norm = (y - mean) / torch.sqrt(var + self.eps)
y_transform = torch.exp(-(y_norm ** 2 / 2 * self.c))
return x * y_transform.expand_as(x)
实验
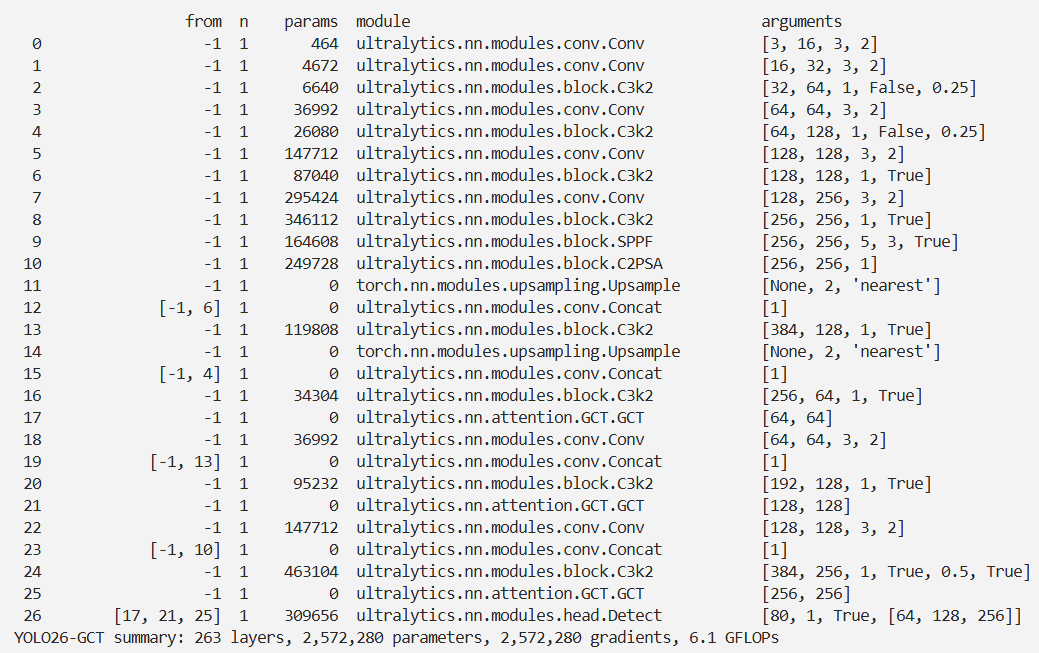
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-GCT.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
# optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-GCT',
)
结果