前言
本文介绍了可变形大核注意力(D-LKA Attention)及其在YOLO26中的结合。D-LKA Attention是一种简化的注意力机制,采用大卷积核利用体积上下文信息,通过可变形卷积灵活调整采样网格,适应多样数据模式。它有2D和3D版本,3D版本在跨深度数据理解上表现出色,共同构成了D-LKA Net架构。我们将D-LKA Attention集成进YOLO26,在模型的检测头部分引入deformable_LKA_Attention模块。实验表明,该方法在分割任务上表现优于现有方法,提升了模型的检测性能。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏
@[TOC]
介绍

摘要
医学图像分割在Transformer模型的应用下取得了显著进步,这些模型在捕捉远距离上下文和全局语境信息方面表现出色。然而,这些模型的计算需求随着token数量的平方增加,限制了其深度和分辨率能力。大多数现有方法以逐片处理三维体积图像数据(称为伪3D),这忽略了重要的片间信息,从而降低了模型的整体性能。为了解决这些挑战,我们引入了可变形大核注意力(D-LKA Attention)的概念,这是一种简化的注意力机制,采用大卷积核以充分利用体积上下文信息。该机制在类似于自注意力的感受野内运行,同时避免了计算开销。此外,我们提出的注意力机制通过可变形卷积灵活变形采样网格,使模型能够适应多样的数据模式。我们设计了D-LKA Attention的2D和3D版本,其中3D版本在跨深度数据理解方面表现出色。这些组件共同构成了我们新颖的分层视觉Transformer架构,即D-LKA Net。在流行的医学分割数据集(如Synapse、NIH胰腺和皮肤病变)上对我们模型的评估表明其优于现有方法。我们的代码实现已在GitHub上公开。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
可变形大核注意力(Deformable Large Kernel Attention, D-LKA Attention)是一种简化的注意力机制,采用大卷积核来充分利用体积上下文信息。该机制在类似于自注意力的感受野内运行,同时避免了计算开销。通过可变形卷积灵活变形采样网格,使模型能够适应多样的数据模式,增强对病灶或器官变形的表征能力。同时设计了D-LKA Attention的2D和3D版本,其中3D版本在跨深度数据理解方面表现出色。这些组件共同构成了新颖的分层视觉Transformer架构,即D-LKA Net,在多种医学分割数据集上的表现优于现有方法。:
-
大卷积核: D-LKA Attention利用大卷积核来捕捉类似于自注意力机制的感受野。这些大卷积核可以通过深度卷积、深度膨胀卷积和1×1卷积构建,从而在保持参数和计算复杂性较低的同时,获得较大的感受野。这使得模型能够更好地理解体积上下文信息,提升分割精度。
-
可变形卷积: D-LKA Attention引入了可变形卷积,使得卷积核可以灵活地调整采样网格,从而适应不同的数据模式。这种适应性使得模型能够更准确地表征病变或器官的变形,提高对象边界的定义精度。可变形卷积通过一个额外的卷积层学习偏移场,使得卷积核可以动态调整以适应输入特征。
-
2D和3D版本: D-LKA Attention分别设计了2D和3D版本,以适应不同的分割任务需求。2D版本在处理二维图像时,通过变形卷积提高对不规则形状和大小对象的捕捉能力。3D版本则在处理三维体积数据时,通过在现有框架中引入单个变形卷积层来增强跨深度数据的理解能力。这种设计在保持计算效率的同时,能够有效地处理片间信息,提高分割精度和上下文整合能力。
大卷积核:
D-LKA Attention中的大卷积核是通过多种卷积技术构建的,以实现类似于自注意力机制的感受野,但参数和计算量更少。具体实现方式包括:
- 深度卷积(Depth-wise Convolution):深度卷积将每个输入通道独立地卷积,以降低参数数量和计算复杂度。
- 深度膨胀卷积(Depth-wise Dilated Convolution):通过在卷积核之间插入空洞,实现更大的感受野,同时保持计算效率。
- 1×1卷积:用于调整通道数并增加非线性特征。
大卷积核的构建公式如下:
其中, 是卷积核大小, 是膨胀率。参数数量和浮点运算量的计算公式如下:
在三维情况下,公式扩展如下:
通过这种大卷积核设计,D-LKA Attention能够在保持计算效率的同时,实现大范围的感受野,从而在医学图像分割任务中提供更加精确的结果。
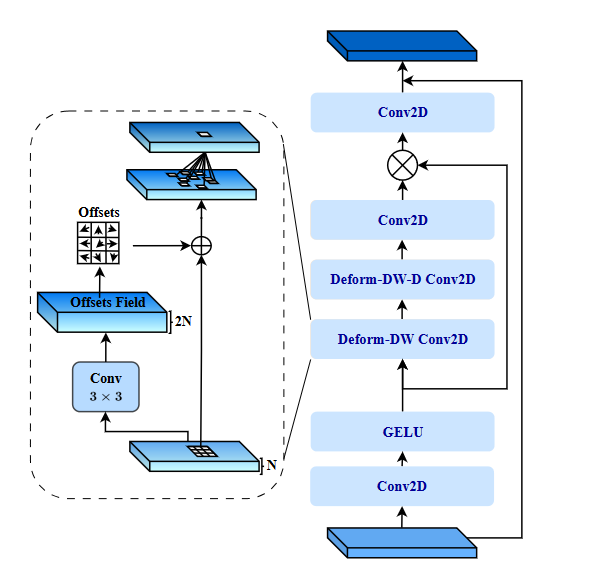
可变形卷积:
D-LKA Attention中的可变形卷积(Deformable Convolution)是一种增强型卷积技术,旨在提高卷积网络对不规则形状和尺寸对象的捕捉能力。可变形卷积通过在标准卷积操作中引入额外的学习偏移,使卷积核可以动态调整其采样位置,从而更灵活地适应输入特征的几何形变。
可变形卷积的基本思想是通过学习偏移量,使卷积核在每次卷积操作中能够自适应地调整其采样网格。具体实现如下:
-
偏移量学习:首先,使用一个卷积层来学习输入特征图上的偏移量。这个卷积层的输出是一个与输入特征图大小相同的偏移量图。
-
偏移量应用:将学习到的偏移量应用到卷积核的采样位置,从而动态调整每个卷积操作的采样点位置。
-
卷积操作:使用调整后的采样位置进行标准卷积操作。
核心代码
import torch
import torch.nn as nn
import torchvision
class DeformConv(nn.Module):
# 定义可变形卷积层
def __init__(self, in_channels, groups, kernel_size=(3, 3), padding=1, stride=1, dilation=1, bias=True):
super(DeformConv, self).__init__()
# 偏移量网络,用于生成偏移量
self.offset_net = nn.Conv2d(in_channels=in_channels,
out_channels=2 * kernel_size[0] * kernel_size[1],
kernel_size=kernel_size,
padding=padding,
stride=stride,
dilation=dilation,
bias=True)
# 可变形卷积层
self.deform_conv = torchvision.ops.DeformConv2d(in_channels=in_channels,
out_channels=in_channels,
kernel_size=kernel_size,
padding=padding,
groups=groups,
stride=stride,
dilation=dilation,
bias=False)
def forward(self, x):
# 前向传播
offsets = self.offset_net(x) # 计算偏移量
out = self.deform_conv(x, offsets) # 使用偏移量进行卷积操作
return out
class DeformConv_3x3(nn.Module):
# 定义3x3可变形卷积层
def __init__(self, in_channels, groups, kernel_size=(3, 3), padding=1, stride=1, dilation=1, bias=True):
super(DeformConv_3x3, self).__init__()
# 偏移量网络,用于生成偏移量
self.offset_net = nn.Conv2d(in_channels=in_channels,
out_channels=2 * kernel_size[0] * kernel_size[1],
kernel_size=3,
padding=1,
stride=1,
bias=True)
# 可变形卷积层
self.deform_conv = torchvision.ops.DeformConv2d(in_channels=in_channels,
out_channels=in_channels,
kernel_size=kernel_size,
padding=padding,
groups=groups,
stride=stride,
dilation=dilation,
bias=False)
def forward(self, x):
# 前向传播
offsets = self.offset_net(x) # 计算偏移量
out = self.deform_conv(x, offsets) # 使用偏移量进行卷积操作
return out
class DeformConv_experimental(nn.Module):
# 定义实验性的可变形卷积层
def __init__(self, in_channels, groups, kernel_size=(3, 3), padding=1, stride=1, dilation=1, bias=True):
super(DeformConv_experimental, self).__init__()
# 通道调整卷积层
self.conv_channel_adjust = nn.Conv2d(in_channels=in_channels,
out_channels=2 * kernel_size[0] * kernel_size[1],
kernel_size=(1, 1))
# 偏移量网络,用于生成偏移量
self.offset_net = nn.Conv2d(in_channels=2 * kernel_size[0] * kernel_size[1],
out_channels=2 * kernel_size[0] * kernel_size[1],
kernel_size=3,
padding=1,
stride=1,
groups=2 * kernel_size[0] * kernel_size[1],
bias=True)
# 可变形卷积层
self.deform_conv = torchvision.ops.DeformConv2d(in_channels=in_channels,
out_channels=in_channels,
kernel_size=kernel_size,
padding=padding,
groups=groups,
stride=stride,
dilation=dilation,
bias=False)
def forward(self, x):
# 前向传播
x_chan = self.conv_channel_adjust(x) # 调整通道
offsets = self.offset_net(x_chan) # 计算偏移量
out = self.deform_conv(x, offsets) # 使用偏移量进行卷积操作
return out
class deformable_LKA(nn.Module):
# 定义可变形的LKA注意力模块
def __init__(self, dim):
super().__init__()
self.conv0 = DeformConv(dim, kernel_size=(5, 5), padding=2, groups=dim)
self.conv_spatial = DeformConv(dim, kernel_size=(7, 7), stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
# 前向传播
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
return u * attn
class deformable_LKA_experimental(nn.Module):
# 定义实验性的可变形LKA注意力模块
def __init__(self, dim):
super().__init__()
self.conv0 = DeformConv_experimental(dim, kernel_size=(5, 5), padding=2, groups=dim)
self.conv_spatial = DeformConv_experimental(dim, kernel_size=(7, 7), stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
# 前向传播
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
return u * attn
class deformable_LKA_Attention(nn.Module):
# 定义可变形的LKA注意力模块
def __init__(self, d_model):
super().__init__()
self.proj_1 = nn.Conv2d(d_model, d_model, 1)
self.activation = nn.GELU()
self.spatial_gating_unit = deformable_LKA(d_model)
self.proj_2 = nn.Conv2d(d_model, d_model, 1)
def forward(self, x):
# 前向传播
shortcut = x.clone()
x = self.proj_1(x)
x = self.activation(x)
x = self.spatial_gating_unit(x)
x = self.proj_2(x)
x = x + shortcut
return x
class deformable_LKA_Attention_experimental(nn.Module):
# 定义实验性的可变形LKA注意力模块
def __init__(self, d_model):
super().__init__()
self.proj_1 = nn.Conv2d(d_model, d_model, 1)
self.activation = nn.GELU()
self.spatial_gating_unit = deformable_LKA_experimental(d_model)
self.proj_2 = nn.Conv2d(d_model, d_model, 1)
def forward(self, x):
# 前向传播
shortcut = x.clone()
x = self.proj_1(x)
x = self.activation(x)
x = self.spatial_gating_unit(x)
x = self.proj_2(x)
x = x + shortcut
return x
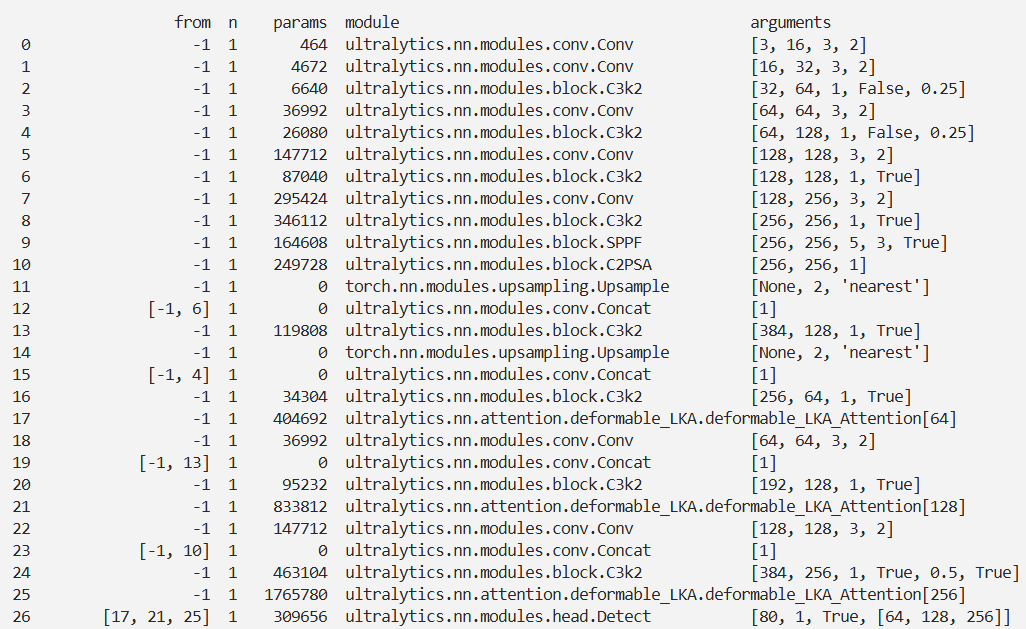
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-deformable-LKA.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='MuSGD',
# optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-deformable-LKA',
)
结果