

SnailJob:把“重试治理 + 调度 + 编排”集合到一个平台
SnailJob 什么是
SnailJob 是一个开源的分布式任务调度与分布式任务重试平台,同时提供可视化工作流编排能力,目标是把重试、回调、死信、告警、任务分片/编排这些能力从业务代码里抽出来,统一治理。
给它一个定位:
- 更像平台而不是库:有服务端控制台与客户端接入
- 把“重试治理”当成一等公民:退避策略、流量管控、死信、回调、幂等等
- 调度/编排一体化:定时任务、分片、Map/MapReduce、工作流节点依赖
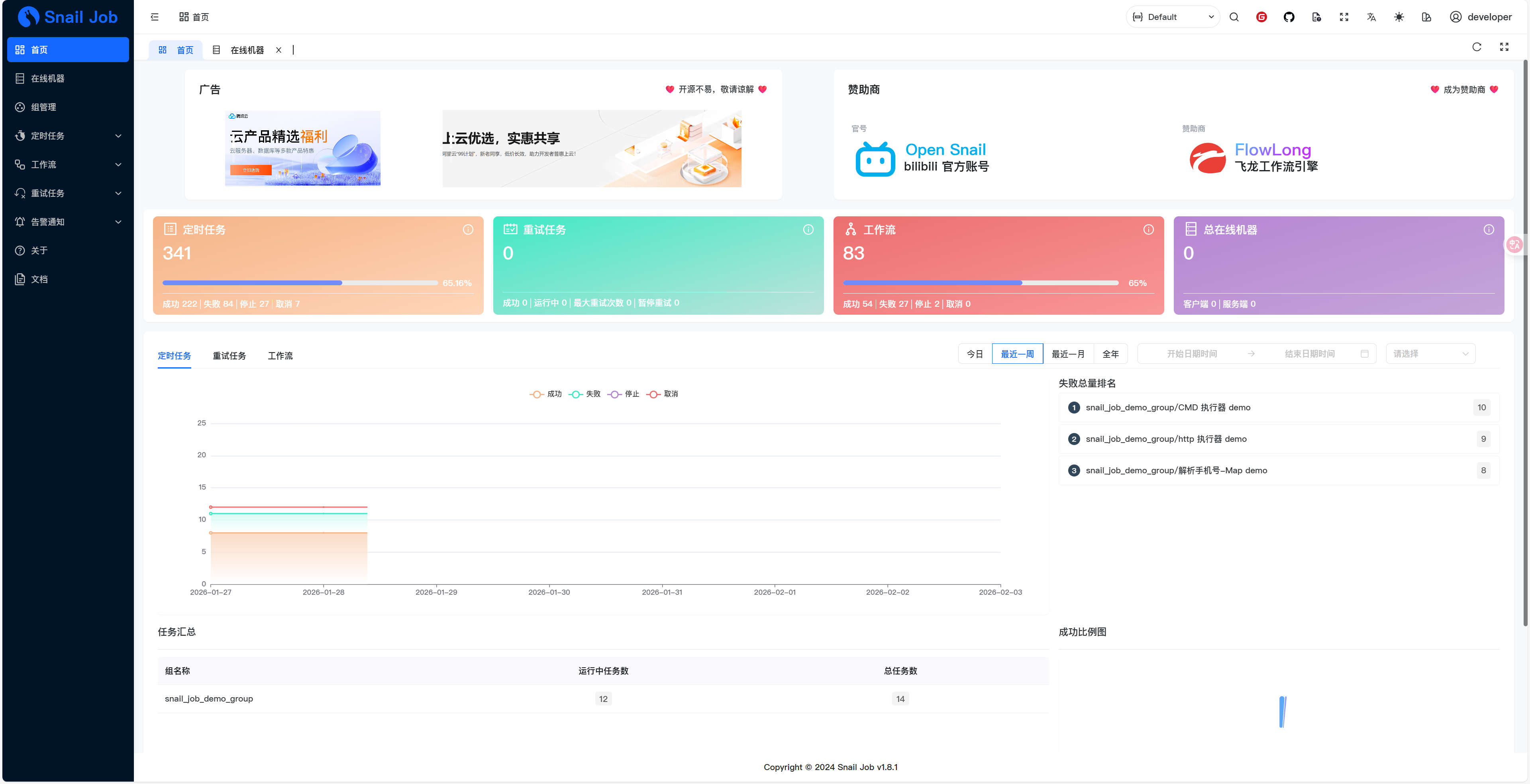
核心特性
1)分布式重试(Retry)
- 多模式:本地/远程/混合重试(以文档描述为准)
- 多策略:指数退避、固定间隔、CRON、最大重试次数等
- 治理能力:异常白/黑名单、重试风暴防护(跨服务流量管控/单机重试管控/后台数据管控)
- 收敛出口:死信任务、重试完成回调、多渠道通知(飞书/钉钉/企微/邮件/Webhook)
- 一致性辅助:支持幂等 ID(用于降低重复执行风险)
2)分布式调度(Job)
- 触发方式:CRON、秒级、固定频率等
- 执行模式:集群、广播、静态分片、Map、MapReduce
- 运维体验:任务状态、执行日志、失败告警、暂停/恢复/终止/手动触发
- 接口能力:提供 OpenAPI,用于远程触发与集成
3)工作流编排(Workflow)
- 可视化编排:所见即所得的流程设计(仿工作流引擎交互)
- 节点与控制:任务节点/决策节点、上下文传递、超时管理、阻塞策略
使用场景
- 跨服务补偿与一致性:支付回调、库存扣减、异步对账等,失败后需要“可控重试 + 可追踪 + 可回滚”
- 把散落的调度收敛成平台:把
@Scheduled/脚本补数/临时任务统一纳管,权限、审计、告警统一出口 - 批处理/并行计算:需要广播/分片/MapReduce 加速的大批量任务
- 任务链路编排:例如“拉取数据 -> 清洗 -> 入库 -> 生成报表 -> 通知”,希望链路可视化、可追踪
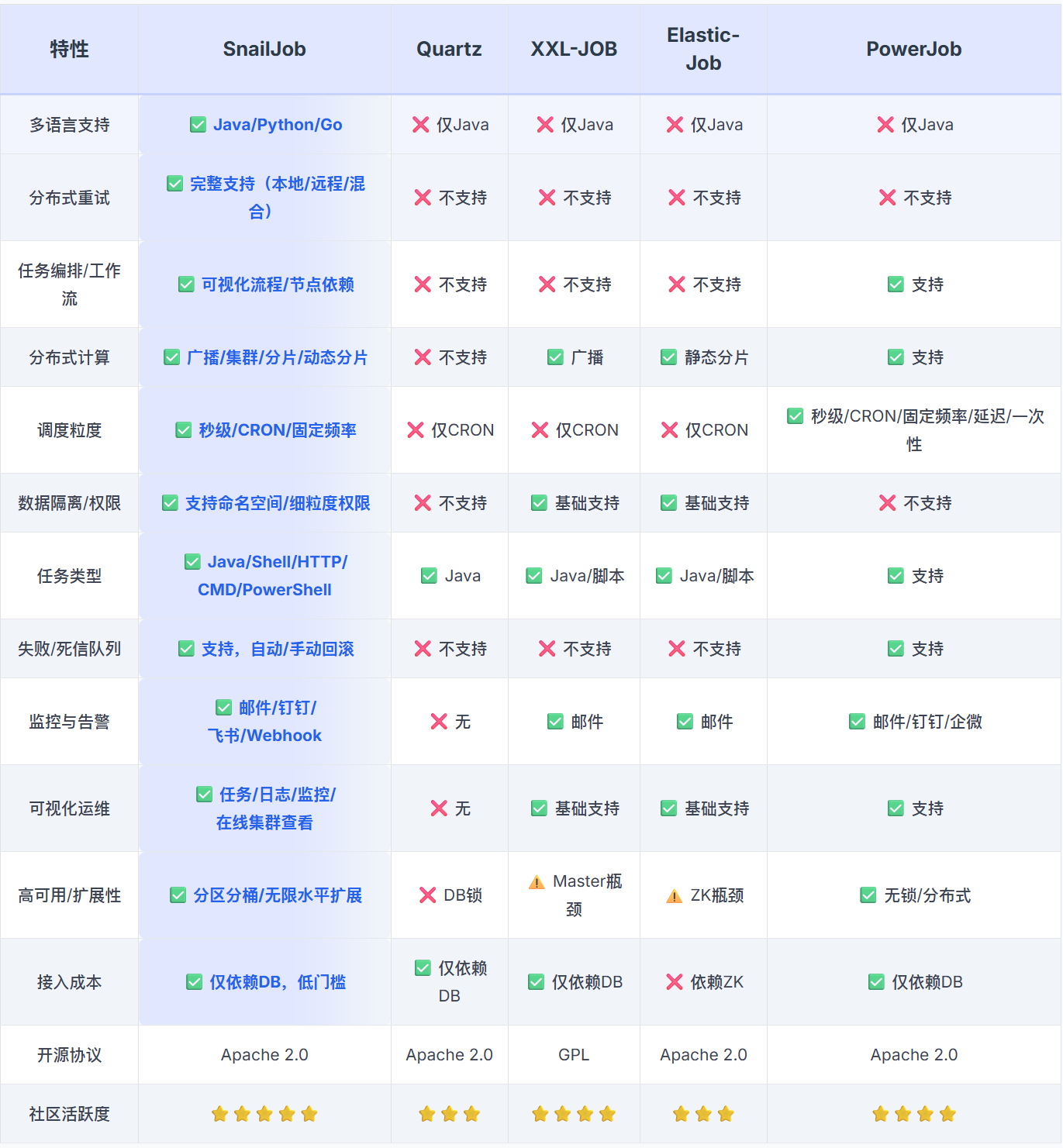
同类型对比
快速上手
1)服务端部署
方式 A:源码部署
- 初始化数据库(以 MySQL 为例):脚本路径
doc/sql/snail_job_mysql.sql - 构建并启动:
git clone https://github.com/aizuda/snail-job.git
cd snail-job
mvn clean package
java -jar snail-job-server/snail-job-server-starter/target/snail-job-server-exec.jar
启动后默认控制台(以文档为准):
- 地址:
http://localhost:8080/snail-job - 默认账号/密码:
admin/admin
方式 B:Docker 部署(生产更常用)
- 文档提供了
docker run opensnail/snail-job:{Latest Version}的模板,核心是把数据源环境变量配置好并映射端口。
2)控制台准备:命名空间 + 执行器组
- 创建命名空间(可用默认,也可新建)
- 创建执行器组,并记录
group与token(客户端需要)
3)Java 客户端接入(Spring Boot)
<dependencies>
<!-- 核心依赖 -->
<dependency>
<groupId>com.aizuda</groupId>
<artifactId>snail-job-client-starter</artifactId>
<version>{Latest Version}</version>
</dependency>
<!-- 重试模块(若不需要可以不引入) -->
<dependency>
<groupId>com.aizuda</groupId>
<artifactId>snail-job-client-retry-core</artifactId>
<version>{Latest Version}</version>
</dependency>
<!-- 定时任务(若不需要可以不引入) -->
<dependency>
<groupId>com.aizuda</groupId>
<artifactId>snail-job-client-job-core</artifactId>
<version>{Latest Version}</version>
</dependency>
</dependencies>
启用:启动类添加 @EnableSnailJob。
@SpringBootApplication
// 这里还有另一种写法 @EnableSnailJob("test_sj_group")
// 注解优先级 > 配置文件优先级 建议直接配置到配置文件中
@EnableSnailJob
public class SnailJobSpringbootApplication {
public static void main(String[] args) {
SpringApplication.run(SnailJobSpringbootApplication.class, args);
}
}
配置:
snail-job:
# 任务调度服务器信息
server:
# 服务器IP地址(或域名);集群时建议通过 nginx 做负载均衡
host: 127.0.0.1
# 服务器通讯端口(不是后台管理页面服务端口)
port: 17888
# 命名空间 【上面配置的空间的唯一标识】
namespace: a1NSize1D5jP83Wj0B6Hre094f7kFeHB
# 接入组名【上面配置的组名称】注意: 若通过注解配置了这里的配置不生效
group: test_sj_group
# 接入组 token 【上面配置的token信息】
token: SJ_t3GFbbDCpmznt9M9Pp62GYJecE6S9q9H
# 客户端绑定IP,必须服务器可以访问到;默认自动推断,在服务器无法调度客户端时需要手动配置
host: 127.0.0.1
# 客户端通讯端口,默认 17889
port: 17899
# 实时日志配置
logging:
config: classpath:logback-boot.xml
启动客户端
总结
SnailJob 的价值不在“又多一个定时任务框架”,而在把最难治理的那部分平台化:
- 重试从“写在代码里”变成“可管控、可回放、可追踪”
- 调度从“各自为政”变成“可运维、可审计、可告警”
- 编排从“脚本串起来”变成“可视化、可观察”的工作流
官网地址与开源地址
- 官网/文档:snailjob.opensnail.com/
- GitHub:github.com/aizuda/snai…
