

AWS资深技术高管Hugues Clouâtre对RAG的核心流程进行了手把手剖析,并对何时使用RAG或微调给出了量化建议,虽有夹带宣传Bedrock。
旧系统文档已有 20 年历史,共 7432 页,且全部锁定在 PDF 文件中。手动搜索每次需要 15-30 分钟。我们将其优化至 170 秒内即可完成查询。查询响应时间:3-5 秒。投资回报周期:仅需一天。
这并非原型。这是基于 Amazon Bedrock 的检索增强生成 (RAG) 系统,它能够检索相关文档,并使用 LLM(逻辑层模型)生成答案,无需重新训练模型。该系统已在四种 LLM 系列上进行了验证,共进行了 480 次测量。该实现可索引 20,679 个数据块,并可在 5 秒内提供响应,且响应速度与模型无关。无论使用哪种 LLM,开销均为 27.2 毫秒 ± 4.6 毫秒。
是的,7432页的内容可以放入任何搜索索引。但排名靠前的结果并不是答案。
以下是生产架构、多模型验证数据,以及为什么可以切换提供商而无需重新调整。
为什么是 RAG 而不是微调?
微调会根据你的文档训练模型。它会将知识嵌入权重中(这使得溯源验证变得困难),每次更新都需要重新训练,并且在 A100 GPU 上每次运行的成本为 1.32-6.24 美元(Thunder Compute,2025)。RAG 使用本地嵌入,设置成本为 0 美元,在 Bedrock 上每次查询的成本为 0.0011 美元,更新速度仅需 2 秒,并且能够确保来源可验证。
对于遗留系统,选择 RAG 是出于运营方面的考虑,而非经济因素。文档分散在 wiki 和 PDF 文件中。随着逆向工程发现新的系统行为,文档也在不断更新——每次微调都需要重新训练。查询量很低(每周几十次)。决定性因素包括:即时更新(2 秒即可完成,无需重新训练)、符合规范的源引用以及更简单的维护。我们选择 RAG 是因为它具有敏捷性:设置仅需 170 秒,更新只需 2 秒,每年成本低于 20 美元。
RAG 如何将 PDF 文件转换为答案?
摄取管道
该管道分为六个阶段:
- 提取- 使用 PyMuPDF 从 PDF 中提取文本(44 页/秒)
- 转换- 转换为 Markdown 并检测标题
- 分段- 按标题分割(1000 个字符限制,200 个字符重叠)
- 嵌入- 使用 all-MiniLM-L6-v2 生成向量(本地,免费)
- 索引- 存储在 ChromaDB 向量数据库中
- 检索- 混合搜索(BM25 + 向量)结合 FlashRank 重排序
import fitz # pymupdf
doc = fitz.open(pdf_path)
for page_num in range(len(doc)):
page = doc[page_num]
text = page.get_text()
for line in text.split("\n"):
# Detect chapter headings (e.g., "Chapter 1. Title")
if line.startswith("Chapter ") and ". " in line:
cleaned_lines.append(f"\n## {line}\n")
# Detect section headings
elif len(line) < 80 and line[0].isupper():
cleaned_lines.append(f"\n### {line}\n")
doc.close()
代码片段 1:PyMuPDF 提取文本并将其转换为 Markdown,具有标题检测功能,处理速度为每秒 44 页。
该流程在分块之前会将 PDF 文件转换为 Markdown 格式。这样可以保留文档结构(章节、小节、标题),并实现符合 Markdown 语义边界的分块。分块会在标题边界(## 、### )处进行,而不是在段落中间进行,从而将相关内容保持在一起。Markdown 文件会被缓存,因此后续运行无需提取 PDF 文件,只需 2 秒即可完成,而不是之前的 170 秒。
混合检索:BM25 + 向量搜索
为什么不直接使用 Elasticsearch 或 Ctrl+F 呢?比如,2005 年的文档包含字符串“数据文件缓存耗尽”,用纯关键词“内存错误”搜索时会失败,因为关键词无法匹配语义。纯向量搜索会遗漏像“端口 5432”这样的精确词条。混合检索解决了排名问题。LLM 解决了最后的综合分析问题:将多个文档中的片段组合成一个可操作的答案。RRF 的性能始终优于单一方法的搜索(Mandikal & Mooney,2024)。
# Reciprocal Rank Fusion (RRF) combines BM25 + vector scores
doc_scores: dict[str, tuple[Document, float]] = {}
for rank, idx in enumerate(bm25_top_indices[:retrieve_k]):
doc = chunks[idx]
doc_id = doc.metadata.get("source", "") + str(hash(doc.page_content[:100]))
rrf_score = 1 / (rank + 60) # RRF with k=60
if doc_id in doc_scores:
doc_scores[doc_id] = (doc, doc_scores[doc_id][1] + rrf_score)
else:
doc_scores[doc_id] = (doc, rrf_score)
代码片段 2:RRF 公式结合了关键词和语义搜索得分,其中 k=60 为常数。
混合检索返回 16 个候选数据块。交叉编码器模型(FlashRank)对每个查询-文档对进行评分,并返回前 8 个。这解决了精确率问题:混合搜索提供高召回率,重排序提供高精确率。
示例:错误查找耗时 3.4 秒
用户查询: “错误代码 1006030 是什么?我该如何解决?”
生成的答案:
错误 1006030:“无法将数据文件页加载到缓存中。数据文件缓存太小。”
原因: Essbase 无法将数据文件页存储在数据文件缓存中。
**解决方法:**增加数据文件缓存大小。修复后,检查数据库是否损坏(错误消息参考,第 126 页)。
**耗时:**总计 3.4 秒(检索:80 毫秒,重排序:31 毫秒,生成:3.3 秒)
摘自: 《错误消息参考手册》v11.1.1(重新排名后在8个版本中排名第3)
系统从错误信息参考手册中检索到错误代码 1006030(重新排名后在 8 个错误代码中排名第 3),并生成了可操作的解决方案。手动查找则需要打开 1200 页的错误信息参考手册 PDF 文件,然后使用 Ctrl+F 快捷键。
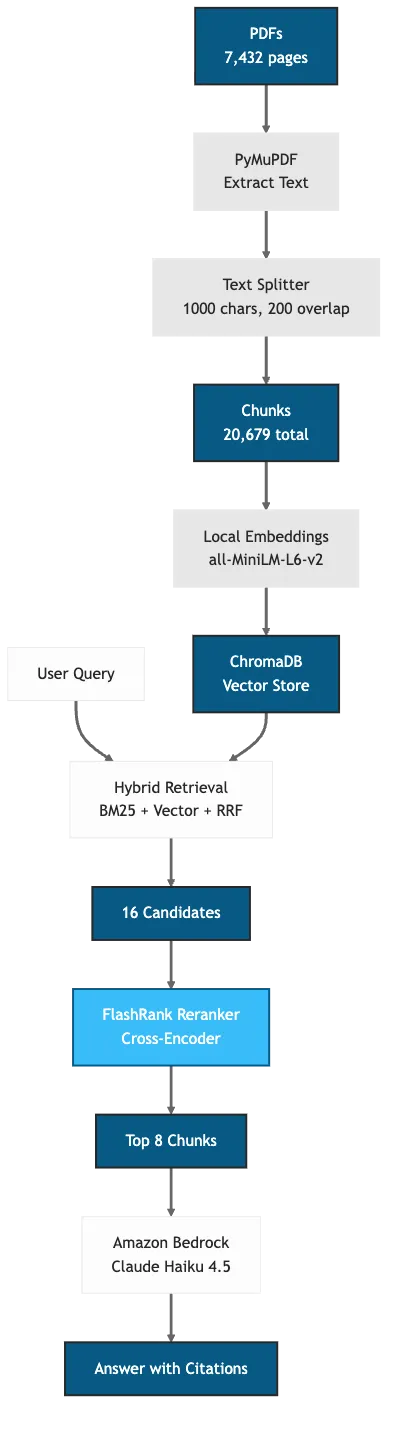
图 1:采用混合检索和重排序的 RAG 流水线(FlashRank 会增加 31 毫秒的开销,以获得6-8% 的准确率提升)(George,2025)
局部嵌入和模型无关设计
为什么选择本地嵌入?成本低、操作简便、性能优异。云端嵌入 API 每百万个token收费 0.10-0.50 美元。本地模型免费,无需 API 密钥,在 CPU 上不到 10 秒即可嵌入 1000 个数据块。全 MiniLM-L6-v2 模型仅 80 MB,无需 GPU 加速即可运行。
该架构的设计与模型无关。我们使用 Amazon Bedrock,但同样的流程也适用于 Azure OpenAI、Google Vertex AI 或本地模型。
重排序在不同模型中都适用吗?
我们测试了两种网络服务提供商(Amazon Bedrock 和 OpenRouter)上的四种 LLM 系列网络,以验证其可移植性。平均延迟为 27.2 毫秒 ± 4.6 毫秒(480 次测量),无统计学显著差异(ANOVA p=0.34)。跨服务提供商的差异仅为 4.1 毫秒。
| Model | Family | Latency | Provider |
|---|---|---|---|
| Claude Haiku 4.5 | Anthropic | +31.3ms | Amazon Bedrock |
| Mistral Devstral-2512 | Mistral | +32.5ms | OpenRouter |
| Llama 3.3 Instruct | Meta | +24.1ms | OpenRouter |
| Qwen 2.5 Coder | Alibaba | +25.1ms | OpenRouter |
表 1:延迟在不同模型和提供商之间具有一致性(480 次测量,ANOVA p=0.34)
延迟主要由 FlashRank 的交叉编码器决定,而非 LLM。这意味着您只需部署一次,即可在切换服务提供商时无需重新调优。
from flashrank import Ranker, RerankRequest
def _rerank(self, query: str, docs: list[Document]) -> list[Document]:
passages = [
{"id": i, "text": doc.page_content, "meta": doc.metadata}
for i, doc in enumerate(docs)
]
rerank_request = RerankRequest(query=query, passages=passages)
results = self.ranker.rerank(rerank_request)
return [docs[result["id"]] for result in results[:RERANK_TOP_N]]
代码片段 3:FlashRank 使用交叉编码器评分在 31 毫秒内对 16 个候选结果进行重新排序。
重排序是基础设施层面的工作,而不是模型特定的配置。将其集成到检索流程中即可,无需再操心。
真实的性能数据是多少?
在验证了与模型无关的重排序方法之后,以下是生产指标。
我们在 170 秒内索引了 7432 个页面。首次设置包括 PDF 提取(120 秒)、分块(20 秒)、嵌入(25 秒)和索引(5 秒)。缓存运行跳过提取步骤,耗时 2.2 秒。查询响应时间平均为 3-5 秒:检索(80 毫秒)、LLM 生成(4 秒)、开销(200 毫秒)。
在 Amazon Bedrock 上,每次查询的成本为 0.01-0.05 美元。输入token(从检索到的数据块中提取的上下文信息)的成本为每百万个token 0.25 美元。输出token(LLM 答案)的成本为每百万个token 1.25 美元。一个典型的查询使用 2,000 个输入token和 500 个输出token,总成本为 0.0011 美元。
| 指标 | 系统 A(文档) | 系统 B(笔记) |
|---|---|---|
| 文件 | 14 个 PDF 文件(共 7,432 页) | 94 个 Markdown 文件 |
| 块 | 20,679 | 自动分块 |
| 首次运行 | 170s | 40s |
| 缓存运行 | 2.2s | 2s |
| 查询时间 | 3-5s | 3-5s |
| 费用/查询 | $0.01-0.05 | $0.01-0.05 |
表 2:两个生产 RAG 系统的性能指标(系统 A 处理技术文档,系统 B 处理会议记录)
重新排序会使检索时间增加 31 毫秒。这相当于检索延迟增加了 65%,但仅占总查询时间的 0.3%。在 9 秒的端到端响应中,用户几乎感觉不到这 31 毫秒。6-8% 的准确率提升与混合检索相对于单一方法搜索的优势叠加,使得这部分开销与最终的质量提升相比可以忽略不计。有关详细方法和原始数据,请参阅补充材料。
不进行现代化改造,投资回报率是多少?
手动搜索 7432 页文档需要 15-30 分钟(中位数:25 分钟)。你需要打开 PDF 文件,使用 Ctrl+F 查找,阅读上下文,并交叉引用相关章节。而 RAG 算法可以将这一过程缩短至 3-5 秒。
假设在为期 6 个月的迁移项目中,每天处理 10 个查询。人工成本:每小时 100 美元(中端技术顾问)。节省时间:每个查询 25 分钟。成功率:85%(考虑到 10-15% 的查询需要人工审核)。
每日节省:10 次查询 × 25 分钟 × (100 美元/小时 ÷ 60) × 85% 成功率 = 354 美元/天
设置成本:170 秒计算时间,外加 0 美元的本地嵌入费用。查询成本:在 Amazon Bedrock 上为 0.01-0.05 美元。一天即可实现盈亏平衡。
RAG何时失效?
RAG算法在处理多步骤推理、模糊问题以及文档中未包含的信息时会失效。我们在生产环境中已经观察到三种失效模式。
幻觉
LLM会编造一些不在检索到的文本块中的答案。缓解措施:显示来源引用、添加置信度评分、将答案限制在检索到的上下文范围内。我们为每个答案显示前3个来源文档及其页码。
上下文溢出
复杂查询需要比LLM窗口所能容纳的更多上下文信息。缓解措施:将查询拆分为子问题,使用查询扩展来处理领域术语,对关联概念实现多跳检索。
过时数据
文档已更改,但嵌入内容未更新。缓解措施:PDF 文件采用基于哈希值的缓存失效机制,Markdown 文件采用基于时间戳的缓存失效机制,并在文件更改时自动重新索引。
语料库限制
并非所有故障都是系统故障。评估结果揭示了三个与语料库相关的问题:
- 语料库缺口:知识不存在(例如,未记录具体的错误代码)。系统正确地回应“我不知道”。
- 信息分散:知识虽然存在,但分散在各个部分,导致综合分析不完整。
- 查询公式:当没有对确切代码进行索引时,基于症状的查询(“内存不足错误”)比基于代码的查询(“错误 1012001”)性能更好。
这些是客观存在的局限性,并非RAG故障。缓解措施是扩充语料库,而非系统调优。
总体故障率是多少?
10-15% 的查询需要人工审核,因为它们涉及复杂的多步骤推理或含义模糊的问题。另一种方法是手动搜索 7,432 页。RAG 可以自动处理简单的案例,而专家则专注于处理特殊情况。
| 查询类别 | 成功率 | 常见故障模式 | 减轻 |
|---|---|---|---|
| 错误查找 | 50-60% | 语料库中没有确切的代码 | 基于症状的查询;语料库扩展 |
| 概念 | 90-100% | 罕见;通常是语料库缺失 | 使用领域术语扩展查询 |
| 步骤 | 100% | 罕见;版本差异 | 使用命令名称进行查询扩展 |
| 多跳 | 50-70% | 知识分散或缺失 | 语料库扩展;诚实的“未找到” |
表 3:按查询类型划分的 RAG 成功率,每类 n=10,验证子集上的误报率为 0%(方法论)
关键在于透明度。用户可以看到检索到的文档,可以核实信息,并知道何时需要升级处理。信任源于引用,而非对LLM输出结果的盲目信任。
如何从原型阶段过渡到生产阶段?
我们最初使用的是 OpenRouter 的免费套餐。型号:Devstral-2512。费用:0 美元。限制:限速,不保证合规性。我们通过 20-30 个测试查询验证了质量。
迁移到 Amazon Bedrock 耗时不到 30 分钟。代码变更:替换依赖项(将 langchain-openai 替换为 langchain-aws),将 ChatOpenAI 替换为 ChatBedrock,更新身份验证方式,使用 AWS 凭证而非 API 密钥。优势:无速率限制、符合 SOC 2 标准、可进行治理控制、Claude Haiku 4.5 提供的答案质量更高。
迁移路径:从小规模开始,选择一个文档集和一个用例。通过测试查询验证质量,将 RAG 答案与源文档中的真实答案进行比较。通过跟踪查询量和用户反馈来衡量采用情况。通过添加更多文档、调整分块策略和改进检索来迭代。

图 2:从免费层验证到企业生产环境的迁移路径(在投资基础设施之前迭代优化质量)
通过为不同领域构建多个 RAG 系统来实现规模化。我们运行两个系统:一个用于技术文档,一个用于会议记录和经验知识。架构相同,语料库不同。总维护时间:每月不到 1 小时。
接下来该怎么做?
识别高价值文档集。例如,入职资料、合规文档或迁移指南。使用每日查询次数、每次查询节省的时间以及每小时人工成本来估算投资回报率。如果计算结果合理,可以从免费套餐开始。
使用 OpenRouter 或本地模型进行验证。运行 20-30 个测试查询。将 RAG 答案与源文档中的真实答案进行比较。衡量准确率,检查是否存在异常结果,并核实来源引用。如果质量可以接受,则投资企业级基础设施。
Amazon Bedrock 和 Azure OpenAI 提供合规性、治理和更优的模型。每次查询的成本为 0.01-0.05 美元。如果每天查询 100 次,则每天的成本为 1-5 美元,每月的成本为 30-150 美元。相比之下,这可以节省 9,000 美元的人工成本。
决策框架:当文档频繁变更、来源引用对合规性至关重要,或者需要灵活的运营时,RAG 策略更优。当知识体系稳定、需要检索之外的特定功能,或者查询量极大(每天数千次)且对延迟要求严格时,微调策略更优。
对于传统系统,RAG 无需现代化改造即可实现投资回报。无需重写文档、迁移数据库或重新培训员工。只需将 RAG 叠加到现有 PDF 文档上,即可在 3 秒内获得 20 年前问题的答案。
有关更广泛的集成模式和 ROI 框架,请参阅“遗留系统中的 AI 代理:无需现代化即可获得 ROI” 。
References
- Braintrust, “RAG Evaluation Metrics: How to Evaluate Your RAG Pipeline” (2025) — www.braintrust.dev/articles/ra…
- Clouatre, H., “RAG Reranking Benchmarks: Supplementary Materials” (2026) — github.com/clouatre-la…
- de Luis Balaguer et al., “RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture” (2024) — arxiv.org/abs/2401.08…
- Dettmers et al., “QLoRA: Efficient Finetuning of Quantized LLMs” (2023) — arxiv.org/abs/2305.14…
- Gan et al., “Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey” (2025) — arxiv.org/abs/2504.14…
- George, Sherine, “Enhancing Retrieval-Augmented Generation with Two-Stage Retrieval: FlashRank Reranking and Query Expansion” (2025) — arxiv.org/abs/2601.03…
- LangChain Documentation, “Contextual Compression and Reranking” (2025) — python.langchain.com/docs/how_to…
- Mandikal & Mooney, “Sparse Meets Dense: A Hybrid Approach to Enhance Scientific Document Retrieval” (2024) — arxiv.org/abs/2401.04…
- Oche et al., “A Systematic Review of Key Retrieval-Augmented Generation (RAG) Systems: Progress, Gaps, and Future Directions” (2025) — arxiv.org/abs/2507.18…
- Thunder Compute, “AI GPU Rental Market Trends December 2025: Complete Industry Analysis” (2025) — www.thundercompute.com/blog/ai-gpu…
