前置知识
由于人工智能方向涉及较多数学知识,限于篇幅原因,作者无法将其列举完全,这里挑选几个较为重要的知识点作简要介绍。有些基础数学知识已经单独在其他文档中描述,这里不再赘述。如有疑问,欢迎评论或私信留言。
极大似然法
总体X有分布率P(X=x;θ)或密度函数f(x;θ),已知θ∈Θ,Θ是参数空间。(xi)i=1n为取自总体X的一个样本(Xi)i=1n的观测值,将样本的联合分布率或联合密度函数看成是θ的函数,用L(θ)表示,又称为θ的似然函数,即
L(θ)L(θ)=i=1∏nP(Xi=xi;θ)或=i=1∏nf(xi;θ)
称满足关系式
L(θ^)=θ∈ΘmaxL(θ)
的解
θ^=argθ∈ΘmaxL(θ)
为θ的极大似然估计量。
当L(θ)是可微函数时,求导是求极大似然估计最常用的方法。此时又因L(θ)与lnL(θ)在同一个θ处取得极值,且对对数似然函数lnL(θ)求导更简单,故我们常用如下对数似然方程
dθdlnL(θ)=0
当θ为几个未知参数组成的向量θ=(θi)i=1k时,用如下对数似然方程组
⎩⎨⎧∂θ1∂lnL(θ)=0∂θ2∂lnL(θ)=0⋮∂θk∂lnL(θ)=0
求得θ的极大似然估计值。
当似然函数不可微时,也可以直接寻求使得L(θ)达到最大的解来求的极大似然估计值。
泰勒公式
如果给定了在点x0具有所有前n阶导数的函数f(x),则称f(x)在x0处n阶可导。则有
f(x)=f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2+3!1f′′′(x0)(x−x0)3+⋯+n!1f(n)(x0)(x−x0)n+Rn(x)=i=0∑ni!f(i)(x0)(x−x0)i+Rn(x)
其中Rn(x)称为泰勒公式的余项,当n充分大时,Rn(x)趋于0。
对泰勒公式求n阶导,其在x0处的值为f(n)(x0)。
Logistic分布
设X是连续随机变量,X服从Logistic分布是指X具有下列分布函数和密度函数:
F(x)f(x)=P(X≤x)=1+e−γx−μ1=F′(x)=γ(1+e−γx−μ)2e−γx−μ
式中,μ为位置参数,γ>0为形状参数。Logistic函数是一条以点(μ,21)为中心对称的S型曲线
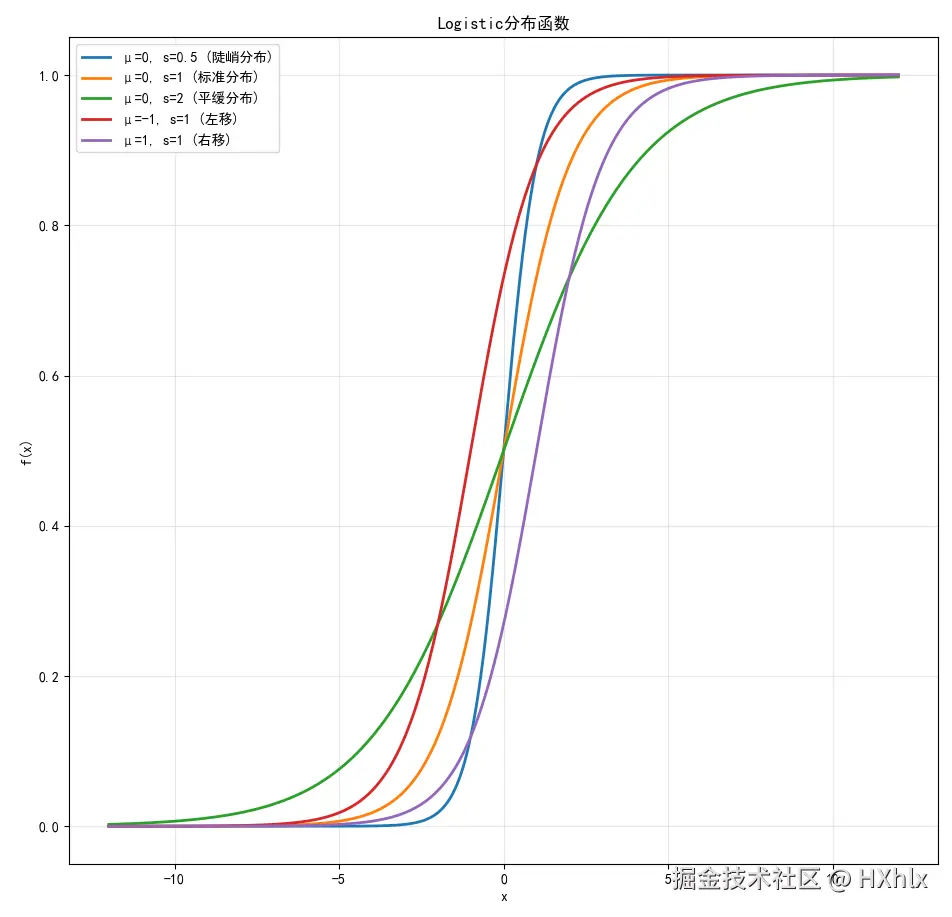
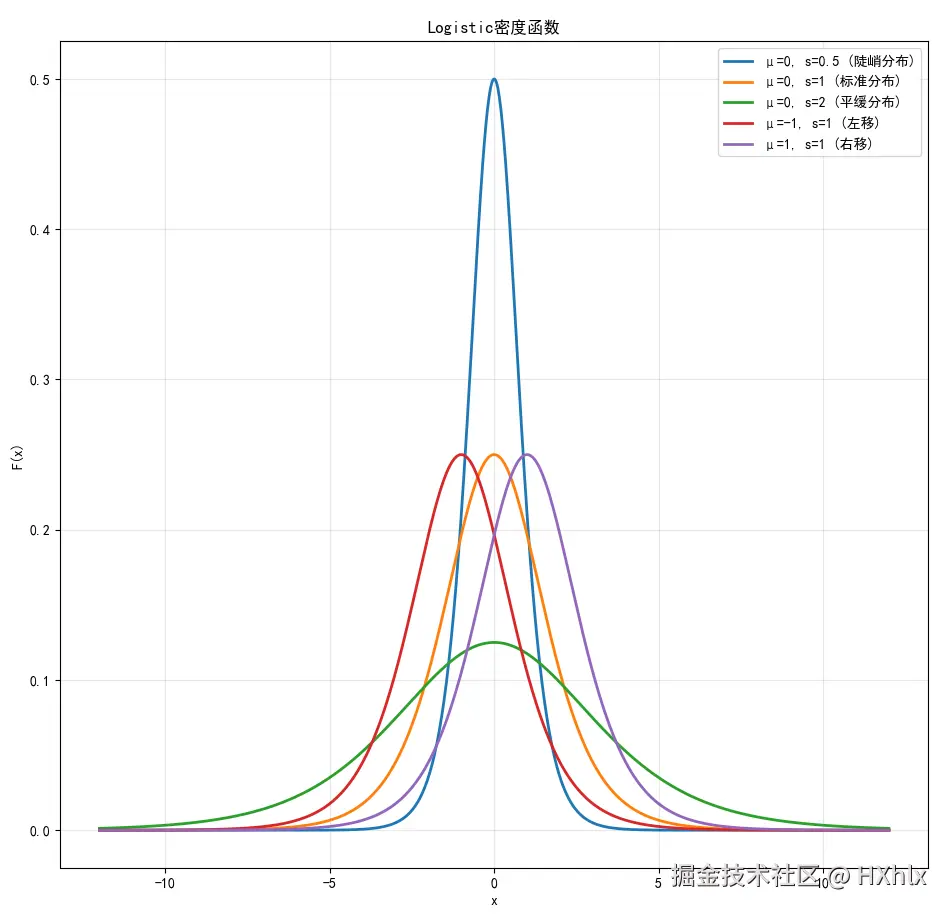
Sigmoid函数
Sigmoid函数是激励函数的一种,在神经网络中具有重要作用。其中的重要代表就是Logistic函数,为当位置参数μ=0,形状参数γ=1时的Logistic分布函数,表达式为
y=1+e−z1
每一次进入神经网络节点的过程,都是先进行线性变换,再使用激励函数运算的过程。因此可有下式
{z=wTx+by=1+e−z1
联合得到
y=1+e−(wTx+b)1
上式可变化为
ln1−yy=wTx+b
Logistic回归
若将y视为样本x作为正例的可能性P(y=1∣x),则1−y是其反例可能性P(y=0∣x),则有
P(y=1∣x)P(y=0∣x)lnP(y=0∣x)P(y=1∣x)=1+e−(wTx+b)1=1+ewTx+bewTx+b=1+ewTx+b1=wTx+b
参数估计
给定数据集(xi,yi)i=1m,Logistic回归模型最大化对数似然
LL(w,b)=lni=1∏mP(yi∣xi;w,b)=i=1∑mlnP(yi∣xi;w,b)
令w^=[wb],x^=[x1],则wTx+b可简写为w^Tx^。根据事件的独立性,
P(yi∣xi;w,b)=P(y=1∣xi^;w^)yiP(y=0∣xi^;w^)1−yi=(1+e−w^Tx^i1)yi(1+ew^Tx^i1)1−yi
经写者多方排查,上式在不同的书中结果是不一致的,主要代表为周志华的《机器学习》和李航的《统计学习方法》。周志华的《机器学习》可能是采用了全概率公式,推导过程有误,这里以李航《统计学习方法》的为准。
代入对数似然得
LL(w^)=i=1∑mln(1+e−w^Tx^i1)yi(1+ew^Tx^i1)1−yi=i=1∑m[w^Tx^iyi−ln(1+ew^Tx^i)]
对LL(w^)求在极大值时的w^等价于求−LL(w^)在极小值时的w^,即
w^=argw^maxLL(w^)=argw^maxi=1∑m[w^Tx^iyi−ln(1+ew^Tx^i)]=argw^min(−LL(w^))=argw^mini=1∑m[ln(1+ew^Tx^i)−w^Tx^iyi]
梯度下降法
梯度下降法又称最速下降法,是求解无约束最优化问题的一种最常用的方法,具有实现简单的优点,梯度下降法是迭代算法,每一步需要求解目标函数的梯度向量。
针对Sigmoid函数,要求解的无约束最优化问题是
min(f(w^))=min(−LL(w^))
w^∗表示目标函数f(w^)的极小点。
梯度下降法是一种迭代算法。选取适当的初值w^0,不断迭代,更新w^的值,进行目标函数的极小化,直到收敛。由于负梯度方向是使函数值下降最快的方向,在迭代的每一步,以负梯度方向更新w^的值,从而达到减少函数值的目的。
由于f(w^)具有一阶连续偏导数,若第k次迭代值为w^k,可求得f(w^)在w^k的梯度为:
G(w^k)=∇f(w^k))=∂w^k∂f(w^k)=i=1∑m(1+e−w^kTx^i1−yi)x^i
给定一个精度ϵ,一般取较小值,当∣∣G(w^k)∣∣<ϵ时,停止迭代。此时找到了符合精度要求的极小值解w^∗=w^k;否则,令新的点w^k+1=w^k−ϵG(w^k),继续迭代。
牛顿法
牛顿法基于一个二阶泰勒展开来近似w^0附近的f(w^):
f(w^)≈f(w^0)+(w^−w^0)T∇f(w^0)+21(w^−w^0)T∇2f(w^0)(w^−w^0)≈f(w^0)+(w^−w^0)Ti=1∑m(1+e−w^kTx^i1−yi)x^i+21(w^−w^0)T[i=1∑m(1+ew^kTx^i)2ew^kTx^ix^ix^iT](w^−w^0)
其中H(f(w^0))=∇2f(x0)是Hessian矩阵,详见神经网络基础——矩阵求导运算
给定精度ϵ,假设w^k+1满足精度条件
0≈G(w^k+1)=∇f(w^k+1)<ϵ
则有
G(w^k)≈((w^k+1−w^k)T)−1(f(w^k+1)−f(w^k))≈∇f(w^k)+21∇2f(w^k)(w^k+1−w^k)≈0
由上式可得迭代公式
w^k+1=w^k−2H(f(w^0))−1G(w^k)
拟牛顿法
牛顿法由于每次迭代都需要计算一次黑塞矩阵的逆矩阵,这一过程比较复杂。拟牛顿法的思想是构造一个近似矩阵N来替代黑塞矩阵的逆H−1。常用的算法有DFP算法(Davidon-Fletcher-Powell, DFP algorithm)、BFGS(Broyden-Fletcher-Goldfarb-Shanno, BFGS algorithm)、Broyden类算法(Broyden's algorithm)等。由于篇幅原因,这里不再赘述。后续另开篇幅单独介绍。


