

DeepSeek Model1:代码库里的核爆,大模型性能极限的二次探索
在AI圈,真正的地震往往不是由新闻发布会引发的,而是源于GitHub上某次不经意的代码提交。
就在最近,DeepSeek在FlashMLA代码库中悄然更新了一个名为“Model1”的神秘模型版本。作为一名在AI算力架构领域摸爬滚打15年的老兵,我习惯于从冗长的CUDA算子和底层指令集中寻找真相。这次更新绝非简单的版本迭代,它更像是一份通往下一代旗舰模型DeepSeek-V4的“技术白皮书”。
Model1的出现,标志着DeepSeek正在从“算法创新”全面转向“软硬一体化的工程霸权”。它不仅是对现有架构的修补,更是对大模型性能极限的一次暴力拆解与重构。

架构的“复古”与“进化”:512维的工程哲学
在Model1的技术细节中,最令架构师们侧目的是其核心架构回归到了512维标准。
熟悉DeepSeek-V3的朋友都知道,V3采用的是576维架构。从576降到512,表面上看是维度的缩减,实则是极致的硬件对齐考量。在NVIDIA的GPU架构中,无论是Warp(线程束)的调度还是显存带宽的对齐,2的幂次方(如512)往往能获得最高的执行效率。
回归512维,意味着Model1在底层算子执行时,能够实现近乎完美的内存对齐,减少Padding(填充)带来的算力浪费。 这种“复古”实际上是对硬件吞吐量的极致压榨。在千亿级参数的推理场景下,哪怕是1%的对齐优化,转化到集群层面也是数以百万计的成本节省。
更深层的逻辑在于Latent(潜空间)压缩比例的优化。DeepSeek在DeepSeek-V2中首次引入了MLA(Multi-head Latent Attention),通过低秩压缩极大地降低了KV Cache的压力。而Model1在512维架构下,进一步精细化了压缩算法。这种维度的调整,是为了在保持模型表达能力的同时,让每一比特的显存都能发挥出最大的信息承载量。
核心技术拆解:Token级稀疏MLA与VVPA的降维打击
如果说维度调整是“内功”,那么Model1引入的Token级稀疏MLA和**VVPA(数值向量位置感知)**机制,就是其克敌制胜的“招式”。
传统的MoE(混合专家模型)是在专家层面实现稀疏化,而Model1将这种思想引入到了注意力机制内部。Token级稀疏MLA意味着模型在处理长文本时,不再是对所有历史信息进行无差别的注意力计算,而是实现了更细粒度的、基于Token重要性的动态筛选。
这种机制直接解决了长文本推理中的“显存墙”问题。配合FP8 KV Cache混合精度方案,Model1在推理时使用FP8存储,在矩阵乘法中使用bfloat16保证精度。这种“精打细算”的存储策略,让单卡承载的上下文长度得到了质的飞跃。
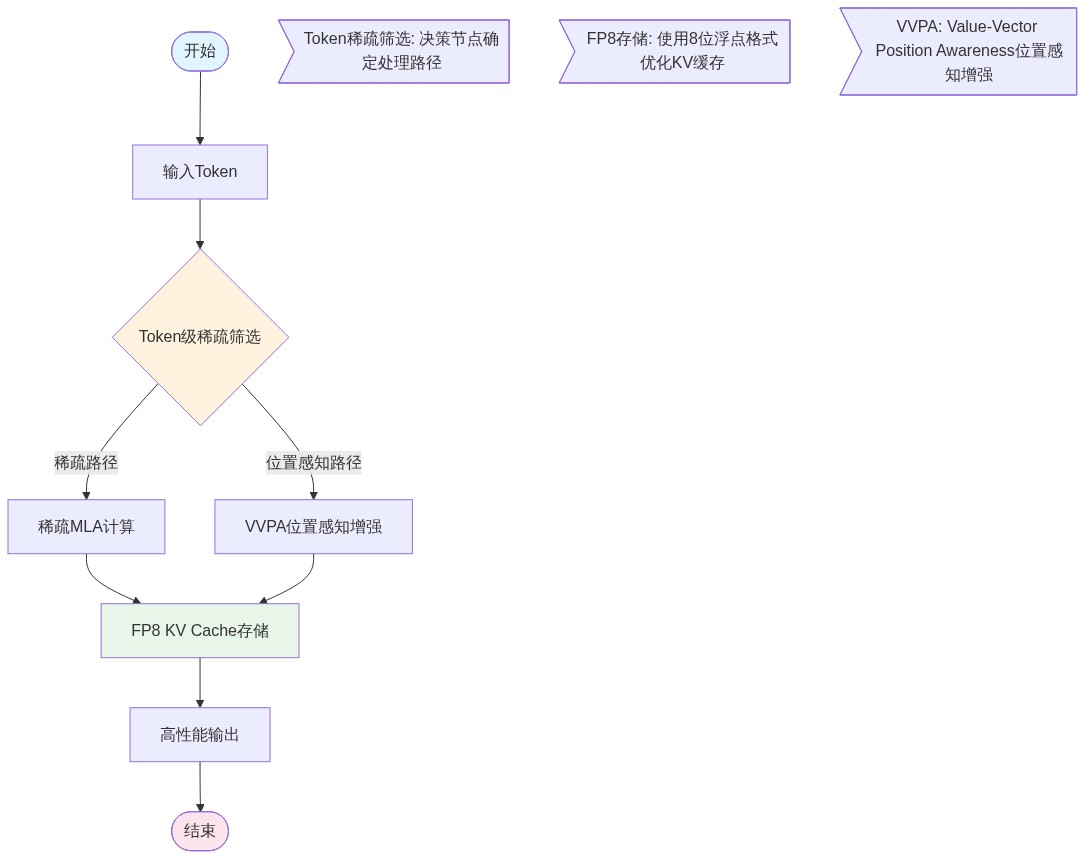
而**VVPA(Value Vector Position Awareness)**的引入,则是为了解决MLA架构在超长文本下的“位置失忆”痛点。在传统的MLA中,随着文本长度增加,位置信息往往会发生衰减。VVPA通过增强数值向量对位置的感知能力,确保了模型在处理128K甚至更长上下文时,依然能精准定位到关键信息。 这对于需要处理海量文档的企业级应用来说,无异于降维打击。
此外,Model1还引入了一个名为Engram的机制。从代码实现来看,这极有可能是针对分布式存储或KV压缩的专项优化。在超大规模集群中,Engram能够优化模型在节点间的存储分布,配合高吞吐需求,将分布式推理的延迟降到最低。
硬件生态的野心:Blackwell架构的“御用”优化
Model1最让人感到“硬核”的地方,在于它对NVIDIA最新**Blackwell架构(SM100)**的深度适配。
根据Model1的相关技术资料显示,该模型在B200 GPU上的稀疏算子性能已经达到了惊人的350 TFlops。这是一个什么概念?这意味着DeepSeek已经完全吃透了Blackwell架构的底层指令集。
Model1不仅支持CUDA 12.9,还针对SM100进行了专门的算子融合优化。 这种优化不是在应用层,而是在内核(Kernel)层。通过对Blackwell新特性的压榨,Model1实现了计算与通信的深度重叠(Overlapping),极大地缓解了大规模并行计算中的瓶颈。
对于我们这些从事AI基础设施建设的人来说,这传递了一个明确信号:未来的大模型竞争,不再仅仅是参数量的竞争,而是对芯片底层利用率的竞争。 DeepSeek通过Model1证明了,他们不仅能写出顶级的算法,还能写出最硬核的驱动级代码。

商业范式转移:从“算力黑洞”到“普惠智能”
作为“东哥AI智能体”的创作者,我一直在思考:这些高大上的底层技术,对于普通企业和工作室到底意味着什么?
Model1给出的答案是:成本的断崖式下跌。
在过去,定制一个私有化的大模型,企业需要面对高昂的算力成本和显存开销。但随着Model1这种极致优化架构的成熟,情况正在发生改变:
- KV Cache压缩带来的硬件降级:由于MLA和FP8混合精度的优化,原本需要8张H100才能跑起来的长文本推理,现在可能只需要2-4张,甚至在更低端的显卡上也能实现流畅运行。
- 分布式存储优化降低门槛:Engram机制让中小型企业可以利用更灵活的硬件组合(如多台低配服务器联机)来部署高性能模型,而不必死磕昂贵的单体大机。
- 定制化方案的精准落地:在“东哥AI智能体”为企业提供定制化方案时,我们可以基于Model1这种高效率底座,为工作室开发更轻量、更垂直的智能体。这意味着AI不再是巨头的游戏,而是每一个工作室都能负担得起的生产力工具。
Model1的出现,实际上是在重新定义AI的“商业边际成本”。 当推理成本降低到一定程度,AI智能体将从“偶尔调用的工具”变成“时刻在线的数字员工”。

总结与展望:DeepSeek-V4的黎明
Model1虽然目前仍处于开发阶段,但它所展示的技术路径已经清晰可见。它不仅是DeepSeek Coder或DeepSeek LLM的简单延续,更是DeepSeek对AGI基础设施的一次全面重构。
我们可以预见,即将到来的DeepSeek-V4将会是一个:
- 硬件感知度极高:完美适配Blackwell等下一代芯片。
- 长文本处理近乎无限:通过VVPA和稀疏MLA彻底解决上下文焦虑。
- 推理成本极低:让大规模商业化部署成为可能。
对于开发者和企业主来说,现在的关键不是等待V4的发布,而是紧跟Model1所代表的工程趋势。在AI时代,理解底层逻辑的人,才能在算力霸权的裂缝中找到真正的商业机会。
DeepSeek的“工程派”哲学告诉我们:通往AGI的道路,不仅铺满了神经元,更铺满了经过极致优化的CUDA代码。
本文部分图片来源于网络,版权归原作者所有,如有疑问请联系删除。
