

别刷 LeetCode 了,大人时代变了
过去这3年,AI 圈发生的事情比这辈子剩下的头发还要多。如果你现在走进 DeepMind 或者 OpenAI 的面试还在展示怎么翻转二叉树,面试官大概率会慈祥地看着你,然后把你送出门。
现在的 LLM 面试,考的是什么?是显存的艺术,是算力的压榨,是如何在成千上万张 H100 炸掉之前把 Loss 降下去。
今天,带大家拆解“Top 26 LLM 面试题”。坐稳了,我们要发车了。
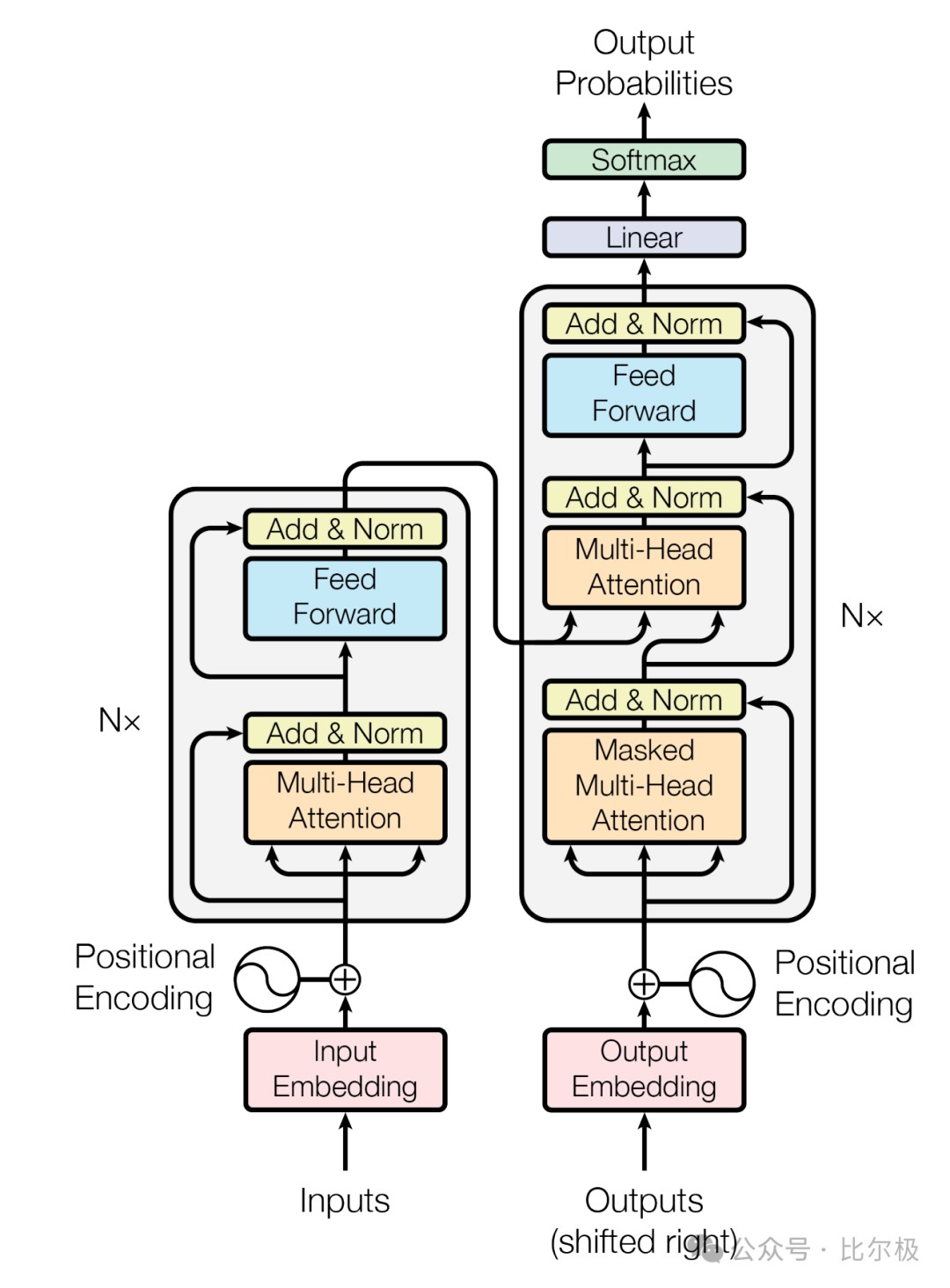
第一章:基石架构 —— 别问,问就是“炼丹”技巧
这部分考察的是你对模型“身体构造”的理解。别只会调包,得知道里面的螺丝是怎么拧的。
- RoPE (旋转位置编码):为什么要转圈圈?[Google]
面试官: “RoPE 是怎么工作的?为什么它比绝对位置编码好?”
**理解一下:**早期的位置编码是“加”上去的(x + p),简单粗暴,但模型根本记不住“相对距离”。
RoPE (Rotary Positional Embeddings) 是个数学天才。它把词向量扔进复数域,通过旋转角度来标记位置。
神奇的是,当你算 Attention (q · k) 时,绝对位置 m 和 n 抵消了,只剩下了 (m - n)。这意味着:只要两个词距离一样,它们的相互作用就一样。
这让模型在处理长文本时,虽然没见过这么长的位置,但认识这个“相对旋转”的模式,从而具备了外推能力 。
- Chinchilla Scaling Laws:别再无脑堆参数了[Google]
面试官: “什么是 Chinchilla Scaling Laws?它打了谁的脸?”
**理解一下:**以前大家(尤其是 GPT-3 那个时代)觉得“大就是好”,无脑堆参数。DeepMind 的 Chinchilla 论文出来说:“你们都练错了!”
核心结论是:对于给定的算力预算,模型参数量和训练数据量应该等比例增加。最佳比例大概是 20 个 Token 对应 1 个参数。
这意味着大多数旧模型(GPT-3)都是“虚胖”——参数太大,数据没吃够。现在的趋势是:模型做小,数据喂爆(Llama 3 更是丧心病狂地用了 Chinchilla 推荐量的几十倍数据)。
- Causal vs. Bidirectional Attention:偷看答案是不对的[Google]
面试官: “因果注意力(Causal)和双向注意力(Bidirectional)有啥区别?”
理解一下:
-
Causal (GPT系列): 就像 写日记。你只能看到已经写好的字,不能预知未来。这是为了生成文本(Generative)。如果不做 Mask,模型就会“偷看”后面的词,训练时 Loss 降得飞快,推理时啥也不会。
-
Bidirectional (BERT系列): 就像 做阅读理解。你可以同时看上下文,把句子琢磨透。这适合做分类、理解,但没法用来聊天。
- KV Cache:显存杀手[Google]
面试官: “为什么推理时需要 KV Cache?”
**理解一下:**这是 LLM 推理的第一大考点。
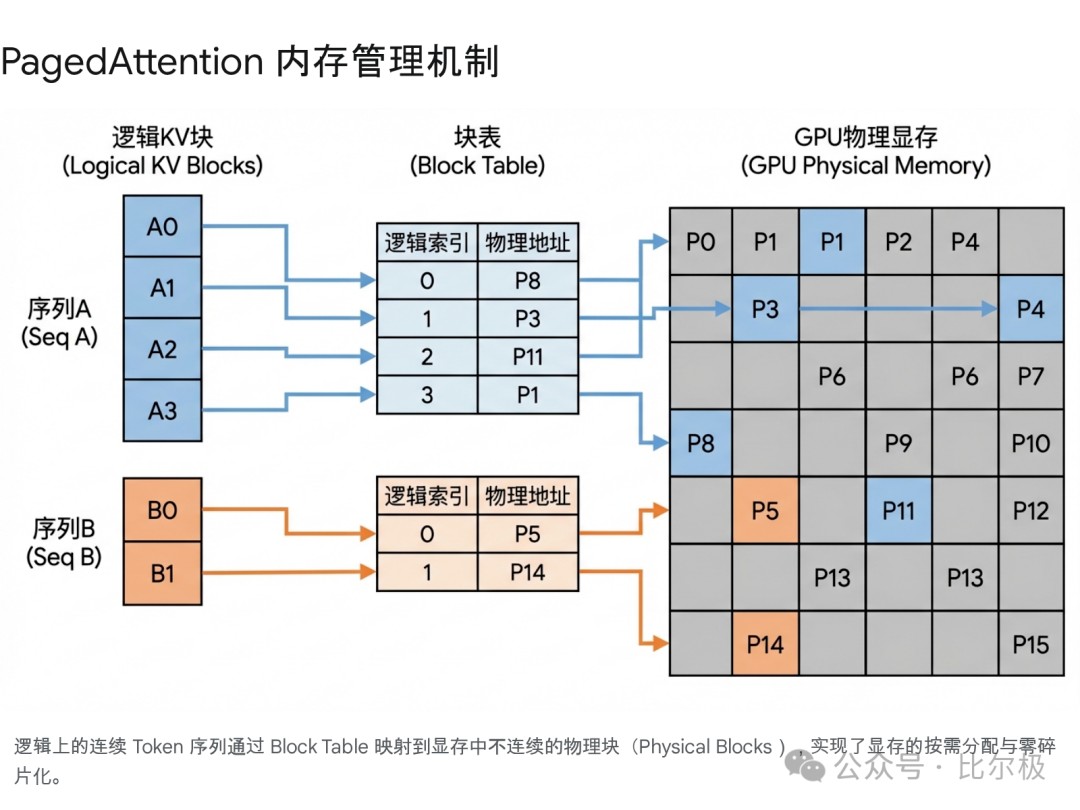
没有 KV Cache,生成第 1000 个词的时候,你需要把前 999 个词的 Attention 全都重算一遍。这就像为了写书的下一页,必须把整本书从头背诵一次。
KV Cache 就是把算好的 Key 和 Value 存下来(显存:危!)。
虽然这让计算量从 O(T²) 降到了 O(T),但代价是显存爆炸。这也是为什么现在 MQA/GQA 这么火的原因。
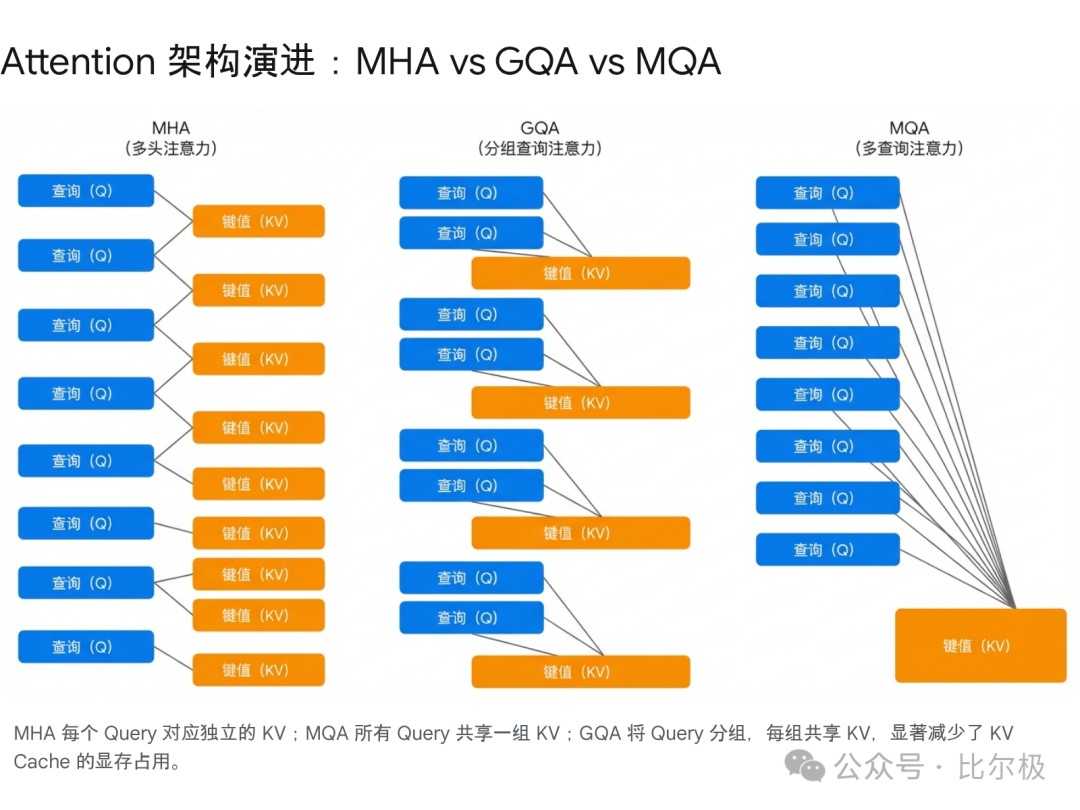
- Transformer 训练不稳定性:为什么 Loss 会炸?[DeepMind]
面试官: “大规模训练时,Transformer 为什么会不稳定?怎么救?”
**理解一下:**当你把模型叠到 100 层,梯度稍微有点波动,传到底层就变成了海啸。
罪魁祸首通常是:
-
Normalization 位置不对: 以前用 Post-LN,现在全改 Pre-LN 或 RMSNorm 了,为了让梯度流更顺畅。
-
初始化太浪: 权重不能太大,得压住。
-
学习率预热 (Warmup): 刚开始训练时模型是懵的,梯度是乱的,你得让它先“热身”一下,别上来就猛跑。
- Mixture of Experts (MoE):如何假装自己很大?[DeepMind]
面试官: “MoE 的原理是什么?它怎么省钱?”
**理解一下:**MoE 就是 “一群臭皮匠,顶个诸葛亮”。
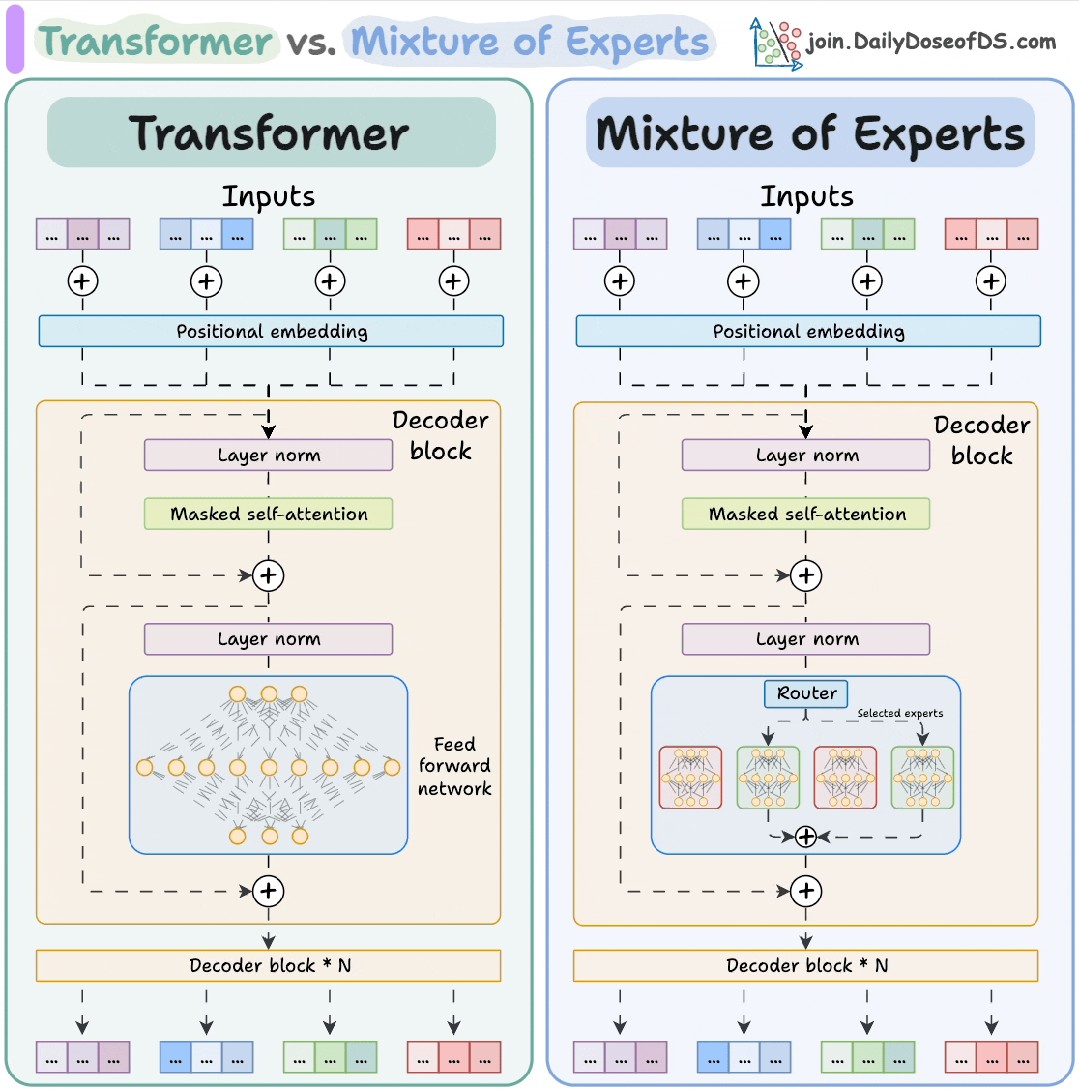
它把一个大层拆成很多小专家(Experts)。对于每个 Token,路由器(Router)只挑 2 个最懂的专家来处理。
-
结果: 模型参数量看着吓人(比如 8x7B),但推理时只激活了一小部分。
-
好处: 同样的算力,你可以把模型容量撑得很大,记住更多知识。
第二章:工程落地 —— 别谈理想,谈谈显存和延迟
这部分是系统架构师的主场。模型再好,跑不起来也是白搭。
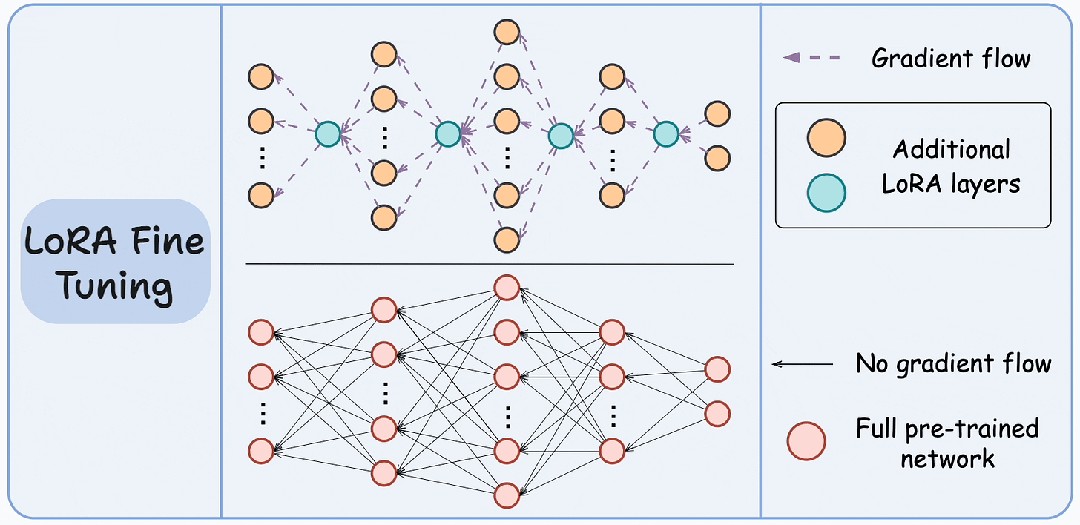
- LoRA:穷人的法拉利 [Amazon]
面试官: “LoRA 是怎么工作的?”
**理解一下:**全量微调(Full Fine-tuning)太贵了,那是富人的游戏。
LoRA (Low-Rank Adaptation) 的思路是:“大哥(主权重)你别动,我在旁边挂个小弟。”
它冻结原模型,只训练两个极小的低秩矩阵 A 和 B。
这不仅省显存,而且可以在同一个底座模型上挂载几百个不同的 LoRA 适配器,随时切换,简直是 SaaS 业务的神器 。
- Distillation (蒸馏):老师傅带徒弟 [Meta]
面试官: “什么是模型蒸馏?”
**理解一下:**找个 GPT-4 这种“老师傅”,产生一堆高质量数据(或者 Logits),然后逼着一个 7B 的“小徒弟”去模仿。由于老师傅已经把知识嚼碎了(Soft Targets),小徒弟学起来比直接看原始数据快得多。
- Latency vs. Throughput vs. Token Efficiency:系统的三维权衡 [Amazon]
面试官: “怎么评估 LLM 系统的性能?”
理解一下:
-
Latency (延迟): 用户等多久看到第一个字?(TTFT)。太慢用户就关网页了。
-
Throughput (吞吐): 一秒钟能吐多少字?这决定了你要买多少张卡。
-
Token Efficiency: 这次生成花了多少钱?
-
坑点: 往往 Latency 和 Throughput 是互斥的。Batch Size 大了,吞吐高了,但每个人等待的时间也长了。
- Continuous Batching:永不停车的流水线
面试官: “Static Batching 有什么问题?Continuous Batching 怎么解决?”
理解一下:
-
Static Batching 是“同进同出”,大家得等最慢的那个人吃完饭才能一起走。
-
Continuous Batching 是 “回转寿司”。谁吃完了谁走,空出来的位子(显存)立马塞进新的请求。显存利用率直接拉满。
第三章:数据与对齐 —— 教 AI 做个“好人”
算法决定下限,数据决定上限,对齐决定它是不是个疯子。
- Pretraining vs SFT vs RLHF Loss:灵魂三问[OpenAI]
面试官: “这三个阶段的 Loss 有什么本质区别?”
理解一下:
-
Pretraining: Next Token Prediction。目标是 “预测”。学的是概率分布,不管对错,只管像不像人话。
-
SFT: 还是 Next Token Prediction,但数据变了。目标是 “模仿”。学的是“像个好助理一样说话”。
-
RLHF: Maximize Reward。目标是 “取悦”。学的是“人类(或者 Reward Model)喜欢什么我就说什么”。
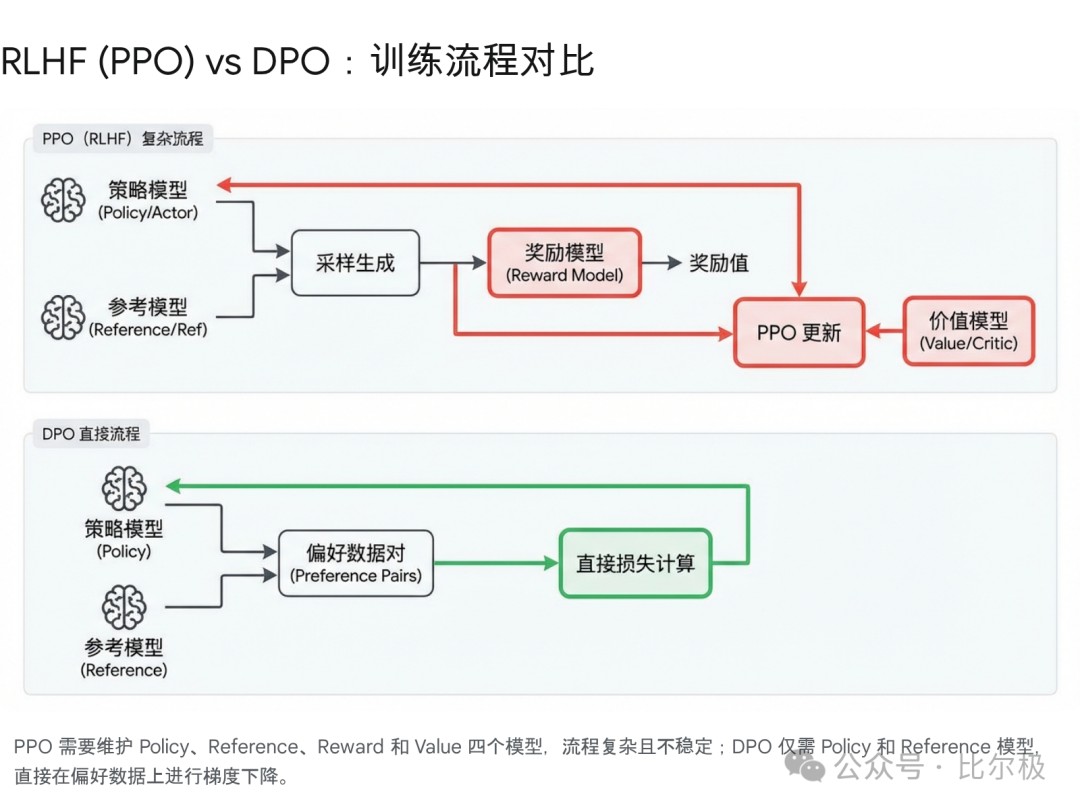
- RLHF Pipeline:驯兽指南[OpenAI]
面试官: “走一遍 RLHF 的流程。”
理解一下:
-
SFT: 先教会它听人话。
-
Reward Modeling: 找人来给它的回答打分(或者排序),训练一个“判卷老师”。
-
PPO/RL: 让模型去考试,判卷老师打分,根据分数调整模型。
最难的不是 RL,而是只要你的判卷老师(RM)有一点偏见,模型就会立刻学会钻空子(Reward Hacking)。
- Preference vs. Reward Modeling:相对论[OpenAI]
面试官: “偏好模型和奖励模型有啥区别?”
理解一下:
-
Preference Model: 学的是 “比较”(A 比 B 好)。这更符合人类直觉,因为人很难给出一个绝对分数(“这句话值 3.75 分”?)。
-
Reward Model: 必须输出一个 “绝对分数”。通常我们是用 Preference Data 训练 Reward Model,或者直接用 DPO 绕过 Reward Model。
- Constitutional AI:AI 管 AI[Anthropic]
面试官: “什么是 Constitutional AI?”
**理解一下:**Anthropic 的绝活。与其让人类一个个标数据,不如给 AI 写一部 “宪法”(比如“要无害”、“要礼貌”)。然后让 AI 自己根据宪法去修改自己的回答(Self-Critique),生成微调数据。说白了就是 “左脚踩右脚上天”,用 AI 的逻辑能力来监督 AI。
- DPO vs PPO (延伸):数学家的胜利[Anthropic]
理解一下: PPO 太难调了,DPO 直接把 RL 问题变成了分类问题,优雅!
第四章:实战场景 —— RAG、Agent 与 幻觉
这是应用层最头疼的问题。
- Hallucination:一本正经胡说八道[OpenAI]
面试官: “为什么会产生幻觉?怎么治?”
**理解一下:**幻觉是 Feature,不是 Bug。LLM 本质上就是个概率生成器。它不知道什么是真理,只知道哪个词接在后面概率大。
治疗方案:
-
RAG(给它翻书)。
-
降低 Temperature(别让它太浪)。
-
CoT(让它慢点想)。
- Hallucination in RAG:即使开了卷卷心菜,它也能炒糊[OpenAI]
面试官: “为什么接了 RAG 还是会幻觉?”
理解一下:
-
检索错了: 找出来的文档跟问题无关,模型只能瞎编。
-
模型自负: 模型觉得“训练数据里不是这么说的”,非要用自己的记忆覆盖检索结果。
-
没话找话: 检索结果里没有答案,模型不敢说“不知道”,强行编一个。
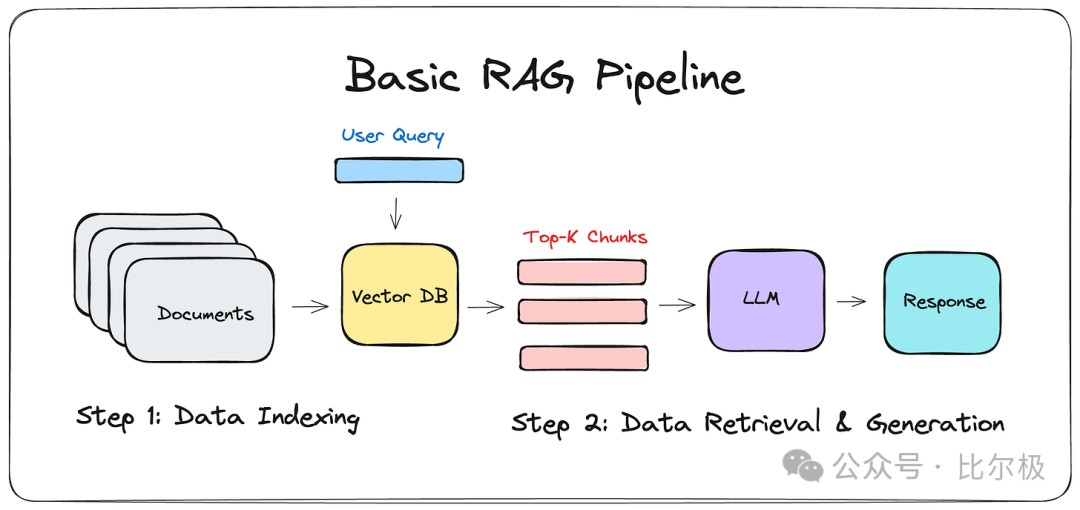
- RAG Pipeline:不仅是搜一下[Amazon]
面试官: “怎么设计一个企业级 RAG?”
**理解一下:**别以为 LangChain.run() 就行了。
-
Data: 清洗、分块(Chunking)是脏活累活。
-
Indexing: 混合检索(向量+关键词)是必须的。
-
Retrieval: 重排序(Rerank)不能少。
-
Generation: 提示词工程要做好引用约束。
这是一个系统工程,不是算法问题。
- SLMs in RAG:杀鸡焉用牛刀[Meta]
面试官: “为什么在 RAG 里小模型(SLM)有时候更好?”
**理解一下:**在 RAG 里,难活(记忆知识)被数据库干了。模型只需要干一件事:阅读理解。小模型(如 Llama-8B)通常更听话,更不容易发散。大模型有时候太聪明了,喜欢加戏。
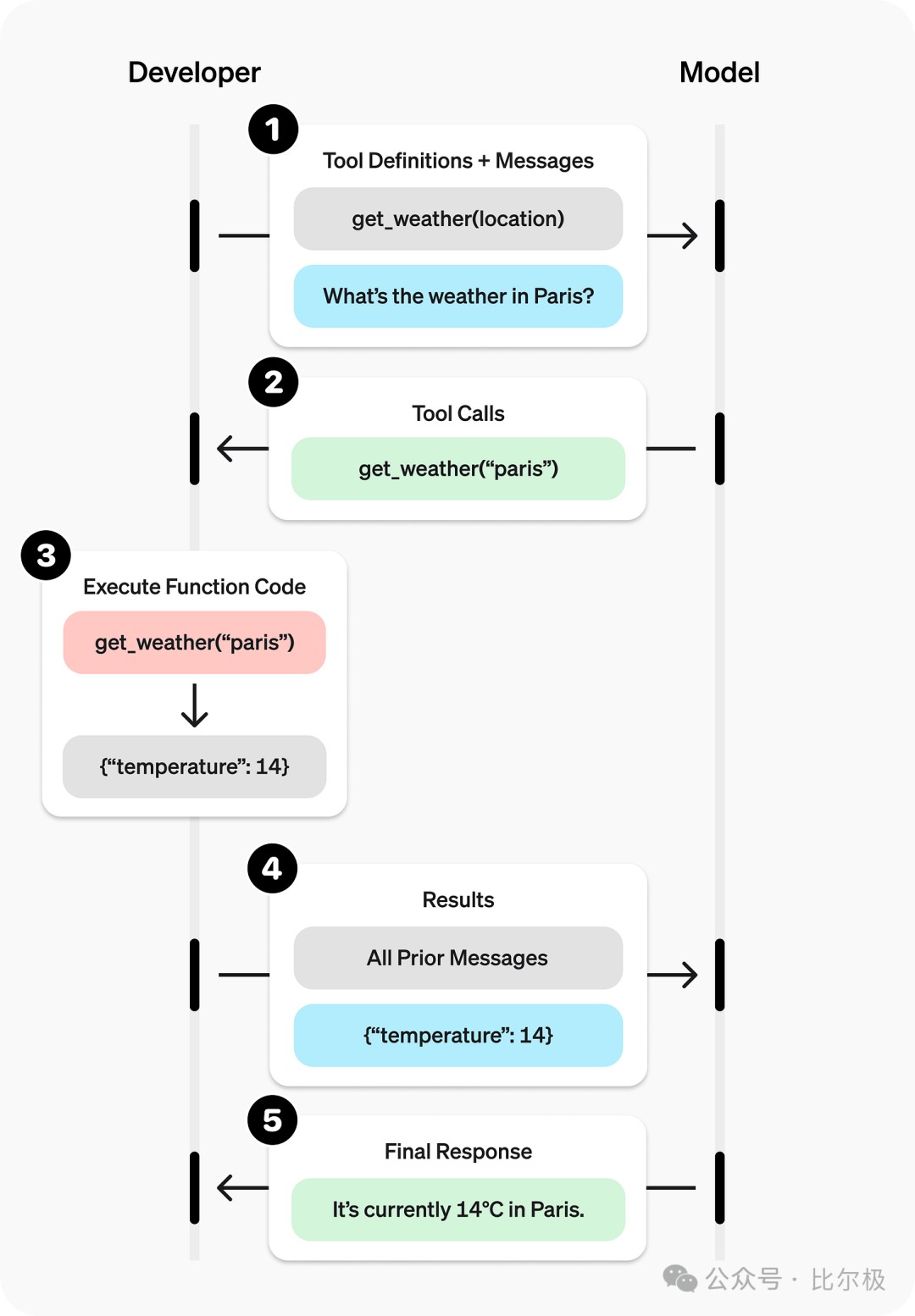
- Tools / Function Calling:给 AI 装上手[Amazon]
面试官: “Function Calling 的意义是什么?”
**理解一下:**把 LLM 从 “聊天机器人”变成“打工人”。它不再只是瞎猜天气,而是能生成一个 JSON 也就是 API 请求,去调天气预报接口。这让 LLM 能和现实世界交互。
- Chain-of-Thought (CoT):慢思考[Anthropic]
面试官: “CoT 为什么有用?有啥副作用?”
**理解一下:**让模型“Let's think step by step”。这其实是用更多的 Token 换取计算深度。就像人算数学题要打草稿一样。副作用: 废话变多了,推理成本变高了,而且如果不加掩护,它可能会在思考过程中把不该说的秘密(比如 System Prompt 的指令)给念叨出来。
第五章:微调与评估 —— 细节决定成败
- Fine-tuning for Jargon & Forgetting:捡了芝麻丢西瓜[Amazon]
面试官: “怎么让模型学会公司黑话,又不忘记通用知识?”
**理解一下:**这就是灾难性遗忘 (Catastrophic Forgetting)。你教它公司代码规范,它可能就把 Python 语法忘了。
解法:
-
混着练: 微调数据里必须掺杂通用数据。
-
用 LoRA: 别动主脑子。
-
用 RAG: 别微调了,直接外挂词典吧。
- Verbosity:话痨怎么治?
面试官: “模型太啰嗦怎么办?”
**理解一下:**这是 RLHF 惯出来的毛病。因为标注员通常觉得“写得长 = 写得好”。
怎么治?
-
Prompt 强行勒令“简洁”。
-
DPO 数据集里专门搞一些“长 vs 短”的样本,告诉模型短的更好。
- Model Steerability:听话程度[Apple]
面试官: “什么是可操控性?”
**理解一下:**就是你让它扮猫,它别给你扮狗。提高 Steerability 需要高质量的指令微调数据(Instruction Tuning)和 System Prompt 的精心设计。
- Helpfulness without Secrets:保密协议[Apple]
面试官: “怎么让模型既有用,又不泄露公司机密?”
**理解一下:**千万别把机密放进训练数据里!别指望模型能“学会”保密。一旦进去了,Prompt 注入攻击总能把它套出来。正解: RAG + 权限控制。检索的时候就卡住权限,模型根本看不到它不该看的东西。
- Eval: Helpfulness, Factuality, Robustness, Toxicity[Apple]
面试官: “怎么全方位评估一个 LLM?”
**理解一下:**别只看 Loss。
-
Helpfulness: 找 GPT-4 当裁判(LLM-as-a-Judge)。
-
Factuality: RAG 验证,查引用。
-
Robustness: 搞点对抗样本,故意输错字,看它崩不崩。
-
Toxicity: 必须要测,不然上线第一天就被公关危机搞死。
看完这 26 题,你会发现,现在的 AI 面试早就不是背公式了。面试官考的是你的工程直觉,是你面对显存墙、数据脏、模型幻觉这些真实世界烂摊子时的生存能力。如果你能把这些问题用大白话(最好带点痛苦的表情)讲清楚,恭喜你,你已经是个合格的架构师了。
参考文献:
-
Rotary Positional Embeddings and its Math - Kannav Sethi
-
Demystifying GQA — Grouped Query Attention for Efficient LLM Pre-training - Medium