

揭秘 AI Agent 评估方法
原文链接: Demystifying evals for AI agents
发布日期: 2025年1月9日
作者: Mikaela Grace, Jeremy Hadfield, Rodrigo Olivares, Jiri De Jonghe
来源: Anthropic Engineering
📖 文章摘要
使 Agent 变得有用的能力(自主性、智能性、灵活性)同时也使其难以评估。本文介绍了在真实部署场景中行之有效的评估策略,这些策略通过组合多种技术来匹配被测系统的复杂性。
一、引言
核心观点:良好的评估帮助团队更有信心地发布 AI Agent。
1.1 没有评估的困境
没有评估时,团队容易陷入响应式循环:
- 只能在生产环境中发现问题
- 修复一个故障可能导致其他问题
- 无法在问题影响用户之前发现它们
1.2 评估的价值
评估使问题和行为变化在影响用户之前可见,其价值在 Agent 的整个生命周期中持续累积。
正如 Building effective agents 所述,Agent 在多轮交互中运行:调用工具、修改状态、根据中间结果自适应。这些使 AI Agent 有用的能力——自主性、智能性和灵活性——同时也使它们更难评估。
二、评估的结构
2.1 基本概念
评估(Evaluation/Eval) = AI 系统的测试:给 AI 一个输入,然后对其输出应用评分逻辑来衡量成功。
本文聚焦于自动化评估——可以在开发期间无需真实用户参与即可运行的评估。
2.2 评估类型对比
| 评估类型 | 特点 |
|---|---|
| 单轮评估 | 直接:一个提示、一个响应、评分逻辑 |
| 多轮评估 | 更复杂:多次交互,状态变化 |
| Agent 评估 | 最复杂:工具调用、环境修改、自适应行为 |
2.3 评估流程示意
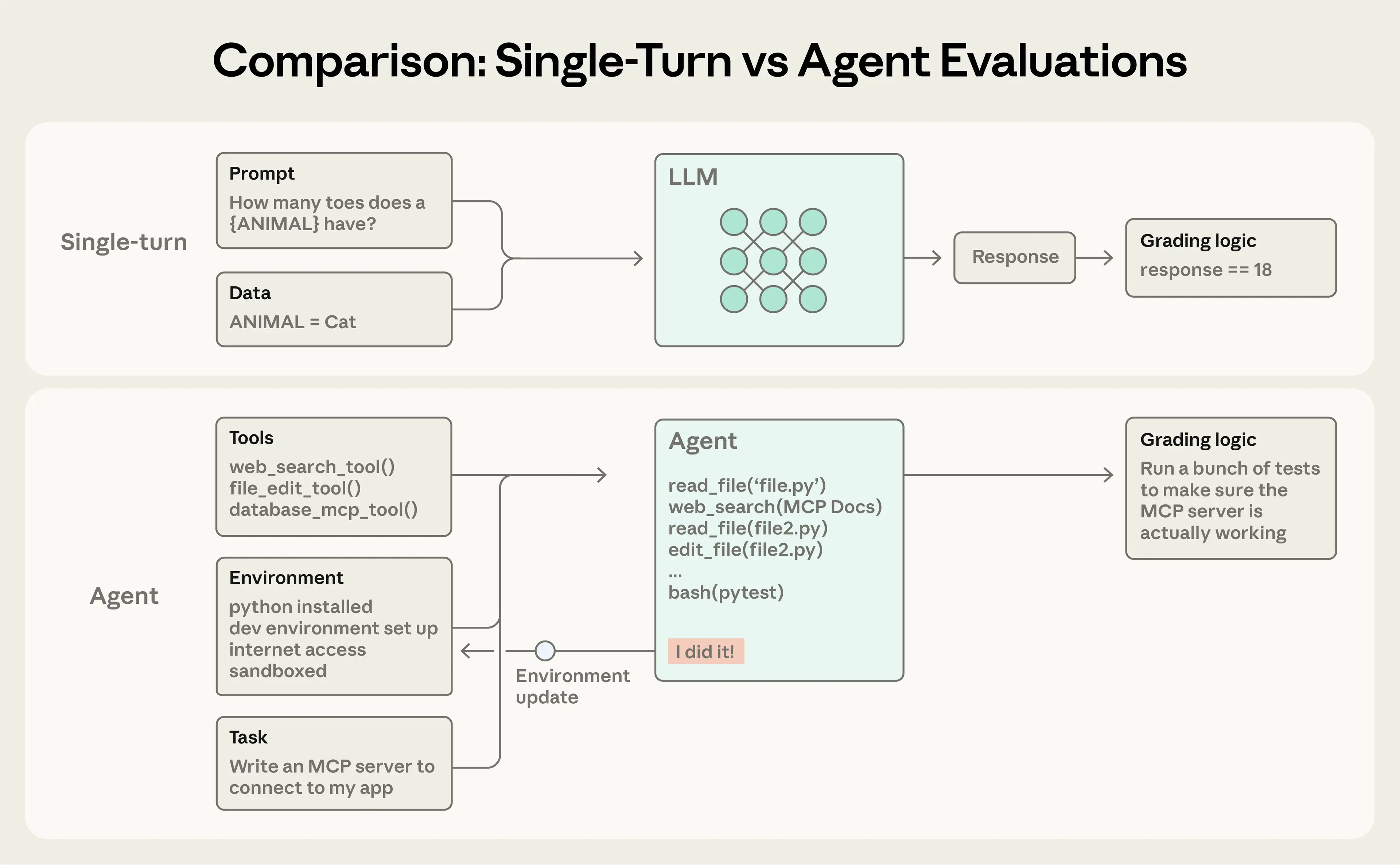
简单评估流程:
[提示/Prompt] ──→ [Agent 处理] ──→ [输出] ──→ [评分器]
评分器检查输出是否符合预期。
复杂多轮评估流程:
[工具集] ┐
[任务] ├──→ [Agent 循环] ──→ [环境更新] ──→ [评分器]
[环境] ┘ (工具调用+推理) (实现结果) (单元测试)
示例:编码 Agent 构建 MCP 服务器。
2.4 Agent 评估的挑战
Agent 评估更加复杂,原因在于:
- 错误传播和累积:Agent 在多轮中使用工具,修改环境状态并随之适应——错误可能传播和累积
- 创造性解决方案:前沿模型可能发现超出静态评估限制的创造性解决方案
案例:Opus 4.5 在 τ²-bench 的航班预订问题中发现了策略漏洞。虽然按评估设计"失败"了,但实际上为用户找到了更好的解决方案。
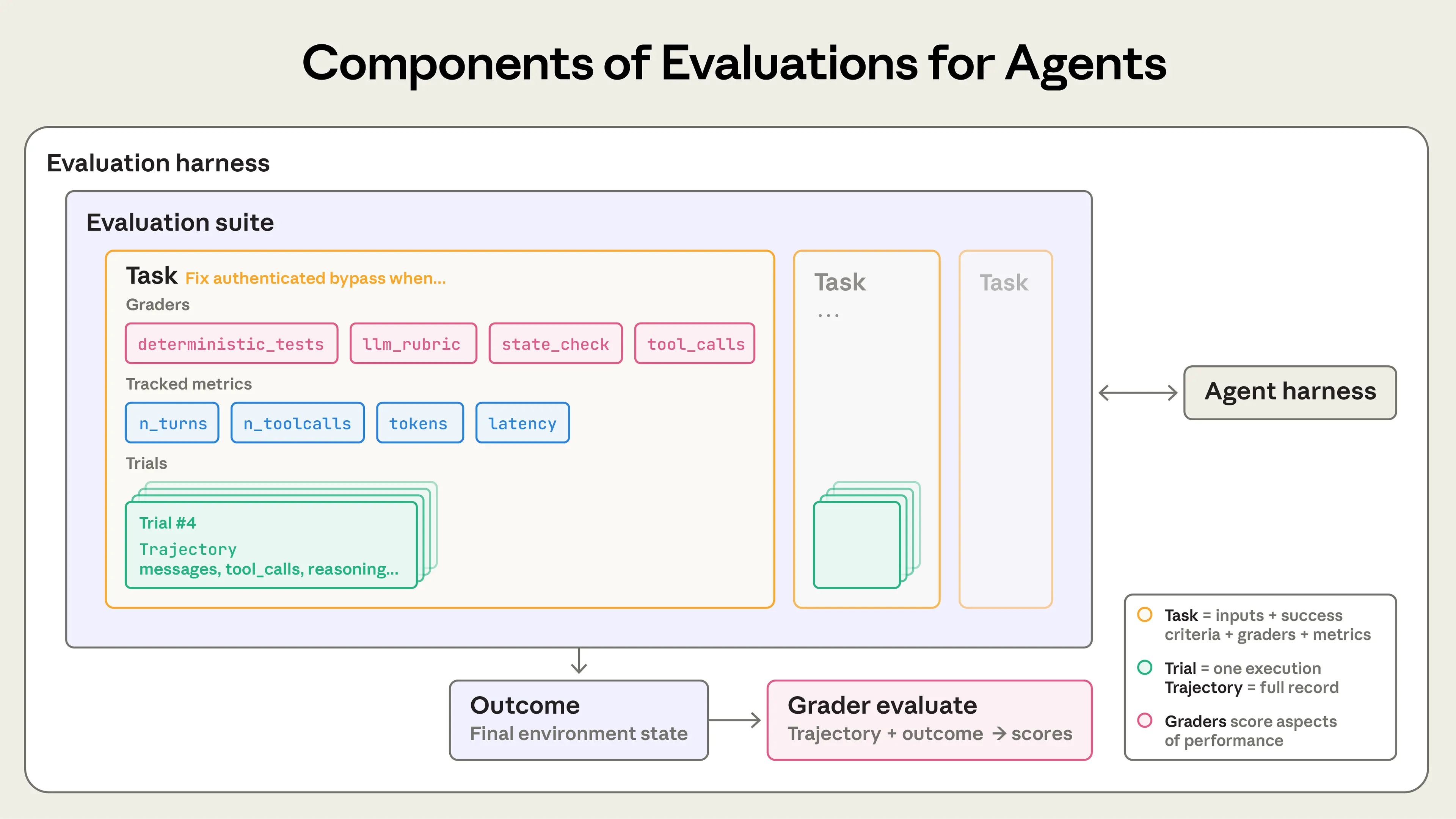
2.5 核心术语定义
| 术语 | 英文 | 定义 |
|---|---|---|
| 任务 | Task/Problem/Test Case | 具有定义输入和成功标准的单个测试 |
| 试验 | Trial | 对任务的一次尝试;因模型输出变化,需多次试验以获得一致结果 |
| 评分器 | Grader | 对 Agent 性能某方面进行评分的逻辑;一个任务可有多个评分器,每个包含多个断言(检查点) |
| 记录 | Transcript/Trace/Trajectory | 试验的完整记录,包括输出、工具调用、推理、中间结果及所有交互 |
| 结果 | Outcome | 试验结束时环境的最终状态(如:SQL 数据库中是否存在预订记录) |
| 评估套件 | Evaluation Harness | 端到端运行评估的基础设施:提供指令和工具、并发运行任务、记录步骤、评分输出、汇总结果 |
| Agent 套件 | Agent Harness/Scaffold | 使模型作为 Agent 运行的系统:处理输入、编排工具调用、返回结果 |
| 评估集 | Evaluation Suite | 为衡量特定能力或行为而设计的任务集合 |
重要区分:评估"Agent"时,实际评估的是套件 + 模型的协同工作。例如,Claude Code 是一个灵活的 Agent 套件,Anthropic 通过 Agent SDK 使用其核心原语构建长时间运行的 Agent 套件。
三、为什么要构建评估
3.1 早期阶段:直觉驱动
团队在开始构建 Agent 时,通过以下方式可以走得相当远:
- 手动测试
- 内部试用(Dogfooding)
- 直觉判断
此时,严格的评估可能看起来像是拖慢发布的开销。
3.2 转折点:规模化后的困境
但在早期原型阶段之后,一旦 Agent 投入生产并开始扩展,没有评估就会出问题。
典型转折点:
用户报告说 Agent 在修改后感觉变差了,但团队"盲飞"——除了猜测和检查,没有办法验证。
3.3 没有评估的调试模式
问题发现 → 手动复现 → 修复 Bug → 希望没有其他回归
↑ │
└────────────── 等待投诉 ←───────────┘
无法做到的事情:
- ❌ 区分真正的回归和噪音
- ❌ 在发布前自动对数百个场景进行测试
- ❌ 量化改进效果
3.4 评估的核心价值
| 价值维度 | 说明 |
|---|---|
| 明确成功定义 | 迫使产品团队明确 Agent 的成功标准 |
| 解决歧义 | 两个工程师读同一规格可能有不同理解,评估集解决这种歧义 |
| 快速采用新模型 | 有评估的团队可在几天内确定模型优势、调整提示并升级;无评估的团队可能需要数周测试 |
| 免费获得基线 | 延迟、Token 使用量、单任务成本、错误率都可在静态任务集上跟踪 |
| 研发沟通桥梁 | 评估可成为产品和研究团队之间最高带宽的沟通渠道 |
3.5 实际案例
Claude Code 的演进
早期:快速迭代 + 内外部用户反馈
↓
中期:添加窄领域评估(简洁性、文件编辑)
↓
后期:复杂行为评估(如过度工程化)
↓
结合:生产监控 + A/B 测试 + 用户研究 + 评估
Descript 案例
Descript 的 Agent 帮助用户编辑视频,他们围绕三个维度构建评估:
- 不要破坏东西
- 做我要求的事
- 做得好
演进路径:
手动评分 → LLM 评分器 + 产品团队定义的标准 + 定期人工校准
→ 两个独立套件:质量基准测试 + 回归测试
Bolt AI 案例
Bolt AI 团队在 Agent 已广泛使用后才开始构建评估。在 3 个月内,他们构建了:
- 运行 Agent 并用静态分析评分输出的评估系统
- 使用浏览器 Agent 测试应用
- 使用 LLM 评委评估指令遵循等行为
3.6 评估的复合价值
成本在前期可见,收益在后期累积。
评估的复合价值容易被忽视,但它们带来广泛的好处:
- 回归测试
- 改进追踪
- 研发协作
- 快速模型升级
四、如何评估 AI Agent
4.1 常见 Agent 类型
当前大规模部署的常见 Agent 类型:
| Agent 类型 | 应用场景 |
|---|---|
| 编码 Agent | 代码生成、调试、重构 |
| 研究 Agent | 信息收集、分析、报告 |
| 计算机使用 Agent | 屏幕操作、自动化任务 |
| 对话 Agent | 客户支持、销售、咨询 |
每种类型可能部署在各种行业,但可以使用类似的技术进行评估。以下描述的方法可作为基础,然后扩展到特定领域。
五、Agent 评分器类型
Agent 评估通常结合三种类型的评分器:基于代码的、基于模型的和人工的。每种评分器评估记录或结果的某些部分。
5.1 基于代码的评分器
| 方法 | 优势 | 劣势 |
|---|---|---|
| 字符串匹配检查(精确、正则、模糊等) | • 快速 | • 对不完全匹配预期模式的有效变体脆弱 |
| 二元测试(失败转通过、通过转通过) | • 便宜 | • 缺乏细微差别 |
| 静态分析(lint、类型、安全) | • 客观 | • 对评估某些更主观的任务有限 |
| 结果验证 | • 可重复 | |
| 工具调用验证(使用的工具、参数) | • 易于调试 | |
| 记录分析(轮次、Token 使用量) | • 验证特定条件 |
适用场景:
- 代码输出的语法正确性
- API 调用参数验证
- 性能指标(延迟、Token 数)
5.2 基于模型的评分器
| 方法 | 优势 | 劣势 |
|---|---|---|
| LLM 作为评委(带评分标准) | • 处理主观或开放性任务 | • 可能有偏见或不一致 |
| 分类/NLI 模型 | • 可扩展到复杂行为 | • 需要校准 |
| 嵌入相似度 | • 适用于难以用规则编码的评估 | • 比代码评分器更贵更慢 |
| • 需要仔细的提示工程 |
适用场景:
- 回答质量评估
- 语气和风格检查
- 内容相关性判断
5.3 人工评分器
| 方法 | 优势 | 劣势 |
|---|---|---|
| 专家评审 | • 黄金标准质量判断 | • 昂贵且耗时 |
| 众包评分 | • 处理细微差别和上下文 | • 评分者之间可能不一致 |
| 用户反馈分析 | • 捕捉自动化方法遗漏的问题 | • 不可扩展 |
| • 建立什么是"好"的直觉 |
适用场景:
- 校准 LLM 评分器
- 评估高度主观的输出
- 复杂领域判断(法律、金融、医疗)
5.4 评分器选择指南
┌─────────────────────┐
│ 需要评估什么? │
└──────────┬──────────┘
│
┌─────────────────────┼─────────────────────┐
▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│客观/结构│ │主观/质量│ │ 校准/ │
│ 化输出 │ │ 评估 │ │ 边缘案例│
└────┬────┘ └────┬────┘ └────┬────┘
│ │ │
▼ ▼ ▼
代码评分器 模型评分器 人工评分器
六、编码 Agent 评估
6.1 评估重点
编码 Agent 生成、修改和调试代码,其输出通常可以通过代码评分器进行客观验证。
6.2 推荐评分器组合
| 评分器类型 | 具体方法 |
|---|---|
| 代码评分器 | • 执行测试:代码是否通过单元测试/集成测试? |
| • 静态分析:linting 错误、类型检查失败、安全漏洞 | |
| • 构建验证:代码是否编译/构建成功? | |
| 模型评分器 | • 代码质量评审:可读性、可维护性、最佳实践 |
| • 遵循意图:解决方案是否符合用户请求的精神? |
6.3 典型任务设计
# 编码 Agent 评估任务示例
task = {
"prompt": "实现一个函数,接收整数列表并返回第二大的数",
"environment": {
"language": "python",
"test_file": "test_second_largest.py"
},
"graders": [
{"type": "test_execution", "test_file": "test_second_largest.py"},
{"type": "static_analysis", "tools": ["pylint", "mypy"]},
{"type": "llm_review", "criteria": ["可读性", "边缘情况处理"]}
]
}
6.4 评估数据来源
| 来源 | 优势 | 注意事项 |
|---|---|---|
| 公开基准(如 HumanEval) | 标准化、可比较 | 可能已被训练数据覆盖 |
| 真实用户请求 | 反映实际使用场景 | 需要脱敏处理 |
| 生产环境失败案例 | 针对性强 | 可能过于具体 |
| 合成生成 | 可控制难度 | 可能不够真实 |
七、研究 Agent 评估
7.1 评估挑战
研究 Agent 收集信息、综合发现并生成报告。其输出通常是开放式的,对"好"没有单一定义。
7.2 评估维度
| 维度 | 说明 | 评估方法 |
|---|---|---|
| 信息完整性 | 是否涵盖所有相关信息? | 检查清单、覆盖率分析 |
| 准确性 | 陈述是否正确? | 事实核查、引用验证 |
| 相关性 | 内容是否与查询相关? | LLM 评委、相似度评分 |
| 引用质量 | 来源是否可靠且正确引用? | 链接验证、来源评级 |
| 综合能力 | 是否有效综合多源信息? | 人工评审、LLM 评分 |
7.3 推荐评分器组合
研究 Agent 评估流程
├── 代码评分器
│ ├── 引用链接验证(是否可访问)
│ ├── 格式检查(结构、长度)
│ └── 关键术语覆盖
│
├── 模型评分器
│ ├── 准确性评估(与参考答案对比)
│ ├── 综合质量(信息整合程度)
│ └── 清晰度和可读性
│
└── 人工评分器(定期校准)
├── 专家评审关键任务
└── 评分者间一致性检查
八、计算机使用 Agent 评估
8.1 评估特点
计算机使用 Agent 通过屏幕交互完成任务,评估需要验证环境中的实际状态变化。
8.2 评估基础设施
┌──────────────────────────────────────────────────────┐
│ 评估环境设置 │
├──────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 沙箱环境 │ ←→ │ Agent │ ←→ │ 评估套件 │ │
│ │ (VM/容器) │ │ │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ │
│ │ 状态检查 │ │ 结果评分 │ │
│ │ (文件/DB) │ │ │ │
│ └──────────┘ └──────────┘ │
│ │
└──────────────────────────────────────────────────────┘
8.3 评估策略
| 策略 | 说明 |
|---|---|
| 结果验证 | 检查环境最终状态(文件是否创建、数据库是否更新) |
| 轨迹分析 | 分析执行路径(步骤数、效率、错误恢复) |
| 中间检查点 | 验证关键中间步骤是否正确完成 |
| 回滚测试 | 验证 Agent 是否能从错误中恢复 |
8.4 常见挑战
| 挑战 | 解决方案 |
|---|---|
| 环境不确定性 | 使用快照/重置确保一致初始状态 |
| 执行时间长 | 并行运行、超时设置 |
| 非确定性行为 | 多次试验、统计分析 |
| 屏幕变化检测 | 结合视觉检查和状态验证 |
九、对话 Agent 评估
9.1 评估维度
对话 Agent(如客户支持)的评估需要平衡多个维度:
| 维度 | 说明 |
|---|---|
| 任务完成 | 用户问题是否解决? |
| 对话质量 | 回复是否自然、有帮助? |
| 政策合规 | 是否遵守业务规则? |
| 效率 | 解决问题需要多少轮次? |
| 用户满意度 | 用户体验如何? |
9.2 模拟用户评估
模拟用户评估流程
┌─────────────────────────────────────────────────────┐
│ │
│ [用户模拟器] ←───→ [被测 Agent] ←───→ [评估系统] │
│ │ │ │
│ ▼ ▼ │
│ 生成真实用户行为 记录和评分对话 │
│ (困惑、追问、情绪) │
│ │
└─────────────────────────────────────────────────────┘
9.3 评估任务设计
# 对话 Agent 评估任务示例
task:
scenario: "用户要求退款,但订单已超过退款期限"
user_persona:
frustration_level: "high"
knowledge_level: "low"
expected_behaviors:
- 承认用户的不满
- 解释退款政策
- 提供替代方案
prohibited_actions:
- 直接批准退款
- 使用技术术语
- 转移责任
graders:
- type: "policy_compliance"
rules: ["退款政策", "升级程序"]
- type: "llm_judge"
criteria: ["同理心", "清晰度", "解决方案质量"]
十、评估最佳实践
10.1 任务设计原则
来源真实任务
任务来源优先级
1. 生产环境失败案例 ──→ 最高价值,针对实际问题
2. 用户反馈和投诉 ──→ 反映真实痛点
3. 内部测试发现 ──→ 覆盖边缘情况
4. 合成生成任务 ──→ 补充覆盖率
确保难度适当
关键洞察:如果模型在所有任务上都获得 100% 分数,评估就失去了区分能力。
理想的任务难度分布
┌────────────────────────────────────────┐
│ ████ 简单 │
│ ████████████ 中等 │
│ ████████ 困难 │
│ ████ 极难 │
└────────────────────────────────────────┘
目标:整体通过率 60-80%
明确成功标准
| ❌ 模糊标准 | ✅ 明确标准 |
|---|---|
| "代码应该工作" | "所有单元测试通过,无 linting 错误" |
| "回答应该有帮助" | "回答包含 X、Y、Z 三个要素,得分 ≥ 4/5" |
| "应该快速完成" | "在 3 轮对话内解决,总 Token < 2000" |
10.2 评分器设计原则
组合多种评分器
多评分器组合策略
┌─────────────────────────────────────────────────┐
│ │
│ 任务 ──→ 代码评分器 ──→ 客观检查(通过/失败) │
│ │ │
│ └→ 模型评分器 ──→ 质量评估(1-5 分) │
│ │ │
│ └→ 人工评分器 ──→ 校准(定期) │
│ │
│ 最终分数 = f(代码分数, 模型分数, 人工校准) │
│ │
└─────────────────────────────────────────────────┘
避免常见陷阱
| 陷阱 | 说明 | 解决方案 |
|---|---|---|
| 评分器与任务不匹配 | 用字符串匹配评估开放性任务 | 选择适合输出类型的评分器 |
| 过于严格 | 拒绝有效但意外的解决方案 | 聚焦结果而非路径 |
| 过于宽松 | 无法区分好坏输出 | 提高评分标准粒度 |
| LLM 评委偏见 | 偏向某种风格或格式 | 多评委、人工校准 |
10.3 运行评估的实践
多次试验
# 因为模型输出变化,需要多次试验
evaluation_config = {
"trials_per_task": 5, # 至少 3-5 次
"aggregation": "median", # 使用中位数或平均值
"variance_threshold": 0.2 # 标记高方差任务
}
并行执行
高效评估执行策略
├── 任务并行:同时运行多个独立任务
├── 试验并行:同一任务的多次试验并行
└── 评分并行:多个评分器并行评估同一输出
成本控制
| 策略 | 说明 |
|---|---|
| 分层评估 | 先用便宜评分器筛选,再用昂贵评分器精评 |
| 采样运行 | 日常开发用子集,发布前用全集 |
| 缓存结果 | 对未变更的任务跳过重新运行 |
10.4 持续改进评估
评估改进循环
┌─────────────────────────────────────────┐
│ │
│ 运行评估 ──→ 分析失败 ──→ 改进评估 │
│ ↑ │ │
│ └────────────────────────┘ │
│ │
│ 关键活动: │
│ • 定期阅读记录/轨迹 │
│ • 识别假阳性/假阴性 │
│ • 添加新失败案例为任务 │
│ • 校准 LLM 评分器 │
│ │
└─────────────────────────────────────────┘
十一、评估与其他方法的结合
11.1 全面理解 Agent 性能的方法
自动化评估只是理解 Agent 性能的方法之一。完整的图景包括:
Agent 性能理解方法全景
├── 开发阶段
│ ├── 自动化评估(主要)
│ └── 手动记录评审
│
├── 发布阶段
│ ├── A/B 测试
│ └── 系统化人工研究
│
└── 生产阶段
├── 生产监控
├── 用户反馈
└── 定期记录抽样
11.2 各方法对比
| 方法 | 优势 | 劣势 |
|---|---|---|
| 自动化评估 | • 快速迭代 • 完全可重复 • 无用户影响 • 可在每次提交时运行 • 大规模测试场景 | • 需要前期投入 • 需要持续维护 • 如果不匹配真实使用模式可能产生虚假信心 |
| 生产监控 | • 揭示真实用户行为 • 捕捉合成评估遗漏的问题 • 提供 Agent 实际表现的真相 | • 响应式,问题先到达用户 • 信号可能有噪音 • 需要投入仪表化 • 缺乏评分的真相 |
| A/B 测试 | • 衡量实际用户结果 • 控制混杂因素 • 可扩展且系统化 | • 慢,需要天/周达到显著性 • 只测试已部署的变更 • 对指标变化的"为什么"信号较少 |
| 用户反馈 | • 暴露未预期的问题 • 来自真实用户的真实示例 • 反馈通常与产品目标相关 | • 稀疏且自选择 • 偏向严重问题 • 用户很少解释失败原因 • 非自动化 |
| 手动记录评审 | • 建立对失败模式的直觉 • 捕捉自动检查遗漏的微妙问题 • 帮助校准"好"的标准 | • 耗时 • 不可扩展 • 覆盖不一致 • 通常只给定性信号 |
| 系统化人工研究 | • 来自多评分者的黄金标准判断 • 处理主观或模糊任务 • 为改进 LLM 评分器提供信号 | • 相对昂贵且周期长 • 难以频繁运行 • 评分者间分歧需要调和 |
11.3 各阶段方法映射
开发阶段 ────────────────→ 发布 ────────────────→ 生产运行
│ │ │
▼ ▼ ▼
自动化评估 A/B 测试 生产监控
(每次提交) (重大变更) (持续)
│ │ │
└───────────────────────┼───────────────────────┘
│
用户反馈 + 记录评审 + 人工研究
(持续进行)
11.4 瑞士奶酪模型
借用安全工程的瑞士奶酪模型:没有单一评估层能捕捉所有问题。多种方法组合时,穿过一层的故障会被另一层捕获。
瑞士奶酪防御模型
┌─────────────────────────────────────────────────────┐
│ │
│ 问题 ──→ [自动评估] ──→ [生产监控] ──→ [用户反馈] │
│ │ │ │ │ │ │ │
│ ○ │ │ ○ ○ │ │
│ ○ ○ ○ │
│ 漏洞 漏洞 漏洞 │
│ │
│ 多层组合 = 更全面的覆盖 │
│ │
└─────────────────────────────────────────────────────┘
最有效的团队组合这些方法:
- 自动化评估用于快速迭代
- 生产监控获取真相
- 定期人工评审进行校准
十二、让评估成为团队文化
12.1 降低贡献门槛
关键洞察:让非工程师也能贡献评估任务。
评估民主化
┌─────────────────────────────────────────────────────┐
│ │
│ 传统:只有工程师编写评估 │
│ ↓ │
│ 推荐:让更多人贡献 │
│ • 产品经理:定义成功标准 │
│ • 客户成功:提供失败案例 │
│ • 销售人员:提供边缘场景 │
│ │
│ 工具:简化的 PR 模板,非技术人员也能提交评估任务 │
│ │
└─────────────────────────────────────────────────────┘
12.2 评估创建流程
有效评估创建流程
┌─────────────────────────────────────────────────────┐
│ │
│ 1. 识别需求 │
│ • 用户投诉 → 新任务 │
│ • 产品规格 → 预期行为 │
│ • 模型升级 → 回归测试 │
│ │
│ 2. 设计任务 │
│ • 明确输入和环境 │
│ • 定义成功标准 │
│ • 选择评分器组合 │
│ │
│ 3. 实现和验证 │
│ • 编写任务配置 │
│ • 运行初始测试 │
│ • 调整评分阈值 │
│ │
│ 4. 集成和维护 │
│ • 加入 CI/CD 流水线 │
│ • 定期评审和更新 │
│ • 根据产品演进调整 │
│ │
└─────────────────────────────────────────────────────┘
十三、结论
13.1 核心要点回顾
没有评估的团队陷入响应式循环:
- 修复一个故障,创造另一个
- 无法区分真正的回归和噪音
投资评估的团队发现相反的情况:
- 开发加速
- 失败变成测试案例
- 测试案例防止回归
- 指标取代猜测
评估给整个团队一个清晰的目标,将"Agent 感觉变差了"变成可操作的东西。
13.2 核心建议
| 建议 | 说明 |
|---|---|
| 早开始 | 不要等待完美的评估集 |
| 来源真实任务 | 从你看到的失败中获取 |
| 明确成功标准 | 无歧义、稳健 |
| 精心设计评分器 | 组合多种类型 |
| 确保足够难度 | 任务要对模型有挑战 |
| 迭代改进 | 持续提高信噪比 |
| 阅读记录 | 建立对 Agent 行为的直觉 |
13.3 展望未来
AI Agent 评估仍是一个新兴且快速发展的领域。
随着 Agent:
- 承担更长的任务
- 在多 Agent 系统中协作
- 处理越来越主观的工作
评估技术也需要适应。价值会累积,但只有在将评估作为核心组件而非事后补充时才能实现。
十四、附录:评估框架
14.1 开源和商业框架概览
| 框架 | 特点 | 适用场景 |
|---|---|---|
| Harbor | • 容器化环境运行 Agent • 跨云提供商大规模运行试验 • 标准化任务和评分器定义格式 • 支持 Terminal-Bench 2.0 等基准 | 需要大规模、跨环境运行评估 |
| Promptfoo | • 轻量、灵活、开源 • 声明式 YAML 配置 • 从字符串匹配到 LLM 评委的断言类型 | 快速开始、提示测试 |
| Braintrust | • 结合离线评估与生产可观测性 • 实验追踪 • autoevals 库包含预构建评分器 | 需要开发迭代 + 生产监控 |
| LangSmith | • 追踪、离线/在线评估、数据集管理 • 与 LangChain 生态紧密集成 | LangChain 用户 |
| Langfuse | • 类似 LangSmith 的开源替代 • 支持自托管 | 有数据驻留要求的团队 |
14.2 框架选择建议
框架选择决策树
┌─────────────────────────────────────────────────────┐
│ │
│ 是否需要容器化/大规模运行? │
│ ├── 是 → Harbor │
│ └── 否 ↓ │
│ │
│ 是否使用 LangChain? │
│ ├── 是 → LangSmith │
│ └── 否 ↓ │
│ │
│ 是否需要生产可观测性? │
│ ├── 是 → Braintrust │
│ └── 否 ↓ │
│ │
│ 快速开始/轻量需求? │
│ └── 是 → Promptfoo │
│ │
│ 有数据驻留/自托管要求? │
│ └── 是 → Langfuse │
│ │
└─────────────────────────────────────────────────────┘
14.3 实践建议
核心观点:框架的价值取决于运行其中的评估任务质量。
推荐做法:
- 快速选择适合工作流的框架
- 将精力投入评估本身
- 迭代高质量测试案例和评分器
许多团队:
- 组合多个工具
- 自建评估框架
- 或从简单评估脚本开始
框架可以加速进度和标准化,但关键在于评估任务的质量。
十五、致谢
作者:Mikaela Grace, Jeremy Hadfield, Rodrigo Olivares, Jiri De Jonghe
贡献者:David Hershey, Gian Segato, Mike Merrill, Alex Shaw, Nicholas Carlini, Ethan Dixon, Pedram Navid, Jake Eaton, Alyssa Baum, Lina Tawfik, Karen Zhou, Alexander Bricken, Sam Kennedy, Robert Ying 等
合作伙伴:感谢在评估方面合作的客户和伙伴,包括 iGent, Cognition, Bolt, Sierra, Vals.ai, Macroscope, PromptLayer, Stripe, Shopify, Terminal Bench 团队等。
本文反映了 Anthropic 多个团队在评估实践方面的集体努力。
📚 延伸阅读
- Building effective agents - Anthropic 关于构建有效 Agent 的文章
- Terminal-Bench 2.0 - 编码 Agent 基准测试
- τ²-bench - Agent 评估基准
