大家好, 我是印刻君. 我们都知道, AI 模型需要通过训练才能具备预测能力. 但你是否好奇, 这个训练的底层逻辑是什么呢? 要想理解训练过程, 关键在于要理解其背后的数学语言.
今天我将为你介绍 AI 训练中的 8 个数学概念, 帮助你更好地理解 AI 训练.
1 残差
我们知道, AI 生成答案的原理其实是在预测答案, 要知道预测得准不准, 需要一个量化指标, 这个指标就是残差.
残差的数学公式是:
ε=y−y^
其中,y 代表实际值, y^ 代表预测值. 残差是实际值与预测值的差值.
举个生活例子, 一斤苹果 5 块钱:
- 如果你猜一斤苹果 8 块钱, 残差就是 5−8=−3
- 如果你猜一斤苹果 3 块钱, 残差就是 5−3=2
2 损失
我们发现, 残差可以为正数, 也可能为负数, 但其实都是预测不准. 我们需要一个全部是正数的指标, 衡量预测准不准, 这个指标就是损失.
AI 训练中常见的损失函数, 是均方误差 (MSE). 思路是: 先把每一个残差平方 (平方后没有负数), 再计算这些平方的平均值.
公式如下:
MSE
=nε12+ε22+...+εn2
==n(y1−y1^)2+(y2−y2^)2+...+(yn−yn^)2
还是用苹果的例子, 8 块钱和 3 块钱的预测值的均方误差为:
MSE苹果价格
=(9+4)/2
=13/2
=6.5
3 导数
知道损失值之后, 我们的下一步目标是把损失变小, 让预测变得越来越准. 这时候就需要用到导数.
3.1 导数: 单参数的变化率
我们先简化场景, 只有一个要猜的参数 (比如苹果单价), 此时均方误差可以写为:
l(x)=(5−x)2, 其中 5 是实际值, x 是预测值
把 l(x) 画成图像, 是一条开口向上的抛物线.
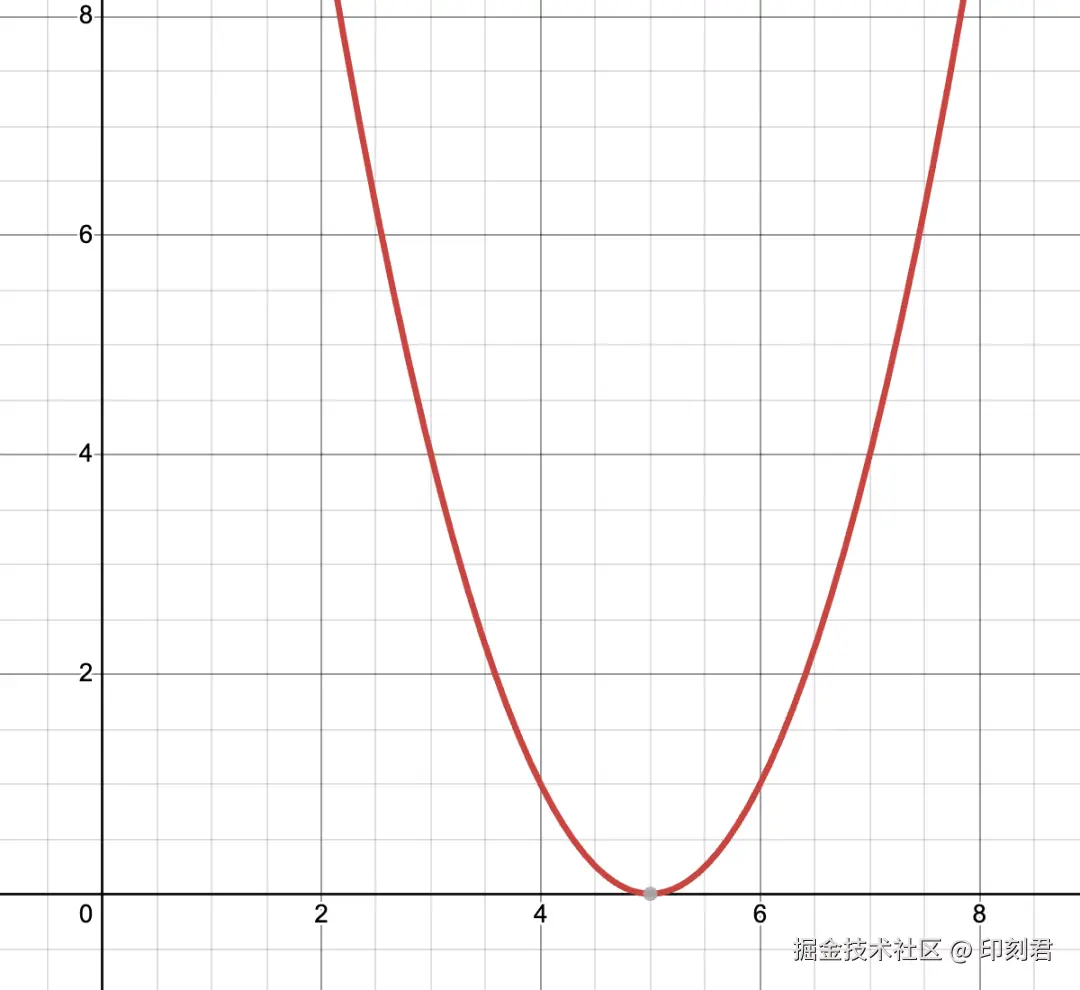
我们想让损失最小, 其实就是让 l(x) 的值最小, 抛物线的最低点就是损失最小的位置.
导数是这个抛物线上的斜率, 在最低点左侧, 斜率为负, 意味着增大 x 可以使损失下降; 在最低点右侧, 斜率为正, 意味着可以减小 x 的值使损失下降. 最低点斜率为 0, 损失最小.
3.2 反向传播
刚才我们是通过看图看出来 x 为 5 时损失最小, 但是计算机不会看图, 它需要一个方法来找到什么时候损失函数最小, 这个方法就是反向传播.
严格来说, 反向传播是在多参数场景下的概念, 这里是它的简化形式.
反向传播的核心口诀是正向算损失, 反向算导数, 迭代更新参数. 口诀说的步骤如下:
-
正向算损失, 先猜一个 x, 比如 x=8, 带入 l(x) 后计算损失为
l(8)=(5−8)2=(−3)2=9
-
反向算导数,对l(x)求x$ 的导数
dxdl=2(5−x)×(−1)=2x−10
代入 x=8 之后得到导数为 6
-
迭代更新参数, 导数为 6 是正数, 我们调整参数的方向要和导数相反, 所以新的 x 需要变小, 新的 x 计算公式为:
x新=x旧−学习率×导数
这里 "学习率" 是用来调整参数幅度, 我们先假设为 0.1, x 就被更新为
8−0.1×6=7.4
-
现在我们循环回到第 1 步, 重新计算
l(7.4)=(5−7.4)2=5.76
可以看到损失显著减少.
如果我们一直重复 "正向 -> 反向 -> 更新" 的流程, 当 x 趋近于 5 的时候, 损失就趋近于 0.
这样通过反向传播, 用导数指导参数调整, 就能够让损失趋近于 0.
4 偏导
猜苹果单价是单参数的情况, 实际 AI 训练要处理多参数问题, 比如打车费预测.
打车总费用一般由两部分组成, 一部分是起步费, 一部分是每公里的单价.
假设我打了 3 公里的车, 总计花了 15 元, 你需要猜打车的起步费和单价, 问题就复杂了.
打车的预测价格为 y^=3w+b, 于是损失函数可以写为:
l(w,b)=(15−(3w+b))2
现在我们需要让损失函数变得最小, 但是有 w 和 b 两个要猜的参数, 怎么样才能猜得更快更准呢?
这时候就需要用到控制变量法, 先假设只有一个变量在变化, 其他变量不变, 这就是求偏导.
在 l(w,b) 的例子里就是:
- 假设 w 不变, 只有 b 在变, 偏导表示为 ∂b∂l
- 假设 b 不变, 只有 w 在变, 偏导表示为 ∂w∂l
通过偏导, AI 能分别确定每个参数的调整方向, 避免多参数相互干扰.
5 梯度
前面说的梯度消失/梯度爆炸里的 "梯度", 就是这里要讲的核心概念. 当有多个参数时, 我们把所有参数的偏导数组合起来, 形成一个向量, 这就是梯度.
以二元函数 z=f(x,y) 为例:
- 它对 x 的偏导数是 ∂x∂f, 意思是固定 y 不变, 函数沿 x 轴方向的变化率;
- 它对 y 的偏导数是 ∂y∂f,意思是固定 x 不变, 函数沿 y 轴方向的变化率.
把所有偏导数组合在一起, 就形成了**梯度. **
∇f(x,y)=(∂x∂f,∂y∂f)
梯度是一个向量, 它的方向, 指向函数值在该点增长最快的方向.
用一个形象的比喻, 多元函数的损失曲面可以比作一座山峰, 梯度的方向就是上山最快的方向, 负梯度的方向就是下山最快的方向.
我们要找损失最小值, 相当于要走到山底, 所以需要沿着 "负梯度方向" 走. 这就是 AI 训练中 "梯度下降法" 的核心逻辑.
6 残差矩阵
前面 1~5 节, 我们都是只猜单样本, 少参数的情况. 实际 AI 训练是需要批量处理数据的, 于是就需要用到矩阵来简化计算.
我们先看残差是如何用矩阵来处理的, 比如我们要预测三种水果的单价:
Y=[534] 是实际值矩阵, 行代表苹果, 香蕉, 橙子的实际单价, 分别为 5 元, 3 元和 4 元;
Y^=[825] 是预测值矩阵, 行代表苹果, 香蕉, 橙子的预测单价, 分别为 8 元, 2 元和 5 元;
残差矩阵公式为 E=Y−Y^, 于是:
E=[−31−1], 代表苹果, 香蕉, 橙子的单价残差, 分别为 -3 元, 1 元和 -1 元.
7 损失矩阵
和之前说到损失一样, 残差矩阵我们也需要一种方法, 让残差矩阵里面只有正数.于是我们会用到矩阵的哈达玛积, 它的运算就是对应元素相乘:
L=E⊙E
把残差矩阵带入后
L
=[−3×−31×1−1×−1]
=[911]
后续计算批量损失时, 只需对这个矩阵取平均值, 就能得到整体损失值.
8 偏导矩阵
在输入/输出均为矩阵的情况下, 我们需要矩阵求导. 核心逻辑与之前一致, 只是把 "单参数的变化率" 推广为 "矩阵元素整体的变化率".
以损失矩阵对参数矩阵求偏导为例:
假设输入矩阵 X 是 3 个样本的特征
X=123
权重矩阵 W=[w], B=[b], 预测矩阵为:
Y^=W⋅X+B=w+b2w+b3w+b
实际矩阵为:
Y=534
于是残差矩阵变为
E=5−(w+b)3−(2w+b)4−(3w+b)
损失矩阵变为
L=(5−(w+b))2(3−(2w+b))2(4−(3w+b))2
总损失(均方误差)为所有样本损失的平均值:
Ltotal=31∑i=13(yi−yi^)2
现在, 我们需要计算总损失对两个参数 w 和 b 的偏导数:
对于 w 的偏导数 (每个样本):
∂w∂L=−2(5−w−b)−4(3−2w−b)−6(4−3w−b)
对于 b 的偏导数 (每个样本):
∂b∂L=−2(5−w−b)−2(3−2w−b)−2(4−3w−b)
注意: 这里每个矩阵表示的是每个样本的损失对参数的偏导数, 而不是总损失的偏导数. 为了得到总损失的偏导数, 我们需要对这些矩阵按列求平均 (因为总损失是每个样本损失的平均值)
总损失对 w 的偏导数为:
∂w∂Ltotal=31∑i=13∂w∂L
总损失对 b 的偏导数为:
∂b∂Ltotal=31∑i=13∂b∂L
于是我们就得到了正确的梯度向量:
∇Ltotal=[∂w∂Ltotal,∂b∂Ltotal]T
模式更新参数时, 就可以按照这个梯度向量进行梯度下降:
- wnew=wold−η⋅∂w∂Ltotal
- bnew=bold−η⋅∂b∂Ltotal
其中 η 是学习率. 通过这种方式, 模型能够同时利用所有样本的信息来调整参数, 使总损失最小化.
总结
本文我们介绍了残差, 损失, 导数, 偏导, 梯度, 残差矩阵, 损失矩阵和偏导矩阵 8 个数学概念.
8 个概念作用可以归纳为:
- 感知误差, 让 AI 知道自己预测得有没有错误, 相关概念有残差, 损失, 残差矩阵和损失矩阵;
- 减少误差, 让 AI 知道自己怎么调整才可以减少误差, 相关概念有导数, 偏导, 梯度和偏导矩阵
下次你再看到 "AI 训练", "模型优化" 这类术语时, 你就不再是看热闹的外行人, 而是能看懂底层逻辑的懂行人啦.
我是印刻君,一位探索 AI 的前端程序员,关注我,让 AI 知识有温度,技术落地有深度.


