

KnowFlow v2.3.2 重磅发布:ColPali 多模态解析引领文档理解新纪元
前言
新年伊始,KnowFlow 团队为大家带来了 v2.3.2 版本的重磅更新。这次更新不仅在技术层面实现了突破性进展,更在产品易用性和企业集成能力上做了全面升级。从原生多模态解析到企业微信智能机器人,从 Dify 知识库集成到 Helm 分布式部署,每一项功能都是我们对企业级知识管理场景的深度思考。
KnowFlow 始终坚持一个理念:将非结构化数据治理成对大模型更可信的输入,构建 AI 时代的数据根基。这次 v2.3.2 版本的发布,正是这一理念在产品层面的又一次落地实践。
一、核心亮点:ColPali 多模态解析
传统方案的痛点
在企业实际应用中,大量关键信息隐藏在图表中——财报里的营收趋势图、研报中的数据对比图、技术文档里的架构图。传统的 OCR 方案只能识别文字,对图表内容"视而不见"。
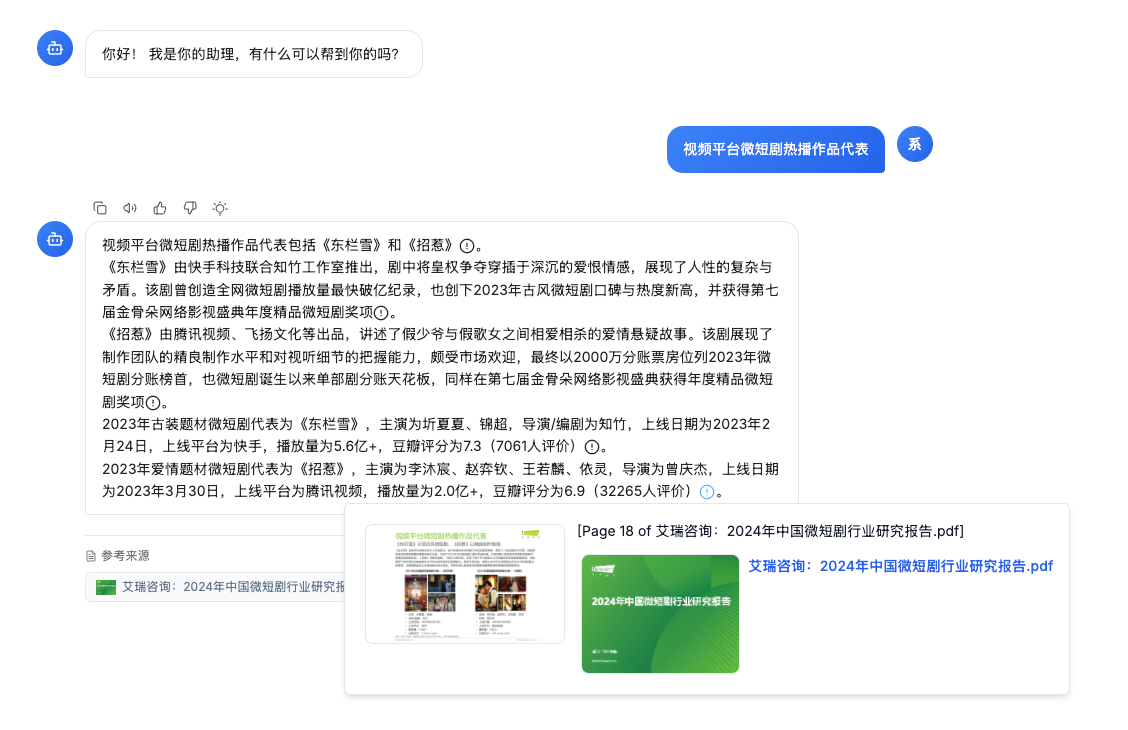
当用户问"2023年第三季度营收增长趋势如何"时,传统方案可能只检索到文字描述"营收同比增长15%",但遗漏了最直观的趋势图。用户还需要手动翻找图表,效率低下。
ColPali:让图表"开口说话"
KnowFlow v2.3.2 引入的 ColPali 技术,从根本上解决了这一问题。ColPali 是一种基于视觉语言模型的文档理解技术,它将文档作为图像整体处理,无需预先 OCR 分离图文。
核心特点:
- 端到端处理:文档作为图像整体输入,保留完整的视觉布局信息
- 多向量表示:每个文档页面生成多个向量(N×320维),每个向量对应文档的一个局部区域
- 细粒度匹配:检索时进行细粒度的语义匹配,精准定位相关内容
KnowFlow 采用的是 TomoroAI/tomoro-colqwen3-embed-4b 模型,这是一个专门针对文档理解优化的多模态模型。
双 Collection 架构:性能提升 48 倍
多向量带来了精度提升,但也带来了性能挑战。一个 100 页的文档可能产生数万个向量,如何高效检索?
KnowFlow 团队基于 Milvus 设计了双 Collection 两阶段检索架构,在保证精度的同时大幅提升性能。
架构设计:
┌─────────────────────────────────────────────────────────┐
│ Milvus 双 Collection 架构 │
├─────────────────────────────────────────────────────────┤
│ │
│ Collection 1: colpali_fde (FDE 向量) │
│ 每个 chunk 一行 → Stage 1 粗排(快速) │
│ - chunk_id: VARCHAR(256) │
│ - kb_id: VARCHAR(256) │
│ - fde_vector: FLOAT_VECTOR(4096) │
│ │
│ Collection 2: colpali_vectors (多向量) │
│ 每个 chunk 多行 → Stage 2 精排(精准) │
│ - chunk_id: VARCHAR(256) │
│ - kb_id: VARCHAR(256) │
│ - vector_idx: INT32 │
│ - vector: FLOAT_VECTOR(320) │
│ │
└─────────────────────────────────────────────────────────┘
MuVERA FDE 算法:
FDE (Fixed Dimensional Encoding) 是 MuVERA 算法的核心,它将变长的多向量转换为固定维度的单向量,用于快速粗排。
转换流程:
输入: 多向量 (N×320维)
↓
SimHash 分区 (2^6 = 64 个分区)
↓
每个分区取 max (重复 10 次提高精度)
↓
Count Sketch 投影 → 4096 维
↓
L2 归一化
↓
输出: FDE 向量 (4096维)
两阶段检索流程:
用户查询: "2023年Q3营收增长趋势"
↓
ColPali API 编码 → FDE向量(4096维) + 多向量(M×320维)
↓
Stage 1: FDE 向量 ANN 搜索 (粗排)
- 输入: FDE 查询向量 (4096维)
- 输出: Top 15 候选 chunk_ids
- 耗时: ~50-100ms
↓
Stage 2: 多向量 MaxSim 搜索 (精排)
- 输入: 查询多向量 (M×320维), 候选 chunk_ids
- 操作: MaxSim(Q, D) = Σᵢ maxⱼ sim(qᵢ, dⱼ)
- 输出: Top 5 精排结果 + MaxSim 分数
- 耗时: ~100-200ms
↓
Elasticsearch 元数据获取
- 输入: chunk_ids
- 输出: doc_id, img_id, page_num, content
- 耗时: ~10-30ms
↓
返回最终结果(图文一体呈现)
性能对比:
| 方案 | P50 延迟 | P99 延迟 | 性能提升 |
|---|---|---|---|
| ES nested | ~12s | ~15s | - |
| Milvus 双 Collection | 250ms | 400ms | 48倍 |
实际应用场景
场景一:财务报表分析
某企业需要从历年财报中分析营收趋势。
- 传统方案:只召回文字描述,遗漏趋势图,准确率 65%
- ColPali 方案:同时召回趋势图和分析文字,图文一体呈现,准确率 92%
场景二:技术文档检索
研发团队需要查找 API 调用示例。
- 传统方案:召回代码片段(纯文本),缺失架构图
- ColPali 方案:召回完整的示例页面(含架构图),保留完整上下文
场景三:产品手册查询
客服需要快速找到产品功能说明。
- 传统方案:召回文字步骤,客服需要口头描述界面,问题解决率 70%
- ColPali 方案:召回操作界面截图 + 步骤说明,客服直接发送截图,问题解决率 95%
快速开始
cd docker
# 启用 ColPali
sed -i 's/ENABLE_COLPALI=false/ENABLE_COLPALI=true/' .env
# 启动服务(自动启动 Milvus + ColPali API)
docker compose up -d
# 验证服务
curl http://localhost:9100/health # ColPali API
curl http://localhost:19530/healthz # Milvus
资源要求:
- GPU:8GB+ 显存(推荐 16GB)
- 内存:16GB+
- 磁盘:50GB+ SSD
二、企业微信智能机器人:知识触手可及
在企业日常办公中,员工往往需要在多个系统之间切换查找信息。KnowFlow v2.3.2 推出的企业微信智能机器人功能,让知识检索真正融入员工的工作流程。
核心能力
- 即问即答:在企业微信群聊或单聊中直接提问,机器人实时返回答案
- 知识库关联:支持绑定多个知识库,智能路由到最相关的知识源
- 权限继承:自动继承 KnowFlow 的 RBAC 权限体系,确保数据安全
- 引用溯源:回答内容自动标注来源文档,支持一键跳转查看原文
- 消息加密:采用企业微信标准的消息加解密机制,保障通信安全
使用场景
| 场景 | 传统方式 | 企业微信机器人 |
|---|---|---|
| 新员工入职 | 翻阅厚厚的员工手册 | 直接在微信问"报销流程是什么" |
| 技术支持 | 搜索文档库找解决方案 | 群里问"XX 错误如何处理" |
| 销售培训 | 查找产品资料 PPT | 问"XX 产品的核心优势" |
| 合规咨询 | 联系法务部门 | 问"XX 合同条款如何解读" |
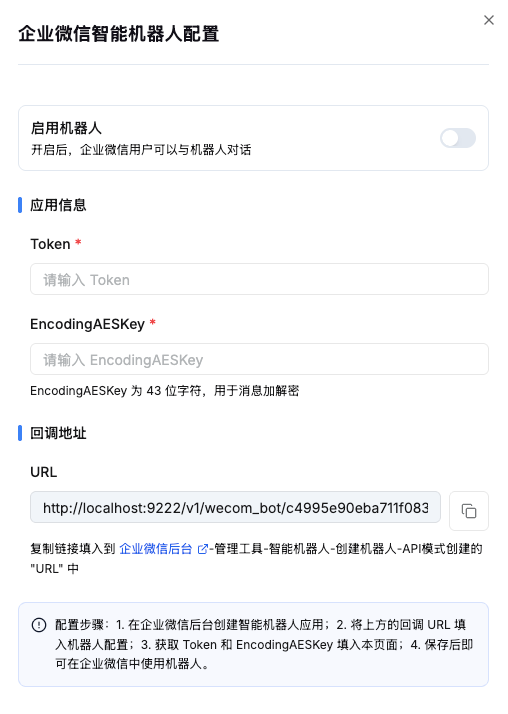
配置步骤
- 在企业微信管理后台创建自建应用
- 获取 AgentID、Secret、Token、EncodingAESKey
- 在 KnowFlow 系统设置中填写企业微信配置
- 选择需要接入的知识库
- 员工在企业微信中添加机器人即可使用
技术实现
企业微信机器人基于标准的企业微信 API 实现,支持:
- 消息接收:接收用户发送的文本、图片、文件等消息
- 消息回复:支持文本、图片、文件、图文混排等多种回复格式
- 消息加解密:实现了企业微信的 AES 加解密算法,确保通信安全
- 事件回调:支持关注、取消关注等事件处理
三、Dify 外部知识库集成:打通 AI 应用生态
Dify 是国内领先的 LLM 应用开发平台,许多企业已经在 Dify 上构建了自己的 AI 应用。KnowFlow v2.3.2 新增了 Dify 外部知识库接入能力,让 KnowFlow 的高精度知识库可以无缝为 Dify 应用提供知识支持。

集成优势
- 标准 API:遵循 Dify Retrieval API 规范,开箱即用
- 知识库引用:在 Dify 应用中直接引用 KnowFlow 知识库
- 高精度检索:利用 KnowFlow 的智能分块和多模态检索能力
- 权限隔离:不同 Dify 应用可以访问不同的知识库
工作流程
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ Dify 应用 │─────►│ KnowFlow │─────►│ 知识库 │
│ (聊天机器人)│ │ Retrieval │ │ (高精度检索)│
│ │◄─────│ API │◄─────│ │
└──────────────┘ └──────────────┘ └──────────────┘
配置方法
- 在 KnowFlow 中创建 API Token
- 在 Dify 应用中添加外部知识库
- 填写 KnowFlow API 地址和 Token
- 选择需要接入的知识库
- 在 Dify 工作流中引用知识库节点
应用案例
- 智能客服:Dify 构建对话流程,KnowFlow 提供产品知识
- 内部助手:Dify 处理意图识别,KnowFlow 检索制度文档
- 代码助手:Dify 生成代码,KnowFlow 提供 API 文档
- 报告生成:Dify 组织内容,KnowFlow 提供数据支撑
四、Helm 分布式部署:拥抱云原生架构
随着企业用户规模的扩大,单机部署已经无法满足高并发、高可用的需求。KnowFlow v2.3.2 正式支持 Helm Chart 分布式部署,让 KnowFlow 真正具备企业级生产环境的部署能力。
Helm 部署优势
- 一键部署:通过 Helm Chart 快速部署到 Kubernetes 集群
- 弹性伸缩:根据负载自动扩缩容,应对流量高峰
- 高可用:多副本部署,单点故障自动切换
- 资源隔离:通过 Namespace 实现多租户隔离
- 版本管理:支持灰度发布、快速回滚
五、体验优化
1. 图文混排格式优化
在之前的版本中,部分用户反馈图文混排的文档在解析后格式会出现错乱。v2.3.2 对图文混排的排版逻辑进行了全面优化:
- 图片位置保留:图片在原文档中的位置关系得到保留
- 文字环绕:支持文字环绕图片的排版效果
- 标题关联:图片自动关联到所属章节标题
- 图注识别:自动识别图片下方的图注文字
2. TEI 部署 Embedding 模型
新增对 Text Embeddings Inference (TEI) 的支持,这是 Hugging Face 推出的高性能 Embedding 推理服务:
- 性能提升:相比传统部署方式,推理速度提升 2-3 倍
- 资源优化:更低的显存占用,支持更大的 Batch Size
- 易于部署:Docker 一键启动,无需复杂配置
该功能可以明显提升并发下检索速度,50 并发 TEI vs BGE-M3 对比(多次测试平均值):
| 指标 | TEI | BGE-M3 | 差异 | TEI 优势 |
|---|---|---|---|---|
| TTFT 平均值 | 32.566s | 48.519s | -15.95s | 1.49x 更快 |
| TTFT P95 | 32.798s | 48.884s | -16.09s | 1.49x 更快 |
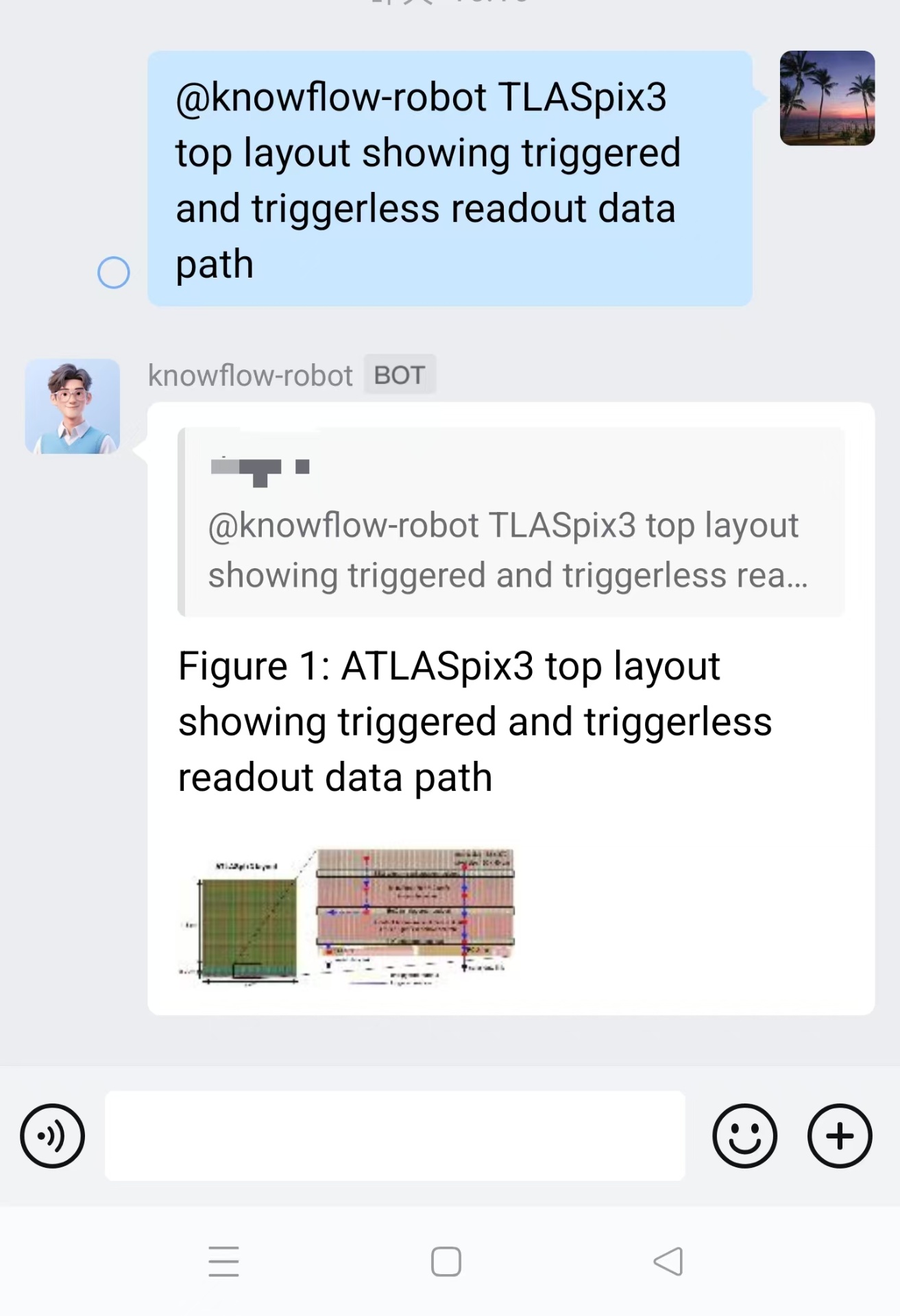
3. PDF 引用跳转高亮
在对话界面中,当回答引用了 PDF 文档时,现在可以直接点击引用跳转到文档预览页面,并高亮显示引用的具体段落:
- 精准定位:自动滚动到引用段落位置
- 高亮标注:引用内容以黄色背景高亮显示
- 上下文查看:可以查看引用段落的前后文
- 多引用支持:一次回答引用多处时,支持逐个跳转
这个功能对于需要核查信息来源的场景特别有用,比如法律咨询、医疗问答、学术研究等。
六、缺陷修复
1. 时区问题修复
问题描述:部分用户反馈修改密码后仍然无法登录,同时系统时间显示与本地时间不一致。
根本原因:
- 在 RBAC 初始化时,创建管理员用户时未设置
timezone字段,导致该字段为 NULL - 前端在读取用户信息时,
timezone为 NULL 导致时区选择器异常 - 修改密码时,由于时区字段异常,导致密码更新失败
修复方案:
- 在创建管理员用户时,添加
timezone字段,默认值为'UTC+8\tAsia/Shanghai' - 在创建普通用户时,统一使用
'UTC+8\tAsia/Shanghai'格式(使用\t分隔符) - 前端在读取用户信息时,如果
timezone为空,使用默认值'UTC+8\tAsia/Shanghai' - 修复时区选择器的事件绑定问题(
onValueChange→onChange)
2. 知识图谱生成异常
问题描述:知识图谱生成过程中出现异常,导致生成失败。
根本原因:
- 知识图谱提取和搜索模块使用了同步的
llm.chat()方法 - 在异步框架(asyncio)环境下,同步调用会导致事件循环阻塞
- 当多个知识图谱任务并发执行时,会出现死锁或超时
修复方案:
- 将
llm.chat()替换为asyncio.run(llm.async_chat()) - 在
graphrag/general/extractor.py中添加break语句,避免重试逻辑异常 - 在
graphrag/search.py中导入asyncio模块,确保异步调用正常
3. 权限授予解析问题
问题描述:管理员 A 创建知识库,授予用户 B 编辑权限后,B 无法正常进行文档解析。
根本原因:
- 在文档解析接口中,权限检查逻辑在异步线程外执行
current_user是线程本地变量,在asyncio.to_thread中不可用- 导致权限检查失败,即使用户有正确的权限也无法解析
修复方案:
- 将权限检查逻辑移到异步线程内部(
_run_sync()函数内) - 在主线程中获取
user_id,传递给异步线程 - 在异步线程中使用
check_rbac_permission()进行权限检查
4. 安全漏洞修复
问题描述:安全软件扫描发现 5 个 CVE 漏洞。
修复方案:升级依赖包版本,修复以下 CVE 漏洞。
5. MinerU 配置热更新
问题描述:修改 MinerU 配置后,需要重启容器才能生效。
根本原因(Commit: 2c187de49):
- MinerU 适配器使用了全局缓存
_tenant_adapters和_global_adapter - 配置修改后,缓存未失效,仍然使用旧配置
- 导致用户修改配置后,需要重启容器才能生效
修复方案:
- 禁用 MinerU 适配器的全局缓存
- 每次调用时从数据库或环境变量重新读取配置
- 确保配置变更后立即生效
七、未来规划
v2.3.2 是 KnowFlow 在企业级能力建设上的重要里程碑。接下来,我们将继续围绕"数据治理"这一核心定位,推进以下方向的工作:
近期规划
新增引入 Milvus 向量库,作为 KnowFlow 默认库。
技术优化
1. 多并发性能优化
- 异步任务队列优化
- 数据库连接池调优
- 缓存策略优化
- 负载均衡优化
八、开源与商业
KnowFlow 社区版已同步更新至 v2.1.2,包含 RBAC 权限管理、Markdown 解析等核心功能。
v2.3.2 为商业版本专有,包含多模态解析、企业微信接入、Dify 集成、Helm 部署等高级功能。如有商务需求,欢迎关注公众号 KnowFlow 企业知识库 进行咨询或体验。
九、学习资源
- 官方文档:www.knowflowchat.cn/
- 视频教程:B 站搜索 KnowFlow 企业知识库
- 技术交流:关注公众号 KnowFlow 企业知识库 加入交流群
- GitHub:github.com/weizxfree/K…
结语
KnowFlow v2.3.2 的发布,标志着我们在企业级知识管理领域又迈出了坚实的一步。从 ColPali 多模态解析到企业微信集成,从 Dify 生态对接到云原生部署,每一项功能都是我们对企业真实需求的回应。
我们相信,在 AI 时代,数据治理将成为企业的核心竞争力。KnowFlow 将持续深耕这一领域,为企业提供更可信、更智能、更易用的知识管理解决方案。
感谢每一位用户的信任与支持,让我们一起,用技术的力量重塑知识管理的未来!
KnowFlow v2.3.2 现已发布,立即体验 ColPali 多模态解析和企业微信接入的强大能力!
关注公众号 KnowFlow 企业知识库,获取最新产品动态和技术干货。
