

本文价值提示:
💡 阅读时长:约 10 分钟 🛠️ 实战环境:Python 3.10 + Milvus 2.3 + LangChain + BGE-Reranker 🚀 核心目标:拒绝纸上谈兵。本文将提供可运行的代码片段、真实的踩坑经验和参数调优指南,带你跑通一个高精度的 RAG 闭环。 👨💻 前置知识:建议先阅读本系列前两篇《Python 高级工程化》与《RAG 架构设计》。
👋 大家好,我是你们的老朋友。
上一篇我们聊了 RAG 的架构设计(Milvus + ES 混合检索),后台很多同学直呼“干货满满,但手痒想写代码”。
确实,架构图画得再漂亮,代码跑不通也是白搭。
今天,我们不谈虚的。我将以一个真实的 “企业级技术文档问答系统” 为例,带你从零开始,写出能够部署在生产环境的 RAG 代码。
我们将重点解决三个在 Demo 中遇不到,但一上线就会炸的 “实战天坑”:
- 切片坑:代码块被切断,大模型看不懂。
- 索引坑:数据量大了,查询慢得像蜗牛。
- 精度坑:搜出来的全是相关但无用的废话。
🛠️ 环境准备:工欲善其事
首先,我们需要搭建基础设施。这里我们跳过 Docker 安装步骤,假设你已经启动了 Milvus Standalone 或 Cluster。
核心技术栈:
- 向量库:Milvus (高性能,生产级)
- Embedding:
BAAI/bge-m3(目前中文开源最强,支持多语言) - Rerank:
BAAI/bge-reranker-large(精排神器) - Orchestration:LangChain (胶水层)
pip install pymilvus langchain sentence-transformers torch
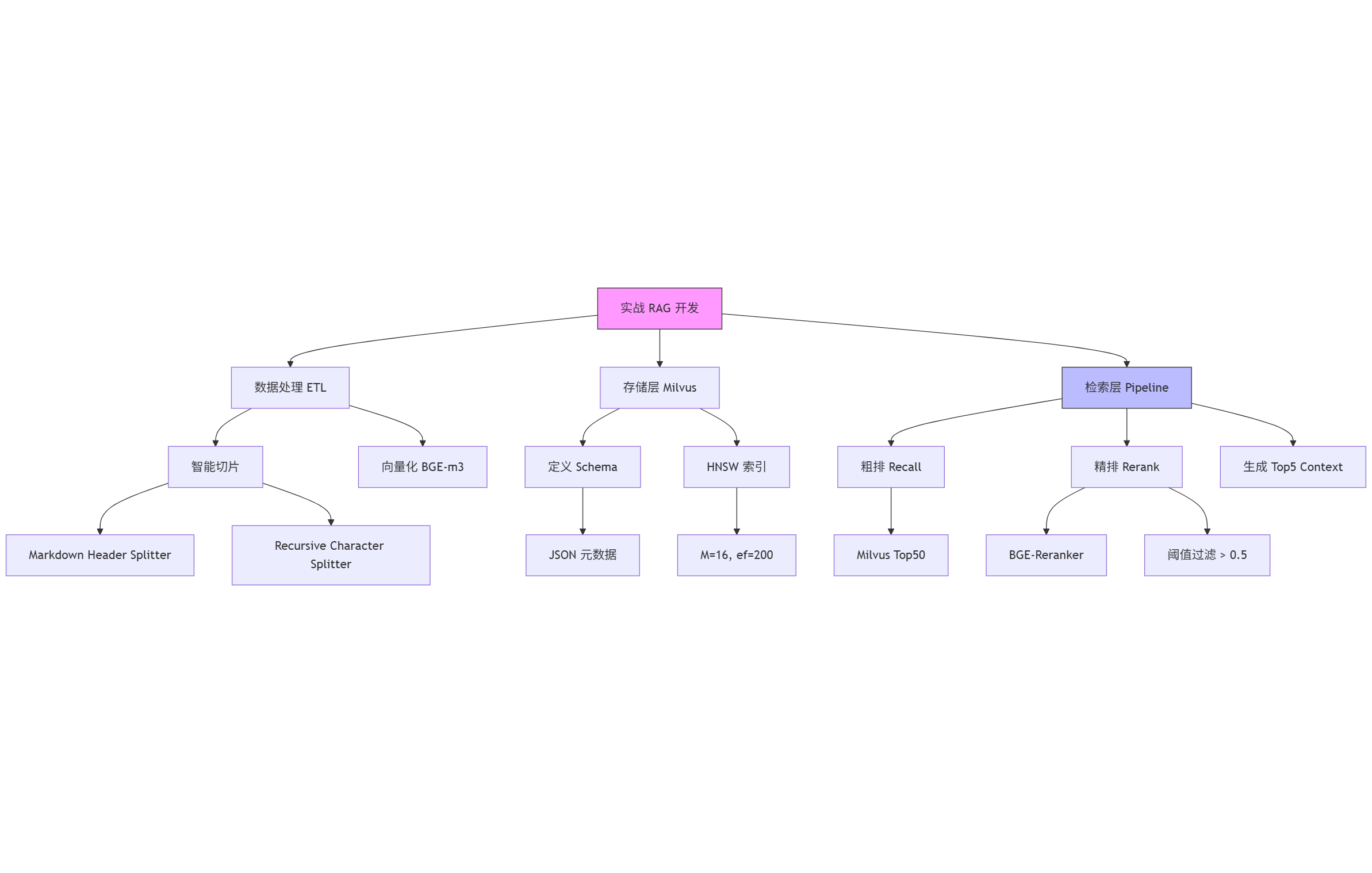
⛏️ 第一关:智能切片 (Chunking) —— 别把代码切碎了!
场景痛点:
技术文档里充满了 Python/Java 代码块。如果你用简单的 FixedSizeSplitter(按字符数切分),很容易出现这种情况:
- 上一块:
def calculate_tax(income): - 下一块:
return income * 0.2
大模型拿到这种残缺片段,根本没法理解逻辑。
实战代码方案: 我们需要使用 “结构化切分”。针对 Markdown 文档,LangChain 提供了基于 Header 的切分器,能保证章节和代码块的完整性。
from langchain.text_splitter import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
def smart_chunking(markdown_text):
# 1. 先按章节标题切分,保留逻辑结构
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_text)
# 2. 章节内如果还太长,再按字符递归切分,但尽量不切断代码块
# separators 参数是关键!优先按代码块结束符 ``` 切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=50,
separators=["\n```\n", "\n\n", "\n", " ", ""]
)
final_chunks = text_splitter.split_documents(md_header_splits)
# 3. 关键一步:注入元数据(Metadata)
# 这一步在生产环境至关重要,为了后续的混合检索
for chunk in final_chunks:
chunk.metadata["source"] = "api_docs_v1.md"
chunk.metadata["category"] = "backend"
return final_chunks
# 经验之谈:
# chunk_size 设为 512 左右通常比 1024 效果好。
# 粒度越细,语义越聚焦,Rerank 的效果越明显。
💾 第二关:Milvus 建模与索引调优 —— 速度与精度的平衡
场景痛点:
很多教程直接用 LangChain 的 Milvus.from_documents 一键入库。这在 Demo 里没问题,但在生产环境,你无法控制索引参数,也无法自定义 Schema(比如增加 user_id 字段做权限隔离)。
实战代码方案:
我们要使用 pymilvus 原生 API 建表,这样才能掌控一切。
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
# 1. 连接 Milvus
connections.connect("default", host="localhost", port="19530")
# 2. 定义 Schema (一定要包含元数据字段!)
fields = [
FieldSchema(name="pk", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=65535), # 存原始文本
FieldSchema(name="metadata", dtype=DataType.JSON), # 存 JSON 元数据
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=1024) # BGE-m3 维度是 1024
]
schema = CollectionSchema(fields, "Knowledge Base Collection")
collection = Collection("enterprise_kb", schema)
# 3. 创建索引 (HNSW - 生产环境标配)
# M: 节点最大连接数。越大精度越高,内存消耗越大。推荐 16-64。
# efConstruction: 构建索引时的搜索深度。越大构建越慢,但索引质量越高。推荐 200-500。
index_params = {
"metric_type": "IP", # 内积,适合归一化后的 Cosine 相似度
"index_type": "HNSW",
"params": {"M": 16, "efConstruction": 200}
}
collection.create_index(field_name="vector", index_params=index_params)
collection.load() # 别忘了 Load!否则查不到数据
print("Milvus Collection Ready!")
🔍 第三关:混合检索与重排序 (Rerank) —— 寻找“黄金 Top5”
这是整个系统的灵魂。
如果只用向量检索(ANN),你搜“Python 报错”,它可能给你返回“Java 异常”,因为它们在语义空间里很近。 我们需要引入 BGE-Reranker 进行精排。
流程逻辑:
- 粗排 (Recall):从 Milvus 快速捞出 Top 50(速度快,精度一般)。
- 精排 (Rerank):用 Cross-Encoder 模型逐一给这 50 条打分(速度慢,精度极高)。
- 截断:取分数最高的 Top 5 给大模型。
实战代码方案:
from sentence_transformers import CrossEncoder
import numpy as np
# 初始化模型 (建议预加载到 GPU)
# Embedding 模型用于向量化 Query
# Reranker 模型用于精排
reranker = CrossEncoder('BAAI/bge-reranker-large', device='cuda')
def search_pipeline(user_query, collection, top_k_recall=50, top_k_final=5):
# 1. 向量化 Query (假设已有 embedding_model)
query_vector = embedding_model.encode([user_query])[0]
# 2. Milvus 粗排 (ANN Search)
# search_params 中的 ef 决定查询时的精度,建议设为 top_k_recall 的 2-3 倍
search_params = {"metric_type": "IP", "params": {"ef": 100}}
results = collection.search(
data=[query_vector],
anns_field="vector",
param=search_params,
limit=top_k_recall,
output_fields=["content", "metadata"] # 必须把文本取回来做 Rerank
)
# 3. 准备 Rerank 数据对
# 格式:[[query, doc1], [query, doc2], ...]
candidates = []
doc_list = []
for hit in results[0]:
doc_content = hit.entity.get("content")
candidates.append([user_query, doc_content])
doc_list.append(hit) # 保存原始 hit 对象以便后续使用
# 4. 执行 Rerank (打分)
if not candidates:
return []
scores = reranker.predict(candidates)
# 5. 排序并截断
# argsort 返回的是从小到大的索引,所以要 [::-1] 反转
sorted_indices = np.argsort(scores)[::-1]
final_results = []
for idx in sorted_indices[:top_k_final]:
# 过滤掉分数太低的结果 (阈值控制)
if scores[idx] < 0.5:
continue
final_results.append({
"content": doc_list[idx].entity.get("content"),
"score": float(scores[idx]),
"metadata": doc_list[idx].entity.get("metadata")
})
return final_results
# 模拟调用
# result = search_pipeline("如何配置 Milvus 的内存限制?", collection)
# print(result)
📊 架构师的“避坑指南”
在实际工程落地中,除了代码,还有这些细节决定成败:
1. 内存与显存的博弈
- Milvus:主要吃内存。1000 万条 768 维向量,HNSW 索引大约占用 15GB 内存。如果内存不足,Milvus 会频繁 Swap,性能暴跌。
- Reranker:主要吃显存。
bge-reranker-large跑在显存里。如果并发高,建议部署多个 Reranker Worker,或者使用量化版本(Quantization)。
2. 写入的一致性 (Consistency Level)
Milvus 默认是 Bounded(有界一致性),这意味着你刚插入的数据,可能要过几秒才能查到。
- 调试阶段:建议设为
Strong,写完立刻能查,方便 Debug。 - 生产阶段:保持
Bounded或Session,性能最好。
3. 为什么我的 Rerank 很慢?
检查你的 top_k_recall。
- 如果粗排拉回 1000 条做 Rerank,CPU/GPU 肯定算不过来。
- 黄金比例:粗排 50-100 条,精排取 3-5 条。Rerank 的耗时应控制在 200ms 以内。
📝 总结
今天我们通过代码实战,完成了一个 RAG 系统的核心链路:
- 结构化切片:用
MarkdownHeaderTextSplitter保护代码块语义。 - 原生 Milvus 建模:掌控 Schema 和 HNSW 索引参数。
- 两阶段检索:利用 Milvus (召回) + BGE (精排) 达成“快”与“准”的统一。
这套代码架构,足以支撑千万级数据量的企业知识库。作为从大数据转型而来的架构师,你应该能感受到:AI 应用的本质,依然是数据流的处理与优化。
🧠 本文思维导图
专题收官:RAG 架构与数据工程 —— 当大模型遇上大数据
回顾这五个阶段的旅程,我们完成了一次从 “大模型应用者” 到 “AI 架构师” 的思维跃迁。如果说前两个专题(Python 工程化、大模型理论)是练就了“内功”和“招式”,那么本专题则是教会了我们如何打造一把趁手的“兵器”。
我们共同经历了五个里程碑:
- 认知重塑:理解了 RAG(检索增强生成)不仅是技术的组合,更是解决大模型“幻觉”与“知识滞后”的必经之路。
- 数据为王:深入数据工程的腹地,明白了“Garbage In, Garbage Out”的铁律。从非结构化文档的清洗,到精细化的切片(Chunking)策略,我们学会了如何将企业私有数据转化为 AI 可理解的“营养”。
- 向量奥义:掌握了 Embedding 的魔法,将人类的语言转化为高维空间的向量,理解了语义检索的数学本质。
- 存储基石:从简单的内存索引走向了分布式的向量数据库,探讨了 Milvus、Pinecone 等选型背后的架构考量。
- 架构进阶:在最终阶段,我们打破了单一检索的局限,构建了 “混合检索 + 重排序(Rerank)” 的企业级架构,解决了生产环境中“查不准、慢吞吞”的顽疾。
核心启示: 本专题最大的收获在于认清了一个事实:RAG 的上限,不取决于大模型的智商,而取决于数据工程的质量。 一个优秀的 RAG 系统,本质上是一个高效的 ETL 流水线加上精准的搜索引擎。
展望未来: 现在,我们已经拥有了一个博学且严谨的“大脑”(LLM)和一个海量且精准的“图书馆”(RAG)。但它们目前还是被动的。
在接下来的旅程中,我们将赋予这个系统“手”和“脚”,让它学会使用工具、规划任务、自我迭代。
下一站,我们将正式开启:AI Agent(智能体)与应用编排。 敬请期待!
💬 互动话题
在实战代码中,你觉得最难处理的数据类型是什么? A. 包含大量表格的 PDF B. 扫描版的图片文档 (OCR) C. 混合了中英文和代码的技术文档 D. 格式混乱的 Word 文档
点赞 + 在看,并在评论区留下你的答案(或者你的报错日志😂)。下一期,我们将探讨 AI Agent,看看如何让大模型自己去查数据库、调 API!
