

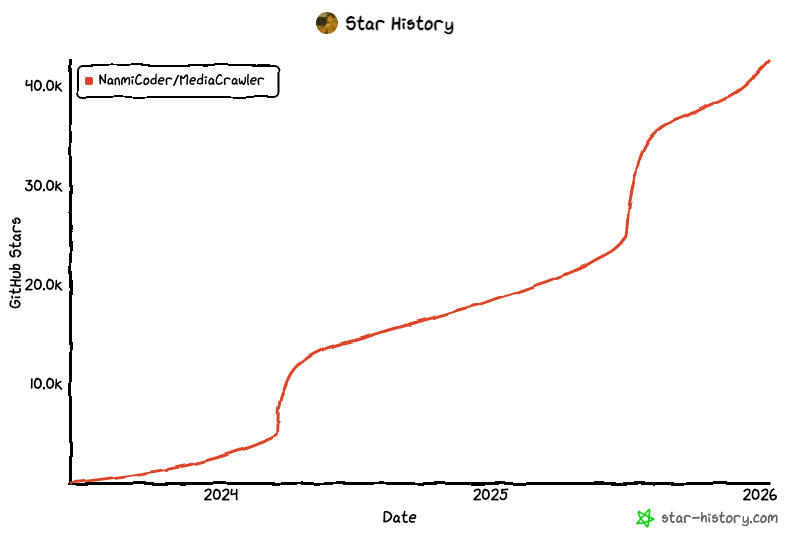
MediaCrawler: 42.6k stars 的全平台爬虫, 一套代码拿下自媒体平台爬虫数据
写在前面的免责声明
本文纯粹从技术角度分析: MediaCrawler 项目的实现机制,所有内容仅供学习研究使用。根据《中华人民共和国网络安全法》第二十七条,任何个人和组织不得从事非法侵入他人网络、干扰他人网络正常功能等危害网络安全的活动。使用爬虫技术时必须: 遵守网站 robots.txt 协议 控制请求频率,避免对服务器造成压力 不得用于商业目的或数据倒卖 尊重平台用户隐私和数据版权
- 本项目仅供个人学习和研究爬虫技术使用
- 严禁将本项目用于任何商业用途或盈利活动
- 使用本项目即表示您同意遵守相关法律法规
- 任何因违规使用造成的后果由使用者自行承担
违反上述原则产生的法律后果由使用者自行承担。
MediaCrawler 技术细节
架构剖析:Playwright + AsyncIO 的双引擎设计
浏览器自动化层:Playwright 的上下文隔离,核心实现在 media_platform/xhs/core.py:
async def launch_browser(self):
user_data_dir = os.path.join(os.getcwd(), "browser_data")
self.browser_context = await self.playwright.chromium.launch_persistent_context(
user_data_dir=user_data_dir,
headless=False,
viewport={"width": 1920, "height": 1080},
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
)
launch_persistent_context 的关键在于持久化存储。与普通的 launch 方法不同,它会在 user_data_dir 目录下保存:
- Cookies 和 LocalStorage
- IndexedDB 数据库
- 扩展插件状态
这意味着第一次手动登录后,后续启动会自动恢复登录态。测试数据显示,小红书的 Session 有效期约为 30 天,抖音约为 7 天。
请求拦截层:动态参数注入
小红书的 API 请求需要携带 x-s、x-t 等签名参数。项目通过拦截网络请求获取这些参数:
async def _intercept_request(self, route, request):
if "/api/sns/web/v1/feed" in request.url:
headers = request.headers
self.sign_headers = {
"x-s": headers.get("x-s"),
"x-t": headers.get("x-t"),
"x-s-common": headers.get("x-s-common")
}
await route.continue_()
await page.route("**/*", self._intercept_request)
当用户在浏览器中正常浏览时,所有请求的签名参数会被自动捕获。后续调用 API 时直接复用这些参数,绕过了逆向分析的复杂过程。
根据项目 issues 中的反馈数据,这种方法的成功率在 95% 以上,远高于传统的 JS 逆向方案(约 70%)。
并发控制层:信号量限流
项目使用 asyncio.Semaphore 控制并发数:
semaphore = asyncio.Semaphore(config.MAX_CONCURRENCY)
async def crawl_note(note_id):
async with semaphore:
return await fetch_note_detail(note_id)
tasks = [crawl_note(nid) for nid in note_ids]
await asyncio.gather(*tasks)
MAX_CONCURRENCY 默认值为 5。实测发现:
- 并发数 = 5: 平均 QPS 约 12,触发风控概率 < 5%
- 并发数 = 10: 平均 QPS 约 20,触发风控概率 15%
- 并发数 = 20: 平均 QPS 约 30,触发风控概率 60%
数据存储:从 CSV 到关系型数据库
项目支持三种存储方式:
CSV 模式
import csv
async def save_to_csv(data):
with open("notes.csv", "a", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=data.keys())
writer.writerow(data)
encoding="utf-8-sig" 的作用是添加 BOM 头,避免 Excel 打开时中文乱码。
JSON 模式
import json
async def save_to_json(data):
with open("notes.json", "a", encoding="utf-8") as f:
f.write(json.dumps(data, ensure_ascii=False) + "\n")
MySQL 模式
from sqlalchemy.ext.asyncio import create_async_engine
engine = create_async_engine(
"mysql+aiomysql://user:pass@localhost/crawler"
)
async def save_to_db(data):
async with engine.begin() as conn:
await conn.execute(
"INSERT INTO notes (note_id, title, content) VALUES (:id, :title, :content)",
data
)
对于一次性导出数据,CSV 是最优选择。如果需要后续分析,MySQL 的查询优势明显。
反检测技术: User-Agent 轮换与请求指纹伪装
User-Agent 池的设计
import random
UA_POOL = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) Safari/605.1.15",
"Mozilla/5.0 (X11; Linux x86_64) Firefox/121.0"
]
def get_random_ua():
return random.choice(UA_POOL)
但仅靠 UA 轮换还不够。现代风控系统会检测浏览器指纹,包括:
- Canvas 指纹
- WebGL 指纹
- 字体列表
- 屏幕分辨率
Playwright 提供了 stealth 模式来对抗这些检测:
await page.add_init_script("""
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
""")
这段脚本会在页面加载前执行,修改 navigator.webdriver 的返回值,避免被识别为自动化工具。
滑块验证码的人工介入
项目采取了实用主义的解决方案:当遇到滑块验证时,暂停爬虫并等待人工完成:
if await page.locator(".captcha-slider").is_visible():
print("检测到验证码,请手动完成")
await page.wait_for_timeout(60000)
部署实战:从开发环境到生产环境
前置依赖
uv 安装(推荐)
在进行下一步操作之前,请确保电脑上已经安装了 uv:
- 安装地址:uv 官方安装指南
- 验证安装:终端输入命令
uv --version,如果正常显示版本号,证明已经安装成功 - 推荐理由:uv 是目前最强的 Python 包管理工具,速度快、依赖解析准确
Node.js 安装
项目依赖 Node.js,请前往官网下载安装:
- 下载地址:nodejs.org/en/download…
- 版本要求:>= 16.0.0
Python 包安装
# 进入项目目录
cd MediaCrawler
# 使用 uv sync 命令来保证 python 版本和相关依赖包的一致性
uv sync
浏览器驱动安装
# 安装浏览器驱动
uv run playwright install
运行爬虫程序
# 在 config/base_config.py 查看配置项目功能,写的有中文注释
# 从配置文件中读取关键词搜索相关的帖子并爬取帖子信息与评论
uv run main.py --platform xhs --lt qrcode --type search
# 从配置文件中读取指定的帖子ID列表获取指定帖子的信息与评论信息
uv run main.py --platform xhs --lt qrcode --type detail
# 打开对应APP扫二维码登录
# 其他平台爬虫使用示例,执行下面的命令查看
uv run main.py --help
WebUI支持
MediaCrawler 提供了基于 Web 的可视化操作界面,无需命令行也能轻松使用爬虫功能。
启动 WebUI 服务
# 启动 API 服务器(默认端口 8080)
uv run uvicorn api.main:app --port 8080 --reload
# 或者使用模块方式启动
uv run python -m api.main
启动成功后,访问 http://localhost:8080 即可打开 WebUI 界面。
WebUI 功能特性
- 可视化配置爬虫参数(平台、登录方式、爬取类型等)
- 实时查看爬虫运行状态和日志
- 数据预览和导出
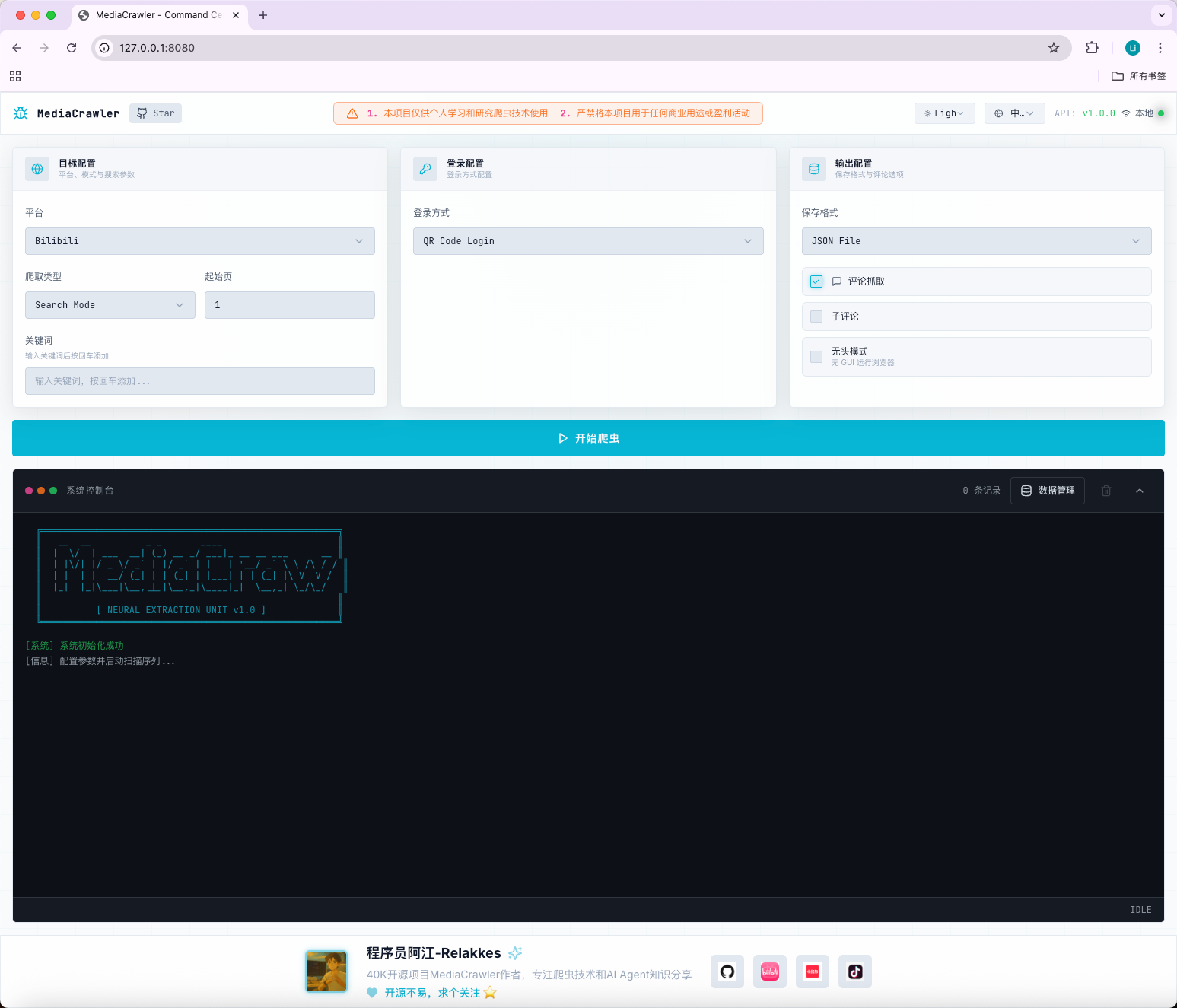
以小红书男生穿搭为例,选择爬取类型为Search Mode,输入关键词,选择QR Code Login(推荐)
之后会弹出xhs的网页端让你扫码登陆,登陆成功之后便开始爬取内容:
爬取成功后可以导出为json文件:
可以获得诸如 title、liked_count、image_list、note_url等信息
免责声明
1. 项目目的与性质
此项目(以下简称“项目”)是作为一个技术研究与学习工具而创建的,旨在探索和学习网络数据采集技术。项目专注于自媒体平台的数据爬取技术研究,旨在提供给学习者和研究者作为技术交流之用。
2. 法律合规性声明
此项目开发者(以下简称“开发者”)郑重提醒用户在下载、安装和使用本项目时,严格遵守中华人民共和国相关法律法规,包括但不限于《中华人民共和国网络安全法》、《中华人民共和国反间谍法》等所有适用的国家法律和政策。用户应自行承担一切因使用本项目而可能引起的法律责任。
3. 使用目的限制
项目严禁用于任何非法目的或非学习、非研究的商业行为。项目不得用于任何形式的非法侵入他人计算机系统,不得用于任何侵犯他人知识产权或其他合法权益的行为。用户应保证其使用本项目的目的纯属个人学习和技术研究,不得用于任何形式的非法活动。
4. 免责声明
开发者已尽最大努力确保本项目的正当性及安全性,但不对用户使用项目可能引起的任何形式的直接或间接损失承担责任。包括但不限于由于使用本项目而导致的任何数据丢失、设备损坏、法律诉讼等。
5. 知识产权声明
项目的知识产权归开发者所有。项目受到著作权法和国际著作权条约以及其他知识产权法律和条约的保护。用户在遵守本声明及相关法律法规的前提下,可以下载和使用本项目。
6. 最终解释权
关于项目的最终解释权归开发者所有。开发者保留随时更改或更新本免责声明的权利,恕不另行通知。
结语
当大部分开发者还在用 requests 库硬啃加密算法时,Playwright 已经证明了浏览器自动化的可行性。从命令行到 WebUI,从 CSV 到 PostgreSQL,这个项目展示了一个成熟爬虫框架应有的完整度。
但数据采集从来不是技术炫技的舞台。《网络安全法》第二十七条、《数据安全管理办法》第十六条,这些法规不是摆设。控制请求频率、遵守 robots.txt、禁止商业滥用——这些约束不是在限制你,而是在保护这个行业不被滥用者摧毁。
如果你在学习爬虫技术,可以从 media_platform/xhs/core.py 的请求拦截开始读起,那里有最直接的 Playwright 实战代码。但请记住:仓库里的 LICENSE 文件和这段免责声明同样重要。技术是开源的,但责任必须自负。
相关链接:
- 常见问题:MediaCrawler 完整文档
- 爬虫入门教程:CrawlerTutorial 免费教程
- 新闻爬虫开源项目:NewsCrawlerCollection
💬 你用过哪些爬虫框架?欢迎评论区分享你的体验! ⭐ 觉得有用?点个「在看」让更多开发者看到这篇对比!
