

💎 本文价值提示
很多从大数据转型 AI 的工程师会发现:明明跑通了 RAG 的 Demo,但在生产环境中,用户问“2023年的财报数据”,系统却吐出了2021年的内容;用户搜具体的“报错代码 503”,系统却在讲“服务器维护的一般流程”。
这是因为你过度迷信“向量语义”,而丢掉了“精确匹配”的传统手艺。
本文将带你深入 RAG 的数据工程深水区,掌握混合检索 (Hybrid Search) 与 智能切片 (Smart Chunking) 两大核心杀器。这是从“玩具 Demo”跨越到“企业级交付”的关键一步。
👋 前言:从“存得下”到“查得准”
欢迎回到我们的 《大数据转型 AI 架构师》 系列专题。
在之前的两篇文章中,我们攻克了 Python 高级工程化(打造坚实的骨架)和 大模型基础理论(理解大脑的运作)。今天,我们来到了第三个专题的核心腹地——向量数据库。
如果你已经按照我们之前的计划,学会了用 Milvus 或 ES 存下海量向量,解决了“存不下”和“查得慢”的问题(Phase 2 & 3),那么恭喜你,你已经完成了一半。
但作为架构师,你马上会面临业务方的灵魂拷问:
- “为什么我搜产品型号
X-200,它给我推荐X-100?它们向量距离是很近,但这是两个产品啊!” - “为什么我问合同里的违约金比例,它把整页废话都给我了,关键数字却没提取出来?”
这时候,单纯的 Vector Search 已经不够用了。我们需要引入大数据工程师最擅长的武器——精细化数据工程。
⚔️ 第一战场:混合检索 (Hybrid Search) —— 左右互搏的艺术
在大数据领域,我们习惯了 SQL 的 WHERE id = 1001,这是精确匹配。
在 AI 领域,Embedding 带来的是模糊语义匹配。
痛点:向量检索(Dense Retrieval)擅长理解“概念”(比如“好用的手机”),但在处理专有名词、精确数字、代码片段、缩写时,表现往往不如传统的关键词检索。
解决方案:混合检索 = 向量检索 (语义) + 关键词检索 (精确)。
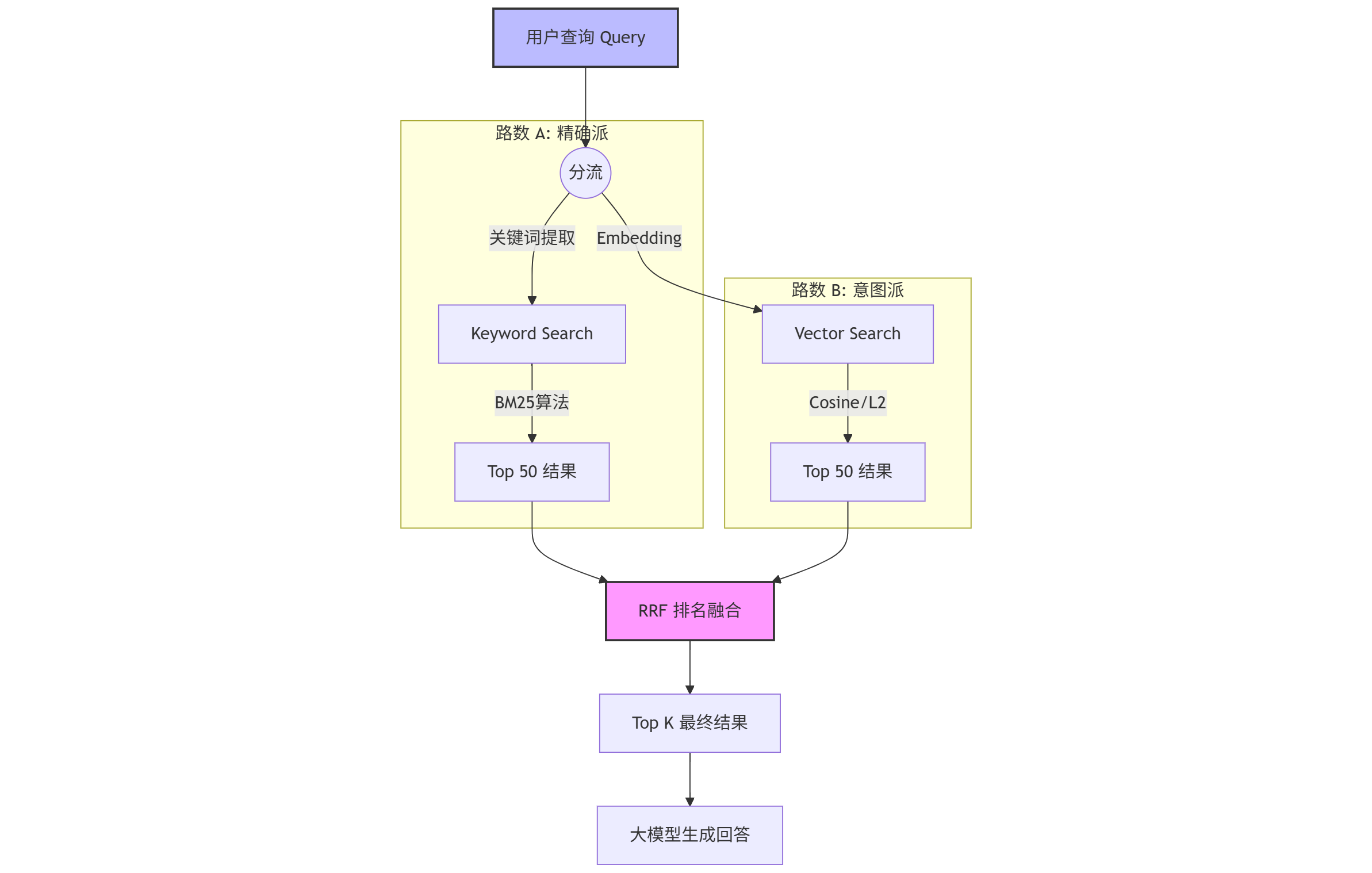
1. 架构设计:双路召回
我们需要构建一个“双引擎”检索系统:
- 路数 A:BM25 (关键词检索)
- 老朋友:这就是 Elasticsearch 的看家本领。基于 TF-IDF 的改进版。
- 作用:死磕“字面意思”。用户搜“报错 503”,它就只找包含“503”的文档,绝不给你找“404”。
- 路数 B:Vector Search (语义检索)
- 新贵:基于 Embedding 模型(如 OpenAI, BGE)。
- 作用:理解“弦外之音”。用户搜“服务器崩了”,哪怕文档里没这几个字,它也能找到“服务不可用”、“宕机”等相关内容。
2. 融合策略:RRF (Reciprocal Rank Fusion)
两路人马找回来的结果,一个是按“相似度分数”排,一个是按“关键词匹配分”排,怎么合并?直接相加?不行,量纲不一样。
这里我们需要用到 RRF (倒数排名融合) 算法。
💡 通俗理解 RRF: 想象一场比赛,BM25 是裁判 A,Vector 是裁判 B。 选手甲在 A 那里排第 1,在 B 那里排第 10。 选手乙在 A 那里排第 3,在 B 那里排第 2。 RRF 不看具体分数,只看排名。谁的综合排名更靠前,谁就赢。
RRF 公式简化版:
👇 混合检索流程图 :
🏭 第二战场:RAG 数据 ETL 流水线 —— 垃圾进,垃圾出
作为大数据工程师,你一定听过 "Garbage In, Garbage Out"。在 RAG 系统中,这句话是铁律。
如果你直接把一本 500 页的 PDF 扔进向量库,效果一定很差。因为向量的承载能力有限,一段话太长,语义就被稀释了。
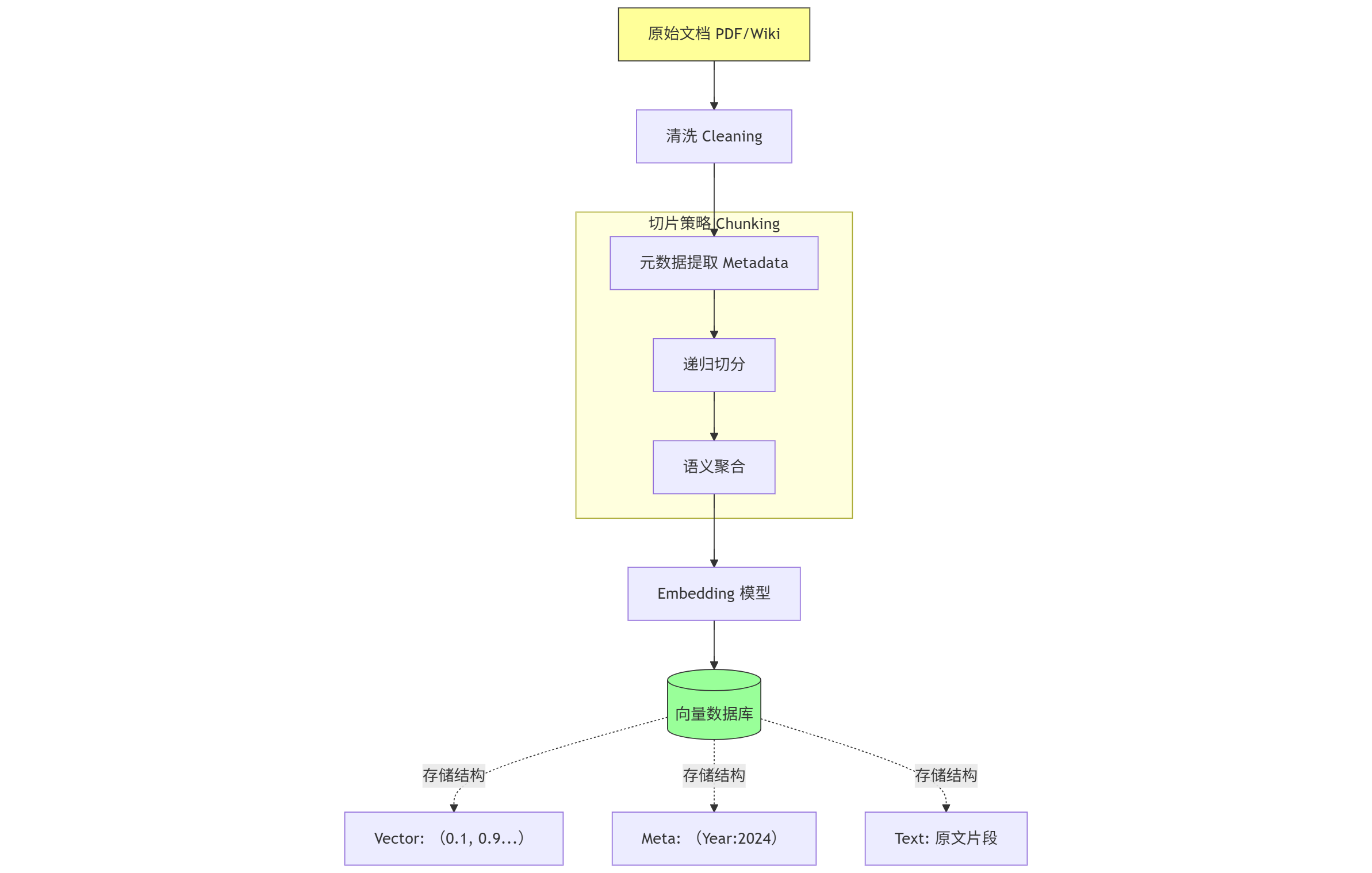
我们需要构建一条高精度的 ETL Pipeline。
1. 切片 (Chunking):切肉的刀法
切片是将长文本切分成小块的过程。这不仅仅是 split() 那么简单。
-
🔪 菜刀法:Fixed Size (固定大小)
- 做法:每 500 个字符切一刀,重叠 50 个字符。
- 缺点:极其粗暴。可能把“我喜欢吃苹果”切成“我喜欢吃”和“苹果”,语义直接断裂。
- 评价:❌ 生产环境慎用。
-
✂️ 手术刀法:Recursive Character (递归字符切分)
- 做法:先按段落 (
\n\n) 切,太长了就按句子 (.) 切,还长就按单词切。 - 优点:尽可能保留完整的语义结构。
- 评价:✅ 业界推荐标准(LangChain 默认策略)。
- 做法:先按段落 (
-
🧠 意念法:Semantic Chunking (语义切分)
- 做法:利用模型判断前后两句话的语义相似度。如果话题变了,就在这里切一刀。
- 优点:切出来的每一块都是一个独立、完整的话题。
- 评价:🌟 高级玩法,计算成本高,但效果最好。
2. 元数据提取 (Metadata Extraction):给数据打标签
这是大数据工程师的强项!不要只存 text 和 vector。
在写入向量库之前,必须通过正则、NLP 工具甚至大模型,提取出元数据:
- Source:
2024_Q1_Financial_Report.pdf - Page:
12 - Author:
John Doe - Year:
2024 - Category:
Finance
为什么要这么做?为了 Pre-filtering(前置过滤)。
场景模拟: 用户问:“2024年 Q1 的营收是多少?”
- 无元数据:向量检索在所有年份的文档里找“营收”,可能找回 2023 年的数据(因为语义很像)。
- 有元数据:SQL 逻辑先执行
WHERE Year = 2024,然后在剩下的数据里做向量搜索。准确率提升 100%!
👇 RAG 高级 ETL 流程图:
🚀 总结:架构师的“降维打击”
从大数据转型 AI,你的核心优势不在于调教模型参数,而在于对数据的掌控力。
- 普通开发者还在纠结用哪个 Embedding 模型时,你已经通过 混合检索 解决了专有名词识别问题。
- 算法工程师还在头疼检索不准时,你已经通过 ETL 流水线 和 元数据过滤,把干扰数据挡在了门外。
这就是 AI Infra 架构师 的价值:用工程化的手段,弥补算法的不确定性。
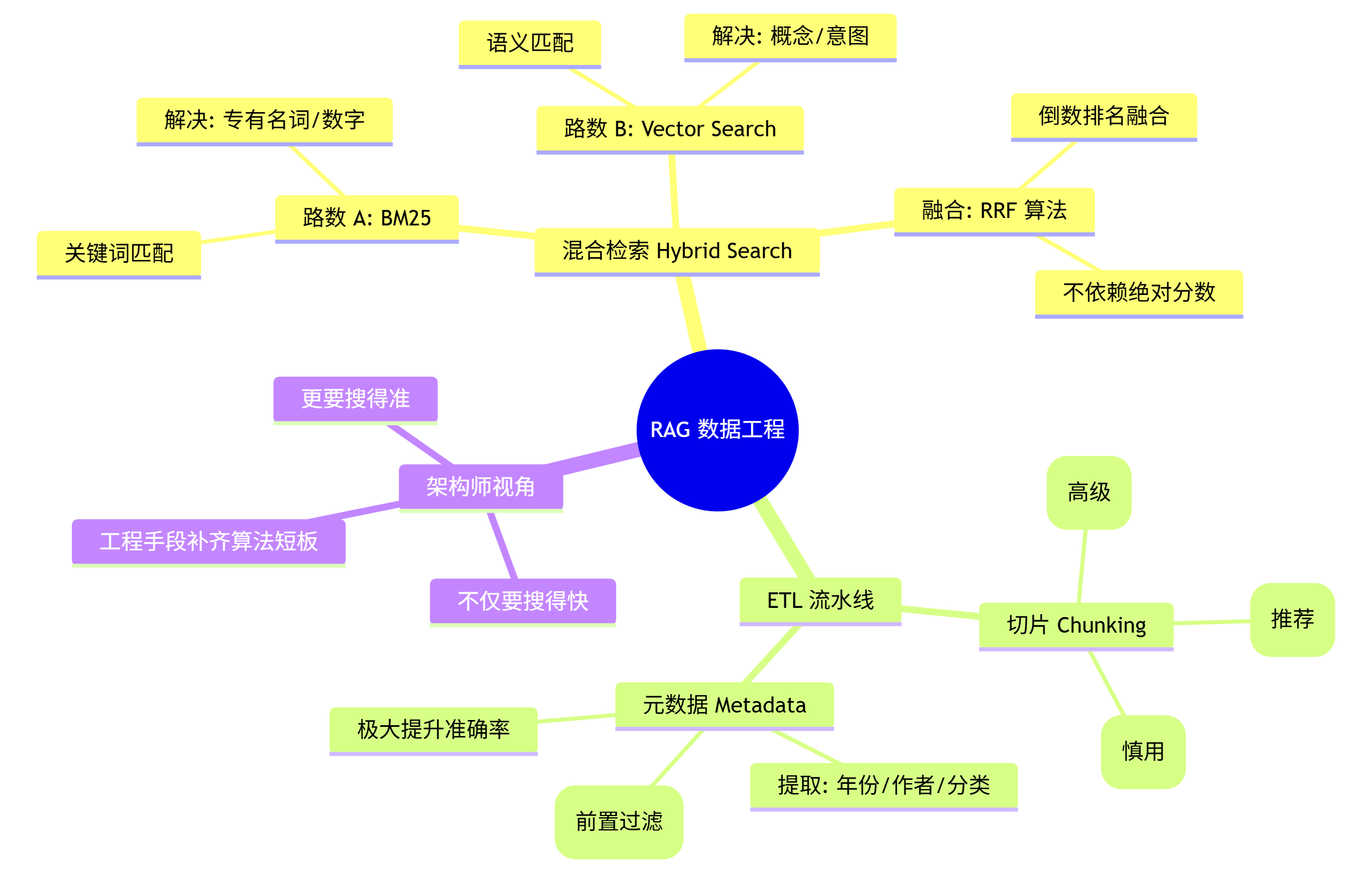
🧠 本文核心知识点思维导图
💬 互动话题
你在搭建 RAG 系统或学习向量数据库时,遇到过最坑的“答非所问”是什么情况? 是把“小米手机”搜成了“大米”,还是把“甲方”搜成了“乙方”?
欢迎在评论区留言,下一期我们将进入 Phase 5:实战项目与架构设计,手把手教你设计一个企业级私有知识库!
点赞、关注、转发,你的支持是我更新的动力!👇
