

本文价值提示:
💡 阅读时长:约 8 分钟 🎯 核心收获:从 Demo 到生产环境的跨越。你将掌握如何利用 Milvus + Elasticsearch 构建“混合检索”架构,解决 RAG 系统“查不准、存不下、慢吞吞”的三大顽疾。 💎 适用人群:大数据工程师、后端开发、正在转型 AI Infra 的架构师。
👋 大家好,我是你们的老朋友。
在之前的专题中,我们一起攻克了 Python 高级工程化 的堡垒,也深入探讨了 大模型基础理论 的奥秘。
今天,我们正式进入 “RAG 架构与数据工程” 专题的深水区——实战篇。
很多同学在后台问我:“我看过很多 RAG(检索增强生成)的教程,跑个 Demo 很简单,但一上公司的数据,AI 就开始‘胡言乱语’,要么查不到,要么查得慢,这是为什么?”
答案很简单:你只是搭了个玩具,而企业需要的是一座精密的“数据工厂”。
作为拥有大数据背景的你,今天我们要发挥核心优势,用工程化的思维,搭建一套亿级数据量下依然稳如泰山的企业级私有知识库 RAG 系统。
🏗️ 场景设定:当 AI 遇上“企业黑盒”
想象一下,你的公司有成千上万份 PDF 合同、Jira 里的 Bug 记录、Wiki 里的技术文档。这些数据是企业的“私有财产”,ChatGPT 没见过,也不允许见。
老板的需求是:做一个内部问答助手,员工问“去年双十一的服务器扩容方案是什么?”,它能立刻给出精准答案。
如果直接把所有文档扔给大模型,Token 费用能让你破产,而且上下文长度也受不了。
这时候,我们需要 RAG(Retrieval-Augmented Generation)。
如果把大模型比作一个 “超级学霸”,那 RAG 就是一场 “开卷考试”。
- 向量数据库:就是学霸手里的 “教科书”。
- 检索(Retrieve):学霸翻书找答案的过程。
- 生成(Generate):学霸根据找到的内容,组织语言回答问题。
今天我们要解决的核心问题是:如何让这本“教科书”编排得井井有条,让学霸翻书的速度快到飞起?
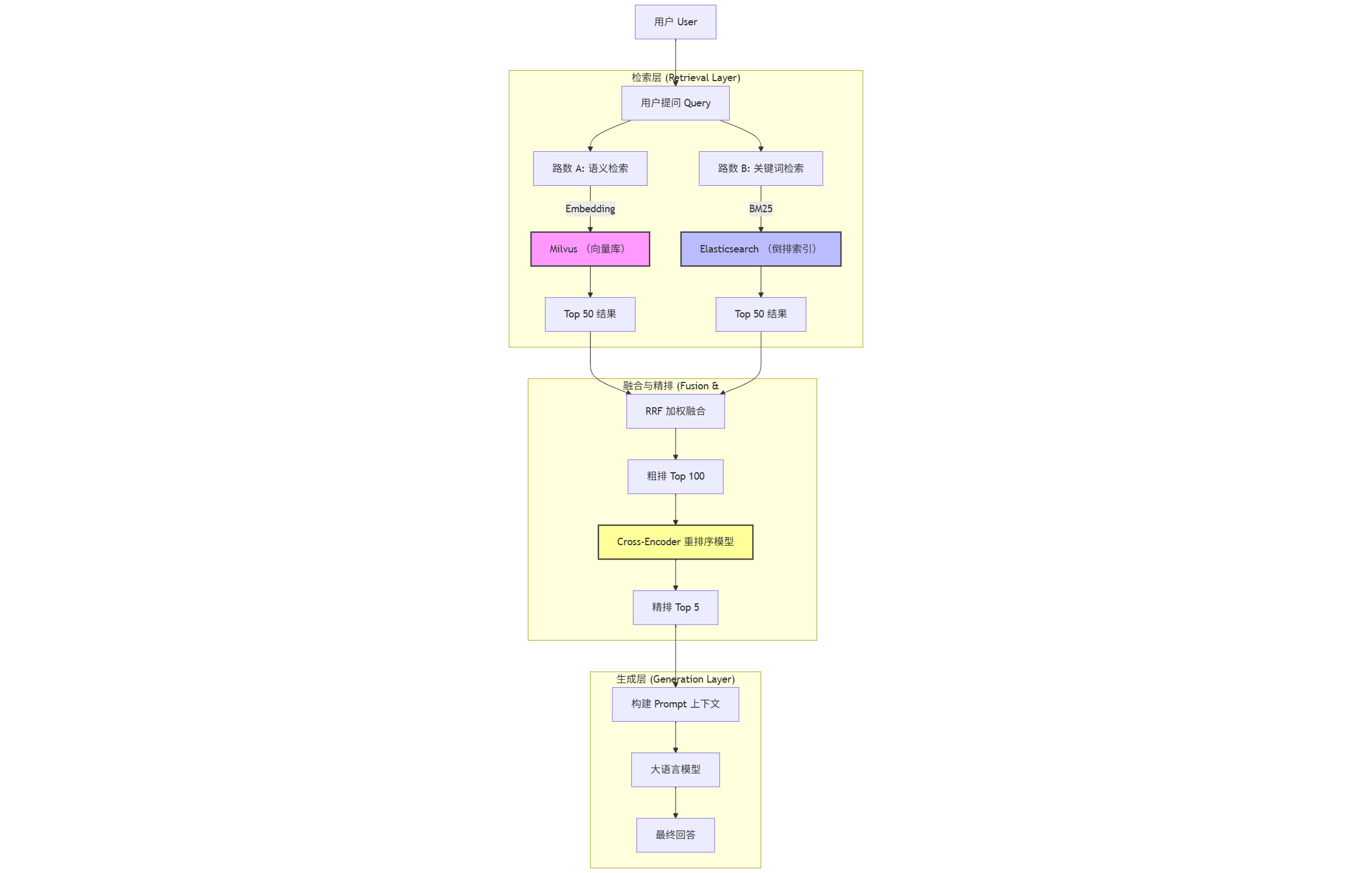
⚔️ 架构设计:双剑合璧(Milvus + ES)
在 Demo 阶段,很多人只用一个简单的向量库(如 Chroma)。但在生产环境,单纯的向量检索(Vector Search)有一个致命弱点:对精确匹配支持极差。
比如你搜“iPhone 15 Pro Max 价格”,向量检索可能会给你推荐“安卓旗舰手机性价比”,因为它们在语义上很像。但用户要的是精准的型号。
所以,架构师的杀手锏是:混合检索(Hybrid Search)。
我们要设计一套 “左右互搏” 的数据层架构:
- 左手画圆(语义检索):使用 Milvus。
- 特长:理解“意思”。比如搜“好用的苹果”,它能找到“水果”也能找到“手机”。
- 角色:负责模糊匹配,捕捉潜在关联。
- 右手画方(关键词检索):使用 Elasticsearch。
- 特长:死磕“字面”。比如搜“Error 503”,它绝不会给你匹配“网络通畅”。
- 角色:负责精确匹配,兜底专有名词。
📐 系统架构蓝图
为了让你一目了然,我画了一张架构流程图:
🏭 流水线工程:ETL 的艺术
架构定好了,数据怎么进去?这不仅仅是 Insert 那么简单,这是 RAG 的 “消化系统”。如果吃进去的是垃圾,吐出来的必然是垃圾(Garbage In, Garbage Out)。
我们需要使用 Python (LangChain/LlamaIndex) 编写一套健壮的 ETL 流水线。
1. 切片(Chunking):不要把“苹果”切成“苹”和“果”
很多新手直接按 500 字符暴力切割,结果把一句话切断了,语义全丢。
- 推荐策略:
RecursiveCharacterTextSplitter(递归字符切分)。 - 逻辑:先按段落切,段落太长按句子切,句子太长按标点切。保证语义块的完整性。
2. 元数据提取(Metadata Extraction):隐形的翅膀
这是大数据工程师最擅长的领域。在写入向量库时,千万别只存向量!
一定要提取元数据:{"year": 2023, "dept": "HR", "type": "PDF"}。
为什么要这么做? 想象一下,你要在 1 亿条数据里找“2024年的人事制度”。
- 做法 A(无元数据):在 1 亿条向量里暴力搜索,算出 TopK,然后再看是不是 2024 年的。效率低,干扰大。
- 做法 B(Pre-filtering):先用元数据过滤出
year=2024的数据(可能只有 1 万条),再在这 1 万条里做向量搜索。速度快 100 倍,准确率飙升。
🧠 核心算法:混合检索 + 重排序
这是让 RAG 从“人工智障”变身“领域专家”的关键一步。
第一步:混合检索(Hybrid Search)
我们同时发起两个查询:
- Milvus 返回语义最接近的 50 条。
- ES 返回关键词匹配度最高的 50 条。
然后使用 RRF (Reciprocal Rank Fusion) 算法将两份名单合并。简单来说,就是谁在两份名单里排名都靠前,谁的最终得分就高。
第二步:重排序(Re-ranking)—— 点石成金
经过混合检索,我们得到了 Top 100 个候选片段。但这 100 个片段里,可能第 1 名是错的,第 50 名才是对的。
因为向量检索(Bi-Encoder)为了速度,牺牲了一点精度。
这时候,我们需要引入一位 “精细的阅卷老师”——Cross-Encoder 模型(如 BGE-Reranker)。 它会把“用户问题”和“候选片段”拼在一起,逐字逐句地比对,打出一个精准的分数。
虽然它慢,但我们只让它算 100 条,耗时完全可控(通常 < 200ms)。 经过 Re-ranking 选出的 Top 5,才是真正喂给大模型的“黄金上下文”。
🛡️ 架构师交付物:不仅仅是代码
作为架构师,你不能只丢给老板一段代码。你需要交付的是决策和保障。
1. 选型报告:为什么是 Milvus?
老板可能会问:“隔壁组用的 Pinecone,为什么我们要自己搭 Milvus?” 你的回答应该是:
- 成本:Pinecone 是 SaaS,按量付费,数据量大了是天价。Milvus 开源,我们可以复用现有的 K8s 资源。
- 隐私:公司合同数据极其敏感,不能出内网。Milvus 支持私有化部署(On-premise)。
- 生态:Milvus 的架构(Proxy, Coord, Node)和我们熟悉的 Kafka/HDFS 很像,运维团队上手快。
2. 容量规划:拒绝内存爆炸
假设我们要存 1 亿条 向量,每条向量 768 维度。需要多少内存? 别拍脑袋!拿出公式:
- 原始数据:10^8 × 768 × 4 B ≈ 300 GB
- HNSW 索引开销:通常是原始向量的 1.5 倍左右。
- 总计:你需要准备至少 450GB - 500GB 的内存资源。
- 结论:单机搞不定,必须上 Milvus Cluster 分布式集群。
3. 高可用方案
- 读写分离:Milvus 天然支持。写入节点(DataNode)和查询节点(QueryNode)是分开的,写数据不会卡顿查询。
- 故障恢复:依赖 Etcd 做元数据存储,Pulsar/Kafka 做消息流,MinIO 做持久化存储。任何一个节点挂了,K8s 拉起来就能继续跑,数据不丢。
📝 总结
从大数据工程师转型 AI 架构师,你的核心优势不在于调教 Prompt,而在于驾驭大规模数据的能力。
搭建企业级 RAG,本质上是在解决三个问题:
- 存得下:利用分布式向量库(Milvus)解决海量存储。
- 查得准:利用混合检索(Milvus + ES)和重排序(Re-ranking)解决语义偏差。
- 跑得稳:利用 ETL 流水线和云原生架构保证系统高可用。
当你把这套架构落地时,你交付的不再是一个简单的问答机器人,而是一个企业的数字化大脑。
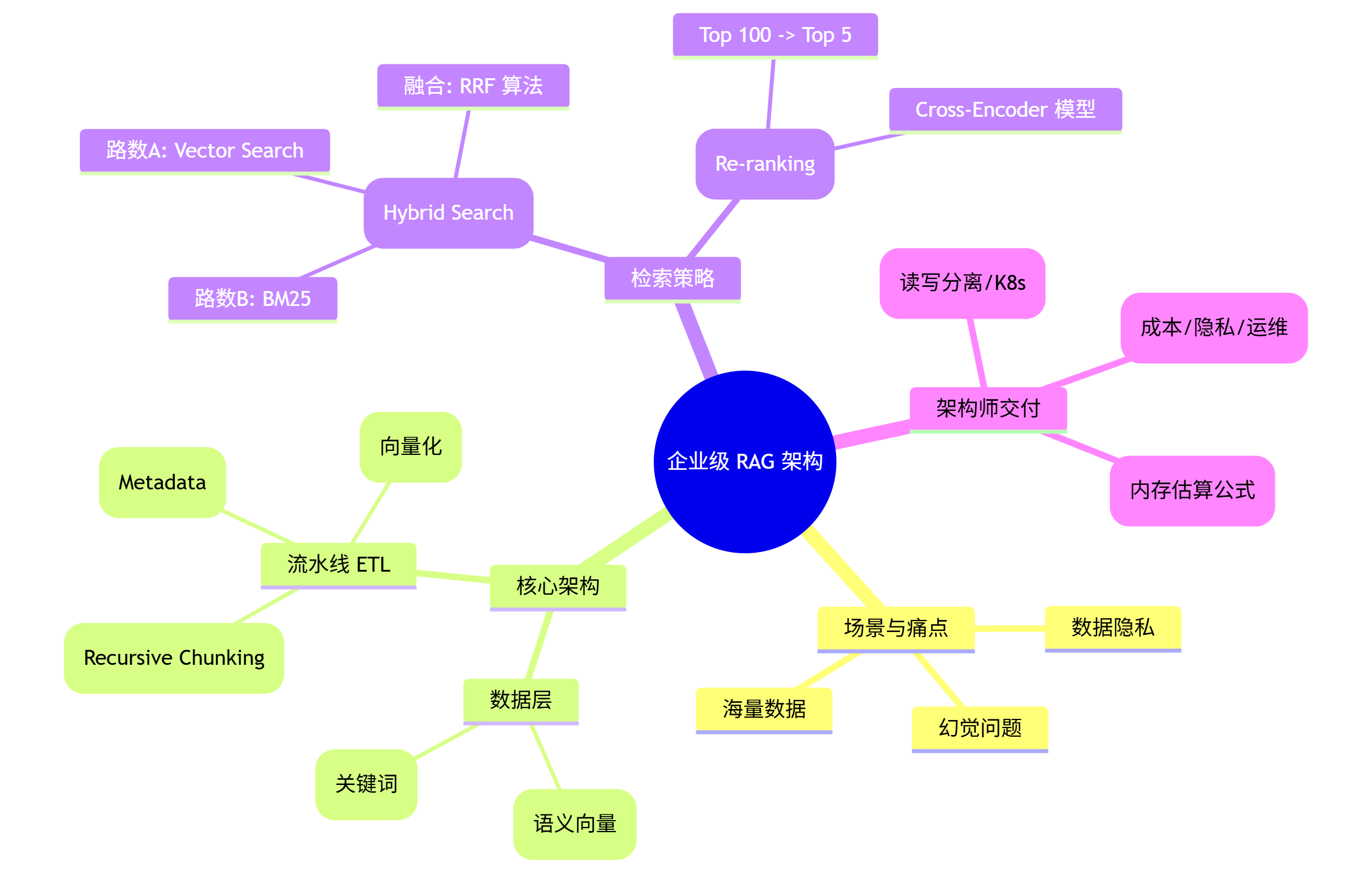
🧠 本文思维导图
最后,为大家梳理了本文的核心知识点,建议保存收藏:
💬 互动话题
你在搭建 RAG 系统时,遇到过最坑的问题是什么? A. 向量库内存爆了 B. 搜出来的东西驴唇不对马嘴 C. 写入速度太慢,像蜗牛爬 D. 还没开始,正在学习中
欢迎在评论区留言,告诉我你的“血泪史”,下期我们针对痛点逐一击破!👇
下一期预告:我将以一个真实的 “企业级技术文档问答系统” 为例,带你从零开始,写出能够部署在生产环境的 RAG 代码。
