

本文价值提示 💎
- 面向人群:正在从大数据/后端转型 AI 架构的工程师。
- 核心解决:RAG 系统上线后“查得慢”和“内存爆炸(OOM)”的致命问题。
- 阅读收益:深入理解 HNSW、IVF、DiskANN 三大核心算法原理,掌握生产环境下的性能调优策略。
👋 大家好,我是你们的转型领路人。
在之前的专题中,我们聊完了《Python 高级工程化》和《大模型基础理论》。今天,我们正式进入 RAG 架构与数据工程 专题的第三篇——向量数据库的“心脏”:索引算法与性能调优。
很多大数据工程师在刚接触向量数据库(Vector DB)时,容易陷入一个误区:
“不就是存数据、查数据吗?和 MySQL 建个 B+ 树,或者 ES 建个倒排索引有什么区别?”
区别大了去了! 💥
当你把 Demo 里的 1 万条数据扩展到生产环境的 1 亿条(甚至 10 亿条) 时,你会发现:
- 内存炸了:服务器 256G 内存瞬间被吃光,OOM 报警响个不停。
- CPU 满载:一个查询耗时从 20ms 飙升到 2s,用户在前端等到花儿都谢了。
这背后的罪魁祸首,就是你没有选对、或者没有调优 向量索引(Vector Index)。
今天,我们就用大数据工程师熟悉的视角,扒开向量数据库的底层,看看如何驾驭这匹“脱缰的野马”。
01 为什么不能暴力硬算?(FLAT vs ANN)
在 SQL 世界里,WHERE id = 10086 是精确查找。但在向量世界里,我们要找的是“和这个向量最像的 Top K 个向量”。
最笨的方法叫 FLAT(暴力搜索)。 假设你有 1 亿条数据,来了一个查询向量。FLAT 策略就是:拿着这个向量,和库里的 1 亿个向量,逐一计算距离,然后排序。
- 优点:100% 准确(召回率 100%)。
- 缺点:慢到令人发指。在大规模数据下,这简直是计算资源的黑洞。
所以,业界引入了 ANN(Approximate Nearest Neighbor,近似最近邻搜索)。 核心思想:牺牲一点点精度(比如 99% 的召回率),换取极致的速度(毫秒级响应)。
接下来,我们要介绍的三位“大将”,都是 ANN 家族的杰出代表。
02 HNSW:速度之王,内存黑洞 🚀
全称:Hierarchical Navigable Small World (分层导航小世界图) 地位:目前业界最主流、性能最强悍的纯内存索引算法(Milvus, Chroma, Weaviate 默认首选)。
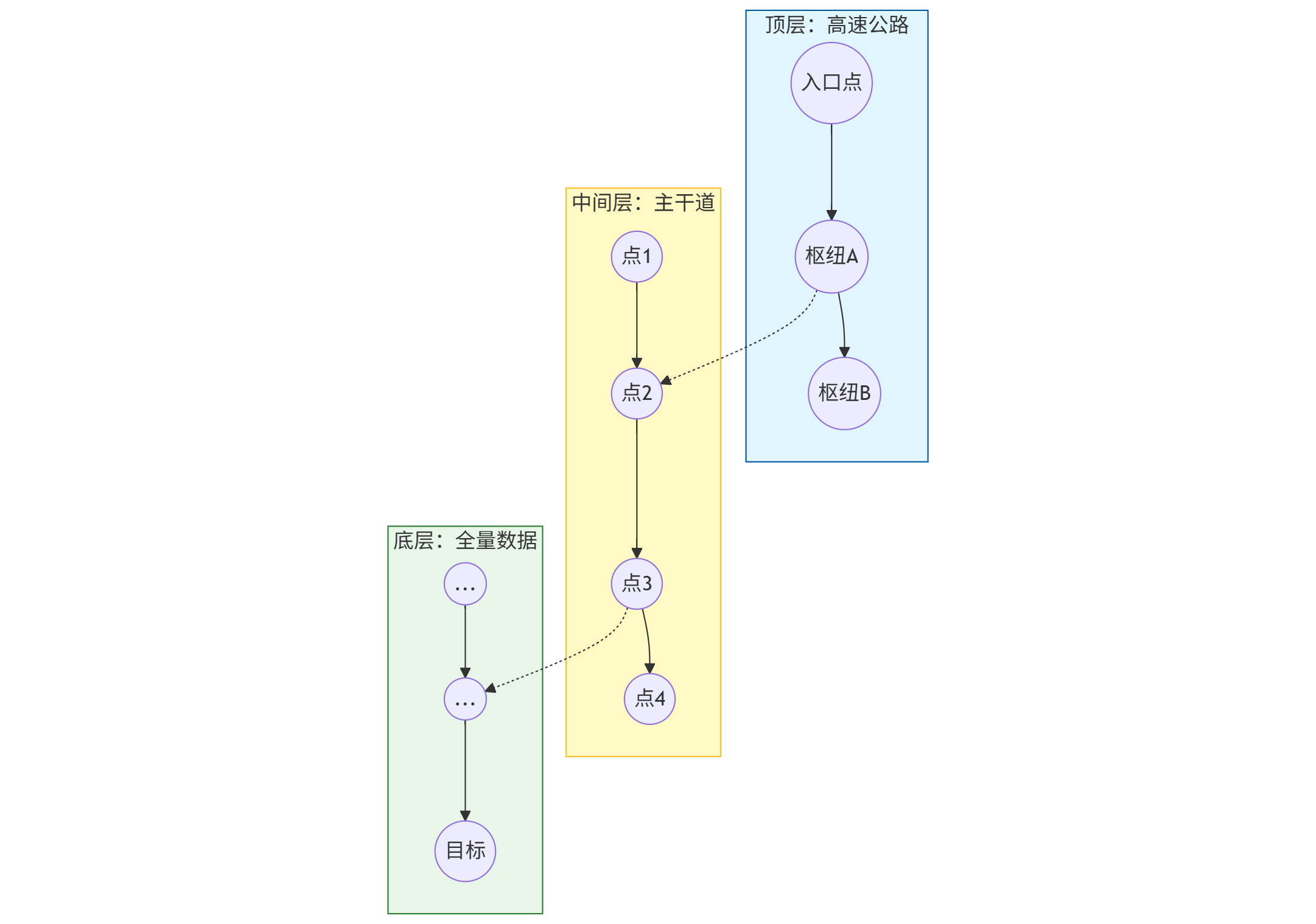
🧐 原理大白话:高维空间的“跳表”
作为大数据工程师,你一定熟悉 HBase 或 Redis 里的 Skip List(跳表)。 HNSW 其实就是图(Graph)版本的跳表。
想象一下,你要在一个拥挤的城市(高维空间)里找到某个地标(目标向量):
- 第 0 层(最底层):包含了所有的街道和胡同,密密麻麻,走起来很慢。
- 第 1 层:只保留了主干道。
- 第 2 层:只保留了高速公路。
- 顶层:只有几个核心交通枢纽。
搜索过程: 你从顶层枢纽出发,先在高速公路上大跨步移动,迅速锁定大概区域;然后降级到主干道,缩小范围;最后降级到底层胡同,进行精细查找。
🛠️ 调优关键参数 (大数据工程师必看)
在 Milvus 或 ES 中配置 HNSW 时,有两个参数决定了你的生死:
M(Max Links / 邻居数)- 含义:图中每个节点最多连接多少个其他节点。
- 影响:
M越大,图越稠密,查询越准,但内存消耗越大,建索引越慢。 - 经验值:通常在 16~64 之间。
efConstruction(构建深度)- 含义:建图时,为了找邻居,我预先搜索多深?
- 影响:值越大,图的质量越好(高速公路规划得越合理),查询越快,但写入/构建索引极慢。
- 经验值:通常是
M的 2-4 倍。
⚠️ 致命弱点
内存占用极大! HNSW 除了存向量数据本身,还要存复杂的图关系(邻接表)。
- 估算公式:原始向量大小 + 额外 30%~50% 的图结构开销。
- 如果你有 1 亿条 768 维的 float32 向量,原始数据约 300GB。加上 HNSW 索引,可能需要 400GB+ 的纯内存。
- 结论:土豪专用,或者数据量在千万级以下使用。
03 IVF:经济适用男,大数据的“分区裁剪” ✂️
全称:Inverted File Index (倒排文件索引) 地位:内存受限场景下的首选,Faiss 库的经典算法。
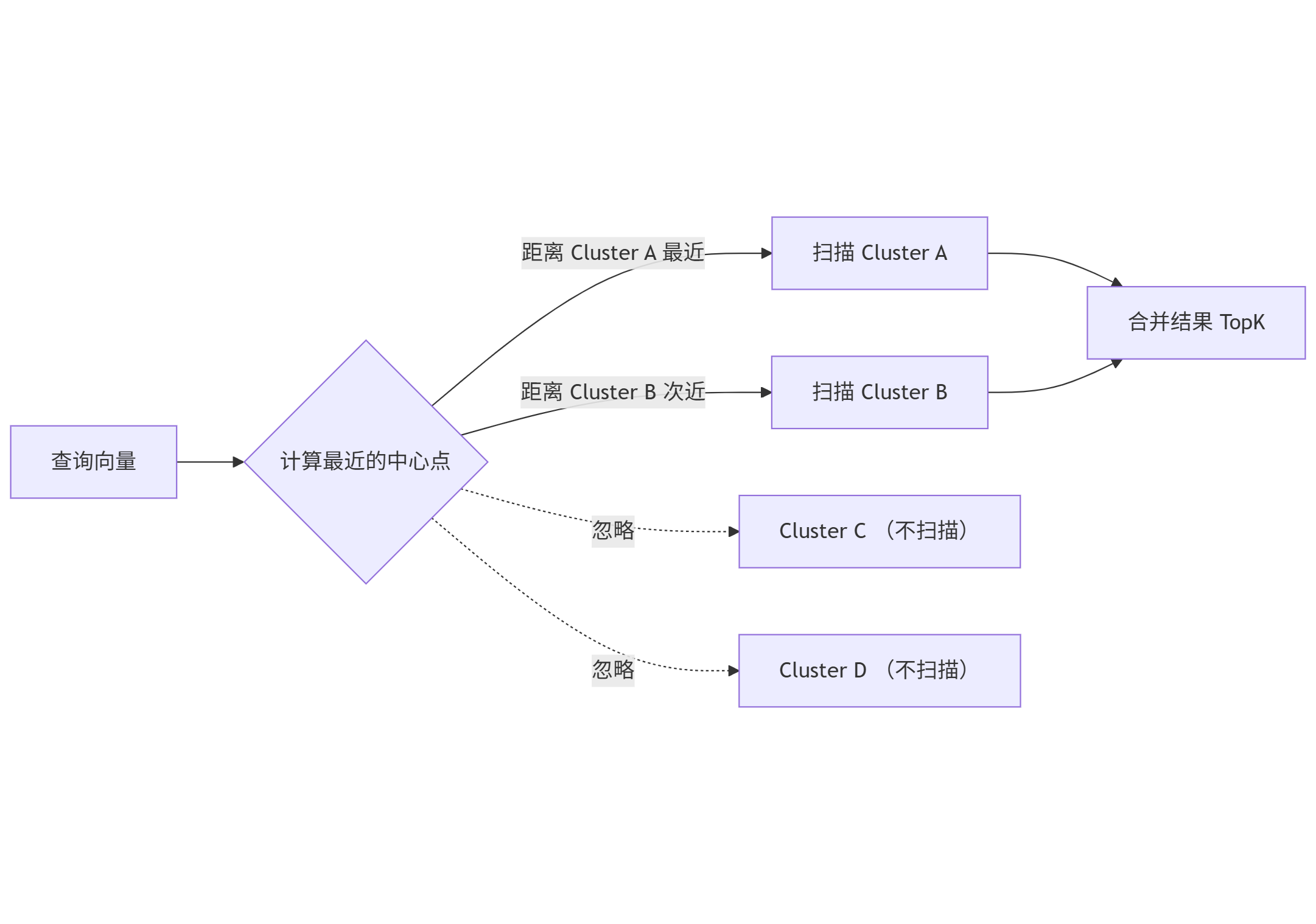
🧐 原理大白话:高维空间的“聚类分区”
大数据工程师对 Hive 的 Partition(分区) 或者 Spark 的 Bucket 一定不陌生。 IVF 的核心思想就是分治(Divide and Conquer)。
- 训练(Train):先从数据里随机采样,用 K-Means 聚类算法,把高维空间切分成
nlist个簇(Cluster/Bucket),找到每个簇的中心点(Centroid)。 - 写入:新向量进来,算出它离哪个中心点最近,就丢进哪个簇里(类似 Hive 写入特定分区)。
- 查询:查询向量来了,先算出它离哪几个中心点最近(比如最近的 3 个),然后只在这 3 个簇里进行搜索,其他的簇直接忽略。
这不就是数据库里的 Partition Pruning(分区裁剪)吗? 没错,一模一样!
🛠️ 调优关键参数
nlist(聚类中心数)- 含义:把数据切分成多少份。
- 影响:
nlist越大,每个桶的数据越少,查询越快,但训练耗时增加。 - 经验值:4096 ~ 16384 (针对百万/千万级数据)。
nprobe(探测桶数)- 含义:查询时,我要搜最近的几个桶?
- 影响:这是性能与精度的平衡杆。
nprobe越大,搜的桶越多,越准,但越慢。 - 经验值:通常设为
nlist的 1% ~ 10%。
⚠️ 致命弱点
- 需要训练(Train):必须先有一批数据才能建立索引,冷启动麻烦。
- 维数灾难:如果数据分布极度不均匀(Data Skew),某些桶会特别大,导致查询长尾延迟(和 Spark 数据倾斜一个道理)。
04 DiskANN:十亿级数据的救星 💾
场景:老板说“我们要存 10 亿条数据,但不想买 4TB 内存的服务器”。 方案:DiskANN (Vamana 图算法)。
🧐 原理大白话:SSD 也是一种“慢内存”
HNSW 之所以必须全内存,是因为它的随机访问太频繁,机械硬盘扛不住。 但现在的 NVMe SSD 随机读性能已经非常强悍了。
DiskANN 的魔法在于:
- 内存里:只存一个极度压缩的向量索引(量化后的,精度低),用来快速导航。
- 磁盘上:存储完整的图结构和原始向量。
- 查询时:利用 SSD 的高并发随机读(IOPS),在磁盘上“跳跃”搜索。
结果:用 1/10 的内存,跑出了接近纯内存 HNSW 的性能。
05 总结:架构师的选型指南 🧭
作为 AI Infra 架构师,你的价值就在于根据业务场景做 Trade-off(权衡)。
| 场景特征 | 推荐索引 | 理由 | 大数据类比 |
|---|---|---|---|
| 数据量 < 1000万 追求极致低延迟 | HNSW | 内存能抗住,速度最快,运维最简单。 | Redis 全内存操作 |
| 数据量 1000万 ~ 1亿 内存预算有限 | IVF_FLAT IVF_SQ8 | 通过聚类减少搜索范围,SQ8 还能压缩向量体积。 | Hive 分区表 + Parquet 压缩 |
| 数据量 > 5亿 成本敏感 | DiskANN | 榨干 SSD 性能,大幅降低硬件成本。 | HBase (LSM Tree) 冷热分离 |
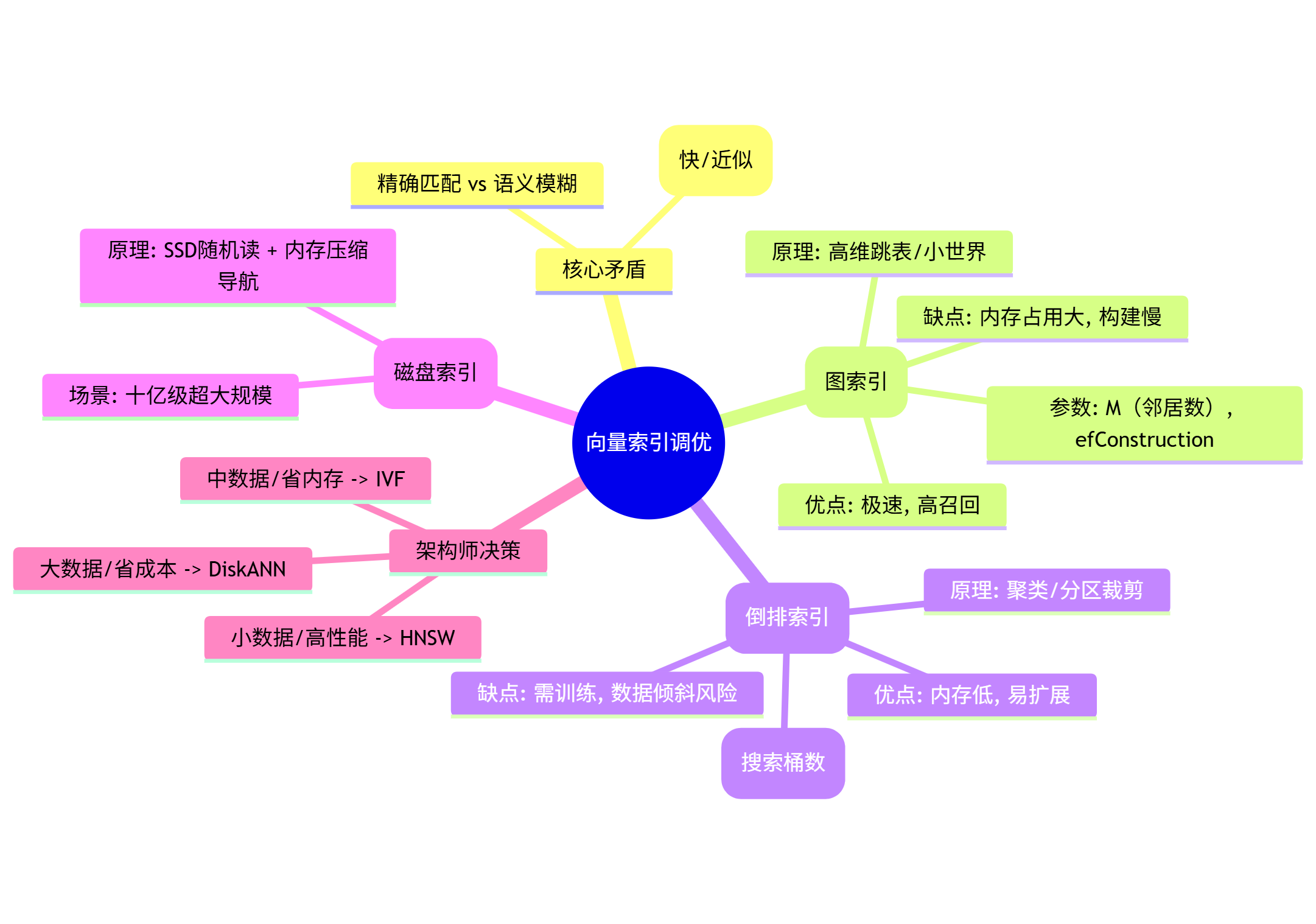
🧠 本文思维导图
⏭️ 下期预告
搞定了“存得下”和“查得快”,但 RAG 系统最怕的是 “查得不准”。 比如用户搜“苹果手机”,向量检索可能会给你返回“苹果这种水果的营养价值”,因为它们在语义空间里离得近。
如何解决? 下一篇,我们将进入 Phase 4:混合检索(Hybrid Search)与 RAG 数据流水线。我们将结合 Elasticsearch 的关键词检索 与 向量检索,并引入 Re-ranking(重排序) 技术,打造一个企业级的“高精度”搜索系统。
👇 互动话题: 你在搭建 RAG 或使用向量库时,遇到过 OOM(内存溢出) 或者 查询超过 1 秒 的情况吗?你是怎么解决的?欢迎在评论区留言,我们一起“诊断”一下!
这是 RAG 架构与数据工程系列的第三篇。关注我,带你从大数据工程师无缝进阶 AI 架构师! 🚀
