

目录
前言
碎碎念:很危险,命运的大手一挥。非常符合心理学上的“谁痛苦谁改变”原则
本文主要是做个复习。review面向对象,封装、继承、多态。 神经网络基本概念:前向传播,反向传播,损失函数,梯度下降,激活函数。pytorch框架:tensor操作,自动求导,模型搭建,数据加载
目标:
细分llm岗位层面
巩固面向对象编程
熟悉向量空间,矩阵运算,微积分与概率统计等知识,便于理解transformer
热身手撕完整神经网络训练。
1、python_quick_review
增删字典键值对
d['gender']='male'
del d[ 'name']
遍历字典:
list((key,value) for key,value in student.items())
调用split()函数返回的是一个列表
编辑
字典收集
for word in words:
word_count[ word ]= word_count.get(word, 0)+1
文件操作
编辑
异常处理
编辑
面相对象
实例化
封装
控制类成员(属性和方法)的访问来保护数据 。
将属性和方法绑定在一起,保护类内部的具体细节,只保留必要的接口给外部使用
继承
允许一个子类继承另一个类(父类)的属性和方法,可以提高代码复用效率
多态
允许不同类的对象通过同一个接口调用不同的实现(简单说就是不同对象用同一个方法)
leetcode转acm格式,实例化。map是转为int型的操作
a,b=map(int,input.split())
sol.Solution()
print(sol.sum(a,b))
2、大模型数学基础
线性操作
编辑
完整优化
# 1. 准备数据
# 2. 初始化参数
# 3. 训练: 正向传播计算模型预测输出,计算损失,计算梯度,更新参数 w-=learning_rate*dw
3、Pytorch_quick_review
神经网络结构:
输入层,隐藏层,输出层,其实就是一个函数,每一个神经元代表一个参数,每一个参数对x进行运算最后得到y
损失函数:
交叉熵损失(分类概率匹配),mse(连续值预测),对抗损失(生成数据分布匹配真实分布),对比损失(学习相似性和差异性),策略梯度损失(最大化累积奖励,强化学习),多任务加权损失(同时优化多个目标;目标检测、多模态任务)
梯度下降:
点的切线,想变小就往切线负值走
为什么训练不稳定,有的时候一次训练并不能达到完美的结果? 因为初始点选择不一样,梯度下降走到的最小值也不一样,即局部最优不是全局最优。
0-1?
构建一个网络,前向传播,loss更新参数,预测
张量:(本来用矩阵,英伟达让我用上张量了)
编辑
张量计算
编辑
模型运算
其实就是输入一个矩阵x , 乘以一个矩阵(隐藏层),再乘以一个矩阵(隐藏层)。。。。输出层,期间再需要进行非线性变换
初始化的时候定义不同的矩阵层
模型的创建
编辑
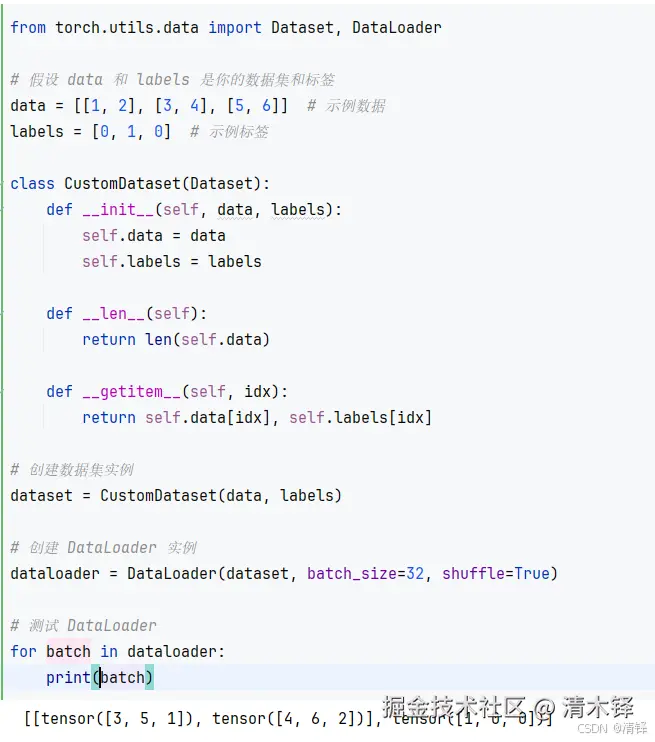
数据处理
batchsize 就是把几个样本打包一次 进行运算,才不会一个个算太慢了
 编辑
编辑
shuffle=True 会在每个 epoch 开始时随机打乱样本的索引顺序,从你的输出反推,打乱后的索引顺序是:[1, 2, 0](即第 2 个样本→第 3 个样本→第 1 个样本)。
DataLoader 默认会用default_collate函数把一个 batch 内的样本拼接成 Tensor:
-
数据部分:把 3 个样本的特征按列拼接
- 原始打乱后的数据:
[[3,4], [5,6], [1,2]] - 拼接后:第一列特征
[3,5,1],第二列特征[4,6,2]→ 对应[tensor([3, 5, 1]), tensor([4, 6, 2])]
- 原始打乱后的数据:
-
标签部分:把 3 个标签直接拼接成一个 Tensor →
tensor([1, 0, 0])
__getitem__返回的是(数据, 标签),所以每个 batch 是一个元组(数据Tensor组, 标签Tensor)- 数据部分是二维的(3 个样本 ×2 个特征),PyTorch 默认按行拆分展示为两个一维 Tensor(特征 1 列、特征 2 列)
- 如果想让数据部分显示为一个二维 Tensor,可以修改
__getitem__返回 Tensor 类型:
测试用例
# 1. 导入PyTorch核心模块
import torch # PyTorch基础库,提供张量操作、设备管理等核心功能
import torch.nn as nn # 神经网络模块,包含所有层、损失函数等
import torch.optim as optim # 优化器模块,包含SGD、Adam等优化算法
from torch.utils.data import Dataset, DataLoader # 数据加载核心类:Dataset(自定义数据集)、DataLoader(批量加载)
# 2. 定义训练数据和标签(线性关系:y=2x)
# 示例输入数据,形状为[4,1](4个样本,每个样本1个特征),指定float32是为了匹配PyTorch默认精度
data = torch.tensor([[1.0], [2.0], [3.0], [4.0]], dtype=torch.float32)
# 示例标签,形状为[4,1](4个样本,每个样本1个标签),对应y=2x的结果
labels = torch.tensor([[2.0], [4.0], [6.0], [8.0]], dtype=torch.float32)
# 3. 自定义数据集类(必须继承torch.utils.data.Dataset)
class CustomDataset(Dataset):
# 初始化函数:接收数据和标签,绑定为类属性
def __init__(self, data, labels):
self.data = data # 保存输入数据
self.labels = labels # 保存标签数据
# 必须实现:返回数据集总长度(DataLoader需要知道样本总数)
def __len__(self):
return len(self.data) # 这里返回4,因为data有4个样本
# 必须实现:根据索引idx返回单个样本(DataLoader批量读取时会调用此方法)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx] # 返回(单个输入样本, 单个标签),均为张量
# 4. 创建自定义数据集实例
dataset = CustomDataset(data, labels) # 将数据和标签传入,实例化数据集
# 5. 创建DataLoader(批量加载数据的核心工具)
# batch_size=2:每次返回2个样本;shuffle=True:每个epoch打乱样本顺序(提升训练泛化性)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
# 6. 定义线性回归模型(必须继承nn.Module)
class TinyModel(nn.Module):
# 初始化函数:定义模型层
def __init__(self):
super(TinyModel, self).__init__() # 必须调用父类构造函数,初始化nn.Module的核心属性
# 定义线性层:nn.Linear(in_features=1, out_features=1)
# 输入维度1(每个样本1个特征),输出维度1(预测1个值),内部包含权重w和偏置b两个可训练参数
self.linear = nn.Linear(1, 1)
# 前向传播函数(必须实现):定义数据通过模型的计算路径
def forward(self, x):
# x输入形状:[batch_size, 1],经过线性层后输出形状仍为[batch_size, 1]
return self.linear(x)
# 7. 定义训练设备(自动选择GPU/CPU)
# torch.cuda.is_available():检查是否有可用的NVIDIA GPU;有则用cuda,否则用cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 8. 初始化模型、损失函数、优化器
model = TinyModel().to(device) # 实例化模型,并将模型参数移动到指定设备(GPU/CPU)
criterion = nn.MSELoss() # 定义损失函数:均方误差(适用于回归任务)
# 定义优化器:随机梯度下降(SGD)
# model.parameters():传入模型所有可训练参数(这里是linear层的w和b);lr=0.01:学习率(控制参数更新步长)
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 9. 训练循环(核心:10个epoch,每个epoch遍历所有样本)
for epoch in range(10): # epoch:训练轮数,这里训练10轮
model.train() # 将模型设为训练模式(对dropout、BN等层有影响,线性模型无影响但养成习惯)
# 遍历DataLoader,每次获取一个batch的样本
for inputs, labels in dataloader:
# 将当前batch的输入和标签移动到指定设备(必须和模型同设备,否则报错)
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播:将输入传入模型,得到预测值
outputs = model(inputs) # outputs形状:[2,1](batch_size=2)
# 计算损失:criterion(预测值, 真实标签),返回标量损失值
loss = criterion(outputs, labels)
# 反向传播与参数更新(三步法:清空梯度→计算梯度→更新参数)
optimizer.zero_grad() # 清空所有参数的梯度(避免梯度累积,每批样本重新计算梯度)
loss.backward() # 反向传播:计算损失对所有可训练参数的梯度
optimizer.step() # 优化器更新参数:w = w - lr * w.grad,b = b - lr * b.grad
# 每个epoch结束后打印损失(这里打印的是最后一个batch的损失)
print(f"Epoch [{epoch+1}/10], Loss: {loss.item():.4f}")
# 10. 测试模型(推理阶段)
model.eval() # 将模型设为评估模式(禁用dropout、BN的训练行为,线性模型无影响但养成习惯)
with torch.no_grad(): # 上下文管理器:禁用梯度计算(提升推理速度,节省显存)
# 定义测试输入:形状[1,1](1个样本,1个特征),移动到指定设备
test_input = torch.tensor([[5.0]], dtype=torch.float32).to(device)
# 前向传播得到预测结果
predicted_output = model(test_input)
# 打印预测结果:item()将标量张量转为Python数值,保留4位小数
print(f"Predicted output for input 5.0: {predicted_output.item():.4f}")
岗位要求
核心:怎么分析场景需求 去建立pipline。 数据是怎么构造的,在优化中是选择策略解决还是调整模型参数。
有一个项目——>拿到一个实习——>到企业拿到infra层项目
AI_infra层:(大部分的政府和国企都需要这类人)
构建扎实的系统工程能力,推理框架,算子优化,分布式计算和服务
编辑
编辑
心态上:预计找到实习后干的活也是数据层的,that's not a dirty work !
马车夫遇上工业革命。
