

在将大模型引入科研阅读、写作与知识管理之后,很多研究者都会遇到一个极其关键的问题:AI 很强,但它并不真正“读得懂”我积累多年的 PDF 文献。
这并不是模型能力不足,而是知识载体不匹配。
本文将分享一套从 PDF 文献 → 结构化文本 → AI 知识库 → 可检索/可追溯智能对话的完整工作流,帮助你构建真正的科研“第二大脑”。
问题的根源:PDF 并不是为 AI 准备的
PDF 的设计初衷是视觉一致性,而非语义可读性。多栏排版、公式嵌套、复杂的表格往往让模型在解析时产生大量“噪声”,导致两个直接后果:
- 检索质量差:向量搜索难以精准定位。
- 生成不可靠:容易出现事实性错误(幻觉)。
因此,构建知识库的第一步,是把 PDF 转换为 AI 友好的 Markdown 格式。
第一步:基于 MinerU 的高质量本地转换
为了解决学术 PDF 转换质量不稳定的问题,我们采用基于 MinerU 的本地转换方案。
1. 核心优势
- 本地运行:数据不出机,保护未发表科研成果。
- 结构优化:针对学术论文的公式、表格、层级结构深度优化。
- 批量处理:支持一键扫描 Zotero 库或普通文件夹。
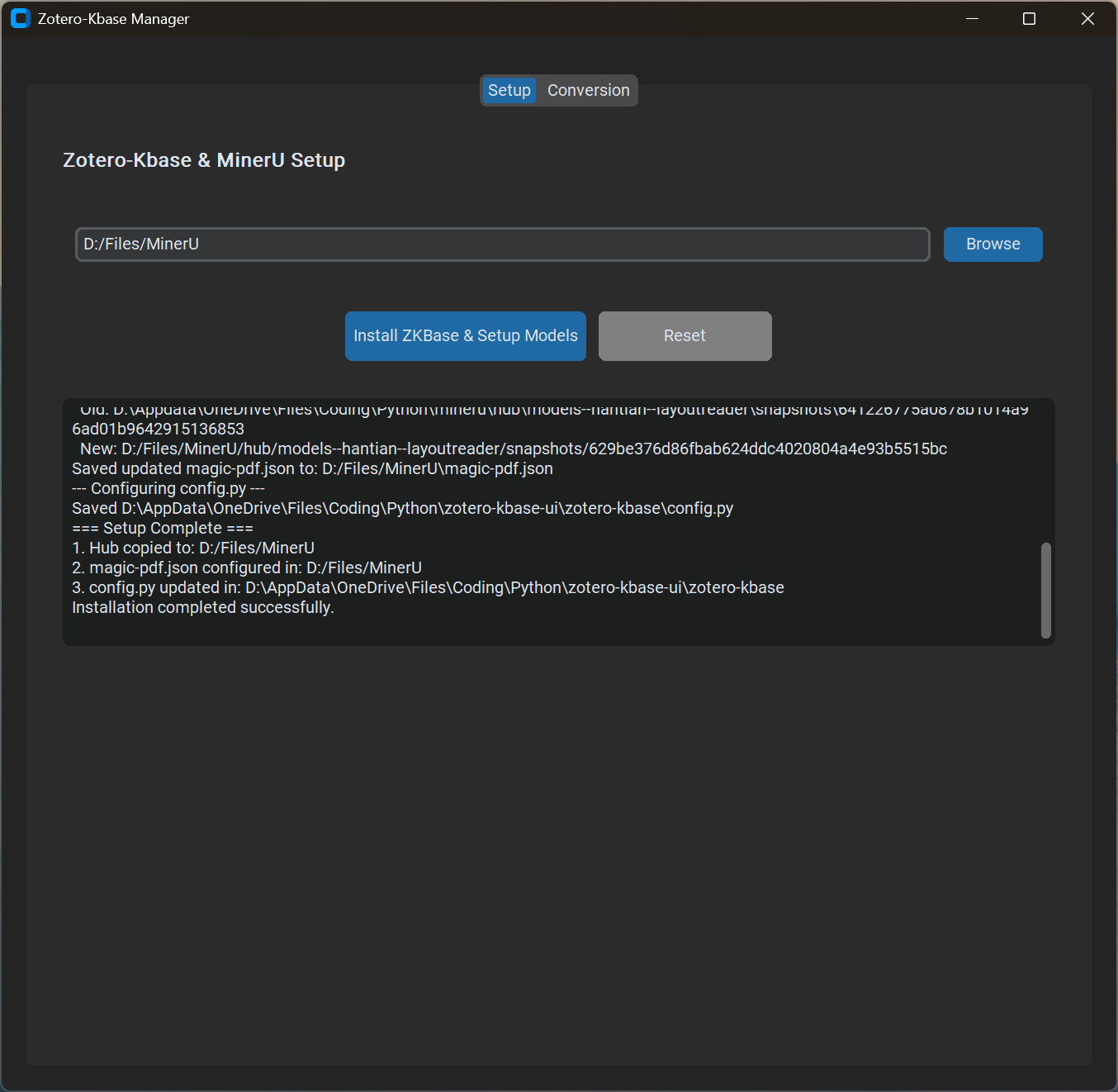
2. 操作界面
通过图形化工具 Zotero-Kbase Manager,你可以实现一键环境部署:
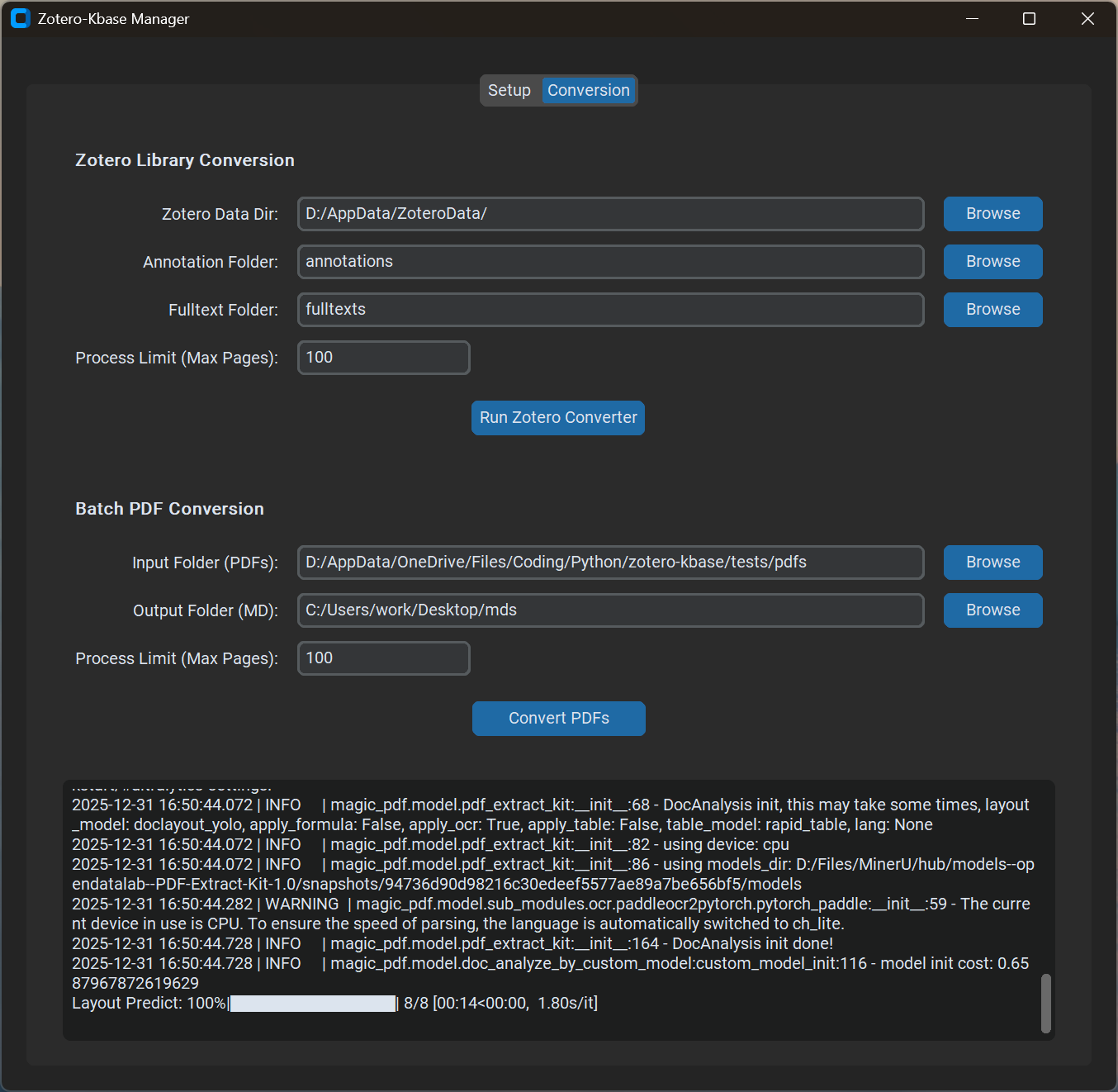
在转换阶段,你可以指定 Zotero 的数据目录,批量将 PDF 转换成干净的 Markdown 语料:
第二步:用 Cherry Studio 搭建 RAG 知识库
转换好 Markdown 后,我们需要一个强大的 RAG(检索增强生成)系统。Cherry Studio 是一款对研究者极其友好的本地 AI 客户端,能够无缝集成多种模型服务。
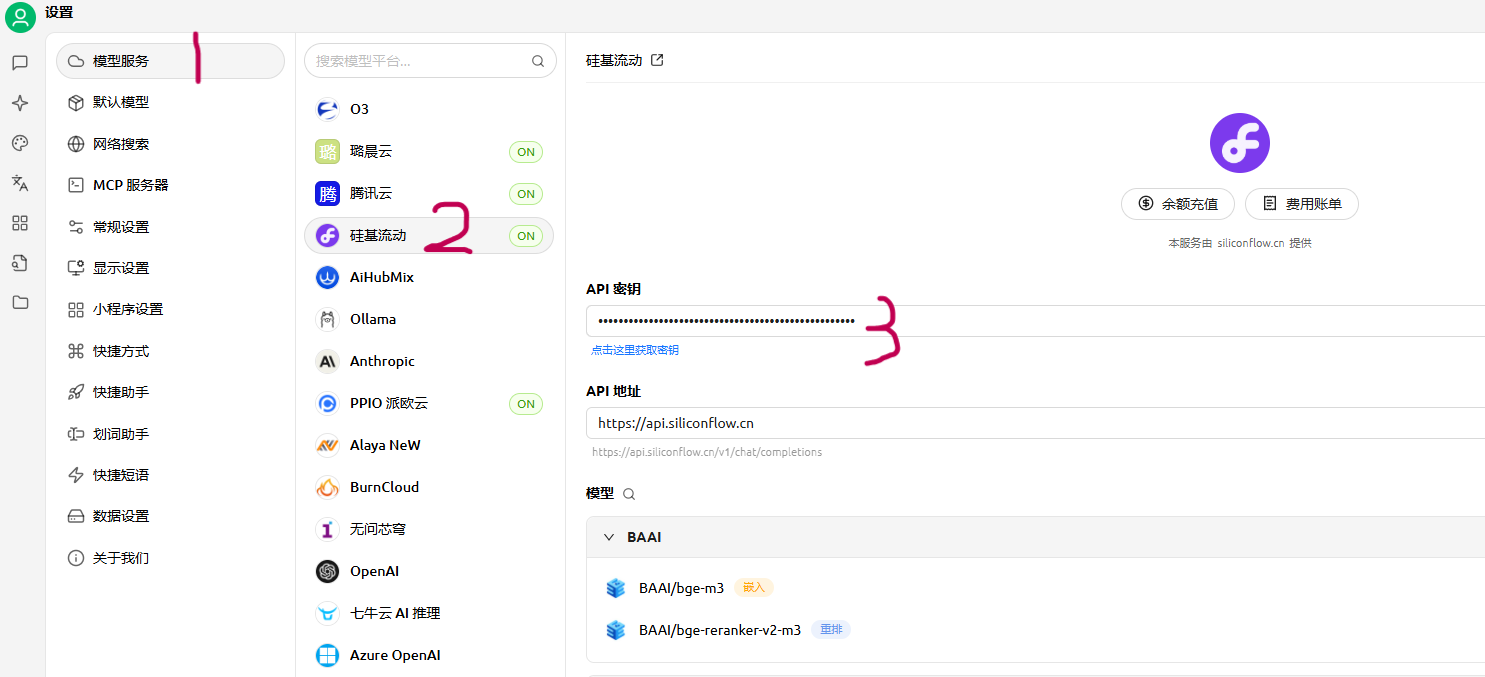
1. 配置模型服务
首先,在 Cherry Studio 中配置 API 服务(例如使用 SiliconFlow 提供的强大算力):
2. 建立科研知识库
为了实现高精度的检索,建议采用以下配置组合:
- 嵌入模型(Embedding):
BAAI/bge-m3(多语言能力强) - 重排序模型(Reranker):
BAAI/bge-reranker-v2-m3(大幅提升准确度) - 生成模型:如
DeepSeek-V3或DeepSeek-R1
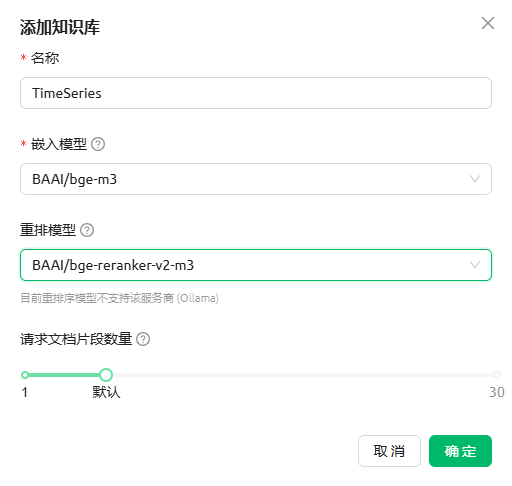
小贴士:在创建知识库时,指定好 BGE 系列模型作为“重排模型”,能有效过滤掉无关的噪声片段。
第三步:实战效果——可追溯的智能对话
完成搭建后,你就可以直接针对数百篇文献进行提问。
1. 精准的跨文献检索
相比于传统的关键字搜索,AI 可以理解你的研究意图。例如,询问“有哪些工具可以提取流域边界?”,AI 会扫描所有 Markdown 文档并给出汇总。
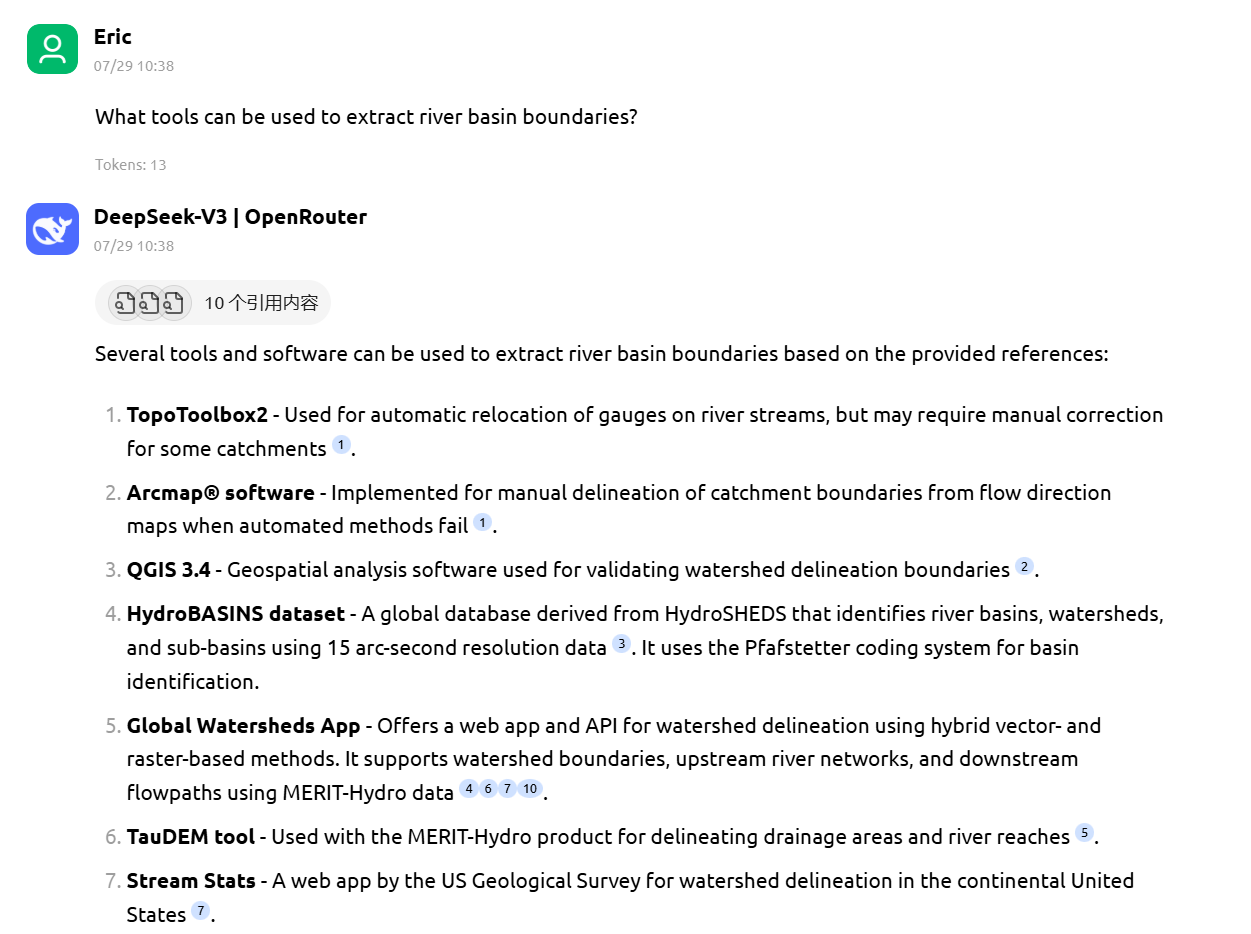
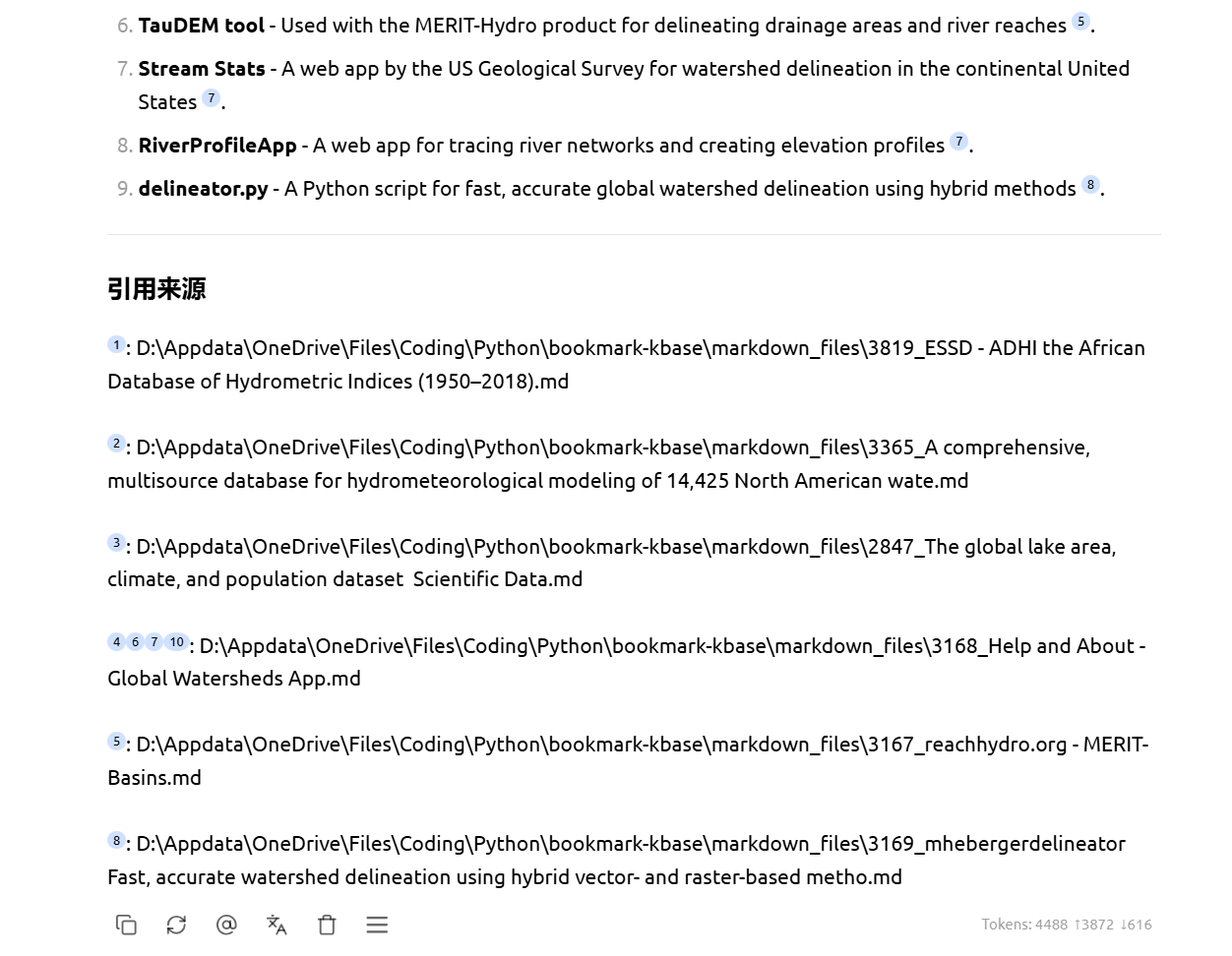
2. 严谨的引用溯源
科研写作最怕“幻觉”。这套流转方案的强大之处在于:AI 给出的每一个结论,都可以直接点击查看对应的本地 Markdown 源码位置。
总结:从文献仓库到可推理的知识系统
回顾整套流程:
- PDF → Markdown:解决“看懂”的问题。
- Markdown → RAG:保证“准确”的问题。
- Zotero → 自动化整合:解决“效率”的问题。
AI 并不会自动提升你的研究效率,但一套好的知识结构会。 这套工作流不仅是工具的堆砌,更是将“静态存档”转化为“可计算资产”的过程。如果你也深受 PDF 阅读之苦,不妨今天就开始动手搭建。
想获取文中提到的工具安装包或配置模版? 欢迎在评论区留言或私信交流。
