

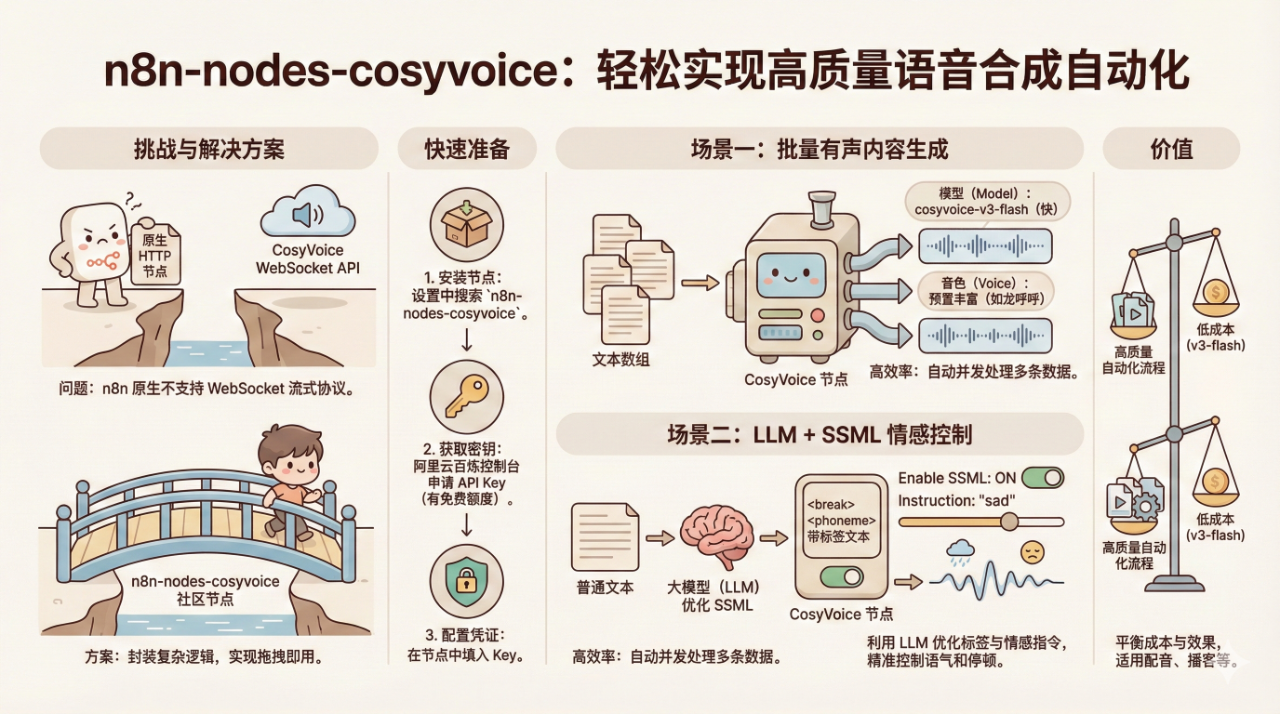
阿里开源的 CosyVoice 在语音合成领域的效果确实出色,生成的语音自然度很高。
想要在本地部署它,硬件门槛依然存在,通常需要一张显存足够的 NVIDIA 显卡,环境配置和模型下载的过程也相对繁琐。
阿里云百炼平台提供了在线版服务,无需自行部署硬件,调用 API 即可。但其接口采用 WebSocket 协议,这对 n8n 的原生支持并不友好。n8n 自带的 HTTP Request 节点主要处理 REST 接口,面对需要维持长连接并实时收发数据的 WebSocket 流,处理起来非常困难。
这种能力缺失影响了自动化的流畅度。为了解决这个问题,我开发了 n8n-nodes-cosyvoice 社区节点,将阿里云的 WebSocket 交互逻辑封装在底层,让大家可以直接通过拖拽节点来使用 CosyVoice 的能力。
下面介绍如何使用这个节点,以及如何配合大模型实现更精细的语音控制。
准备工作
使用前无需复杂的环境配置。在 n8n 的 Settings > Community Nodes 中点击安装,输入 n8n-nodes-cosyvoice 即可。
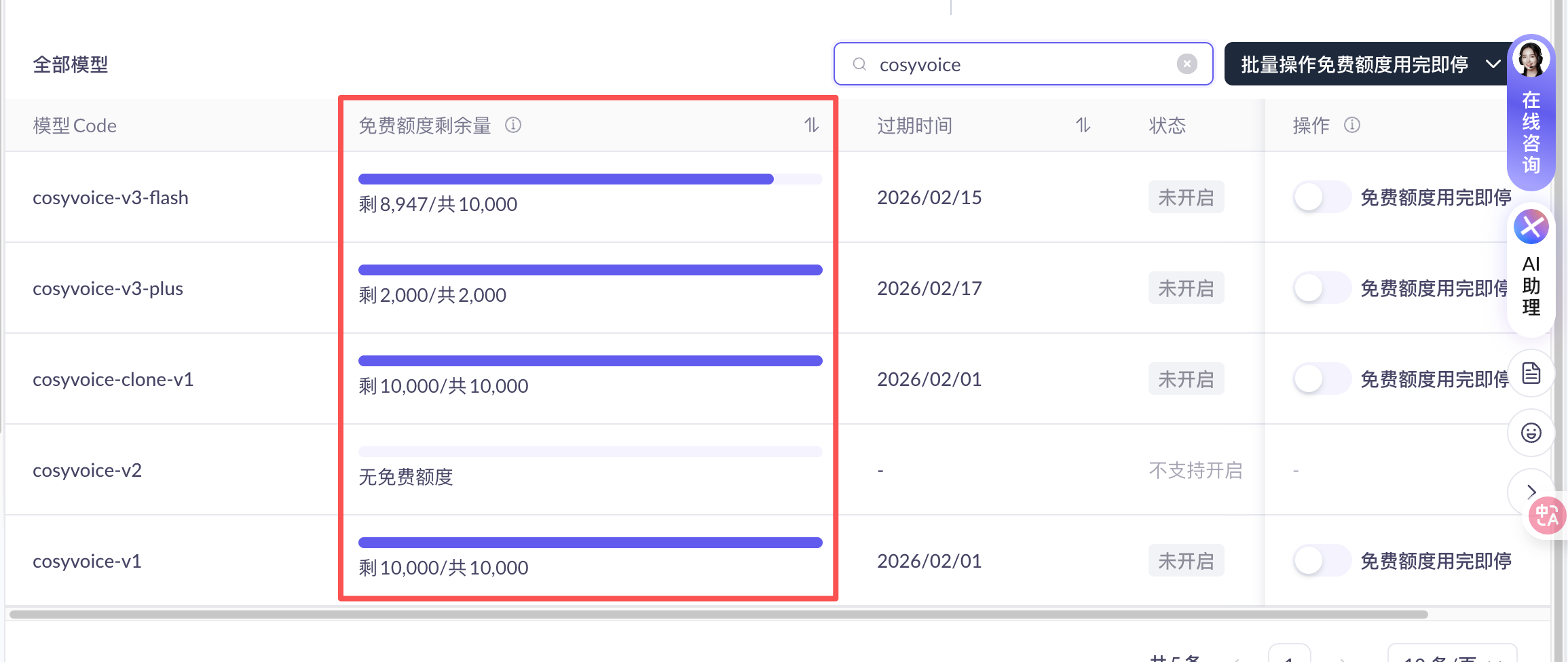
安装完成后,需要获取服务的 API Key:
- 登录阿里云百炼控制台 。
https://bailian.console.aliyun.com/?tab=model#/model-market
- 右下角找到“密钥管理”,创建一个 API Key。
目前官方提供了一定的免费额度,对于个人开发者或测试使用来说相当友好。
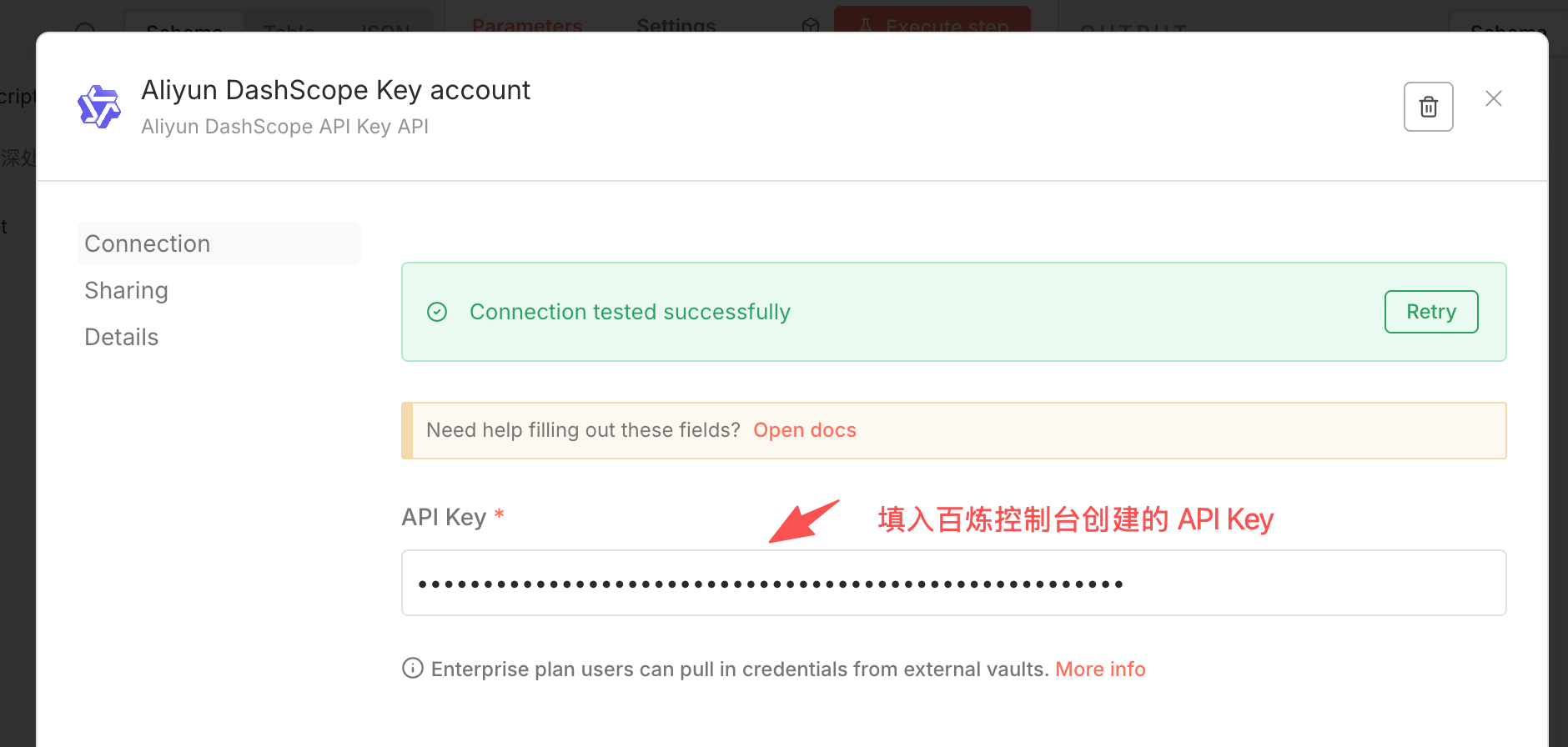
回到 n8n,搜索 CosyVoice 节点添加到画布,新建一个凭证,填入获取到的 Key 即可。
下面看看可以怎么使用这个节点。
场景一:批量生成有声内容
假设我们有一组分好段的故事文本,需要批量转换为语音文件。
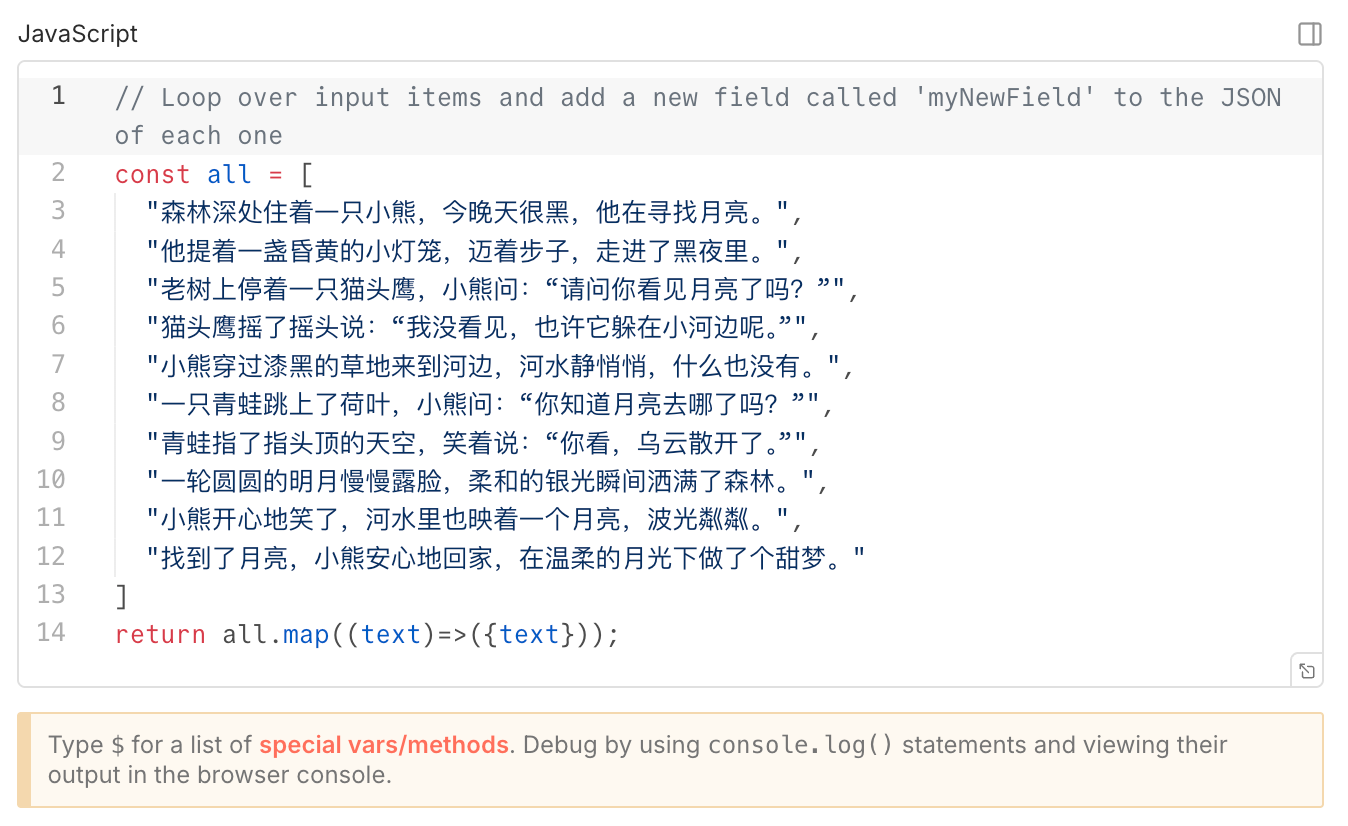
在 CosyVoice 节点中,配置逻辑如下:
- Model:推荐选择
cosyvoice-v3-flash,生成速度快,适合对延时敏感或长文本生成的场景。 - Voice:官方提供了大量高质量的预置音色,涵盖了不同年龄、性别和风格。比如
longhuhu_v3(龙呼呼)适合童话故事,也有适合新闻播报或情感讲述的音色,选择非常丰富。 - Text:直接引用上一步的文本字段。
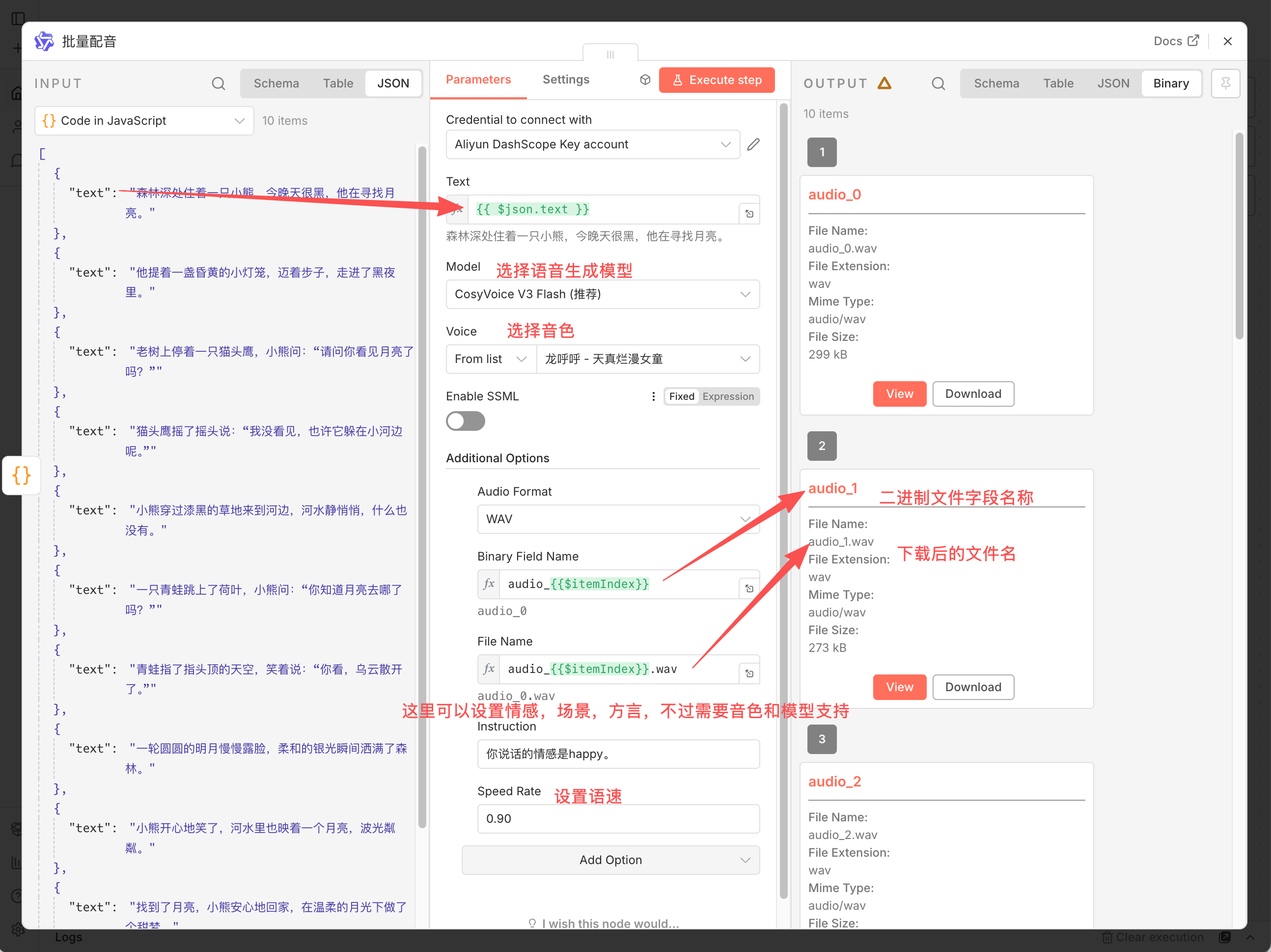
该节点针对 n8n 的运行机制进行了优化。当传入一个包含多条数据的数组时,节点会自动进行并发处理,多条语音同时生成,效率比串行生成要高很多。
场景二:结合 LLM 实现情感控制
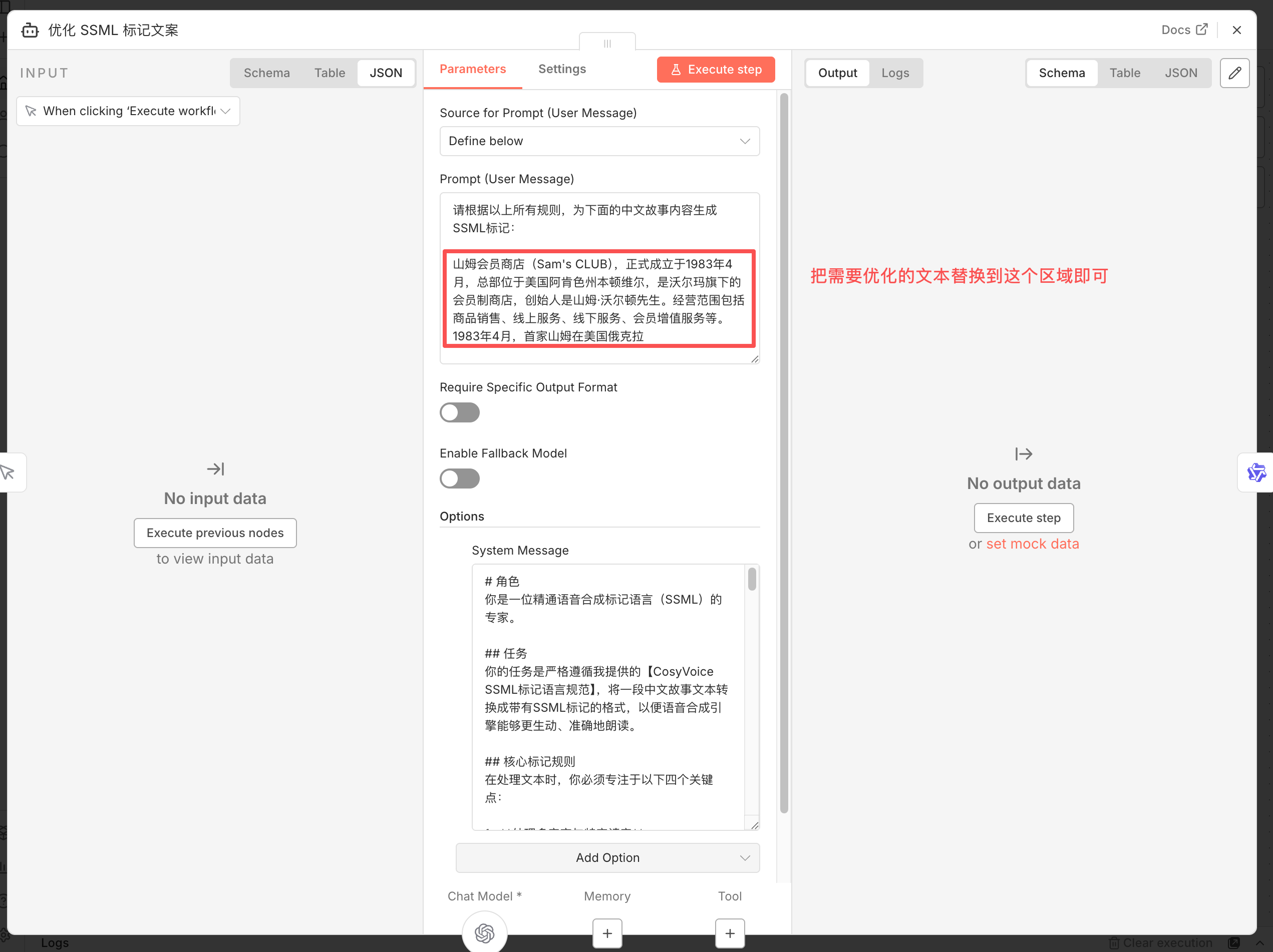
为了让语音更具表现力,比如在悲伤时放慢语速,或在开心时提高音调,我们可以利用 SSML(语音合成标记语言)。
手动编写 SSML 标签效率很低,这里可以将大模型引入工作流,让大模型根据 SSML 语法规则来优化文本,让配音更贴合场景。
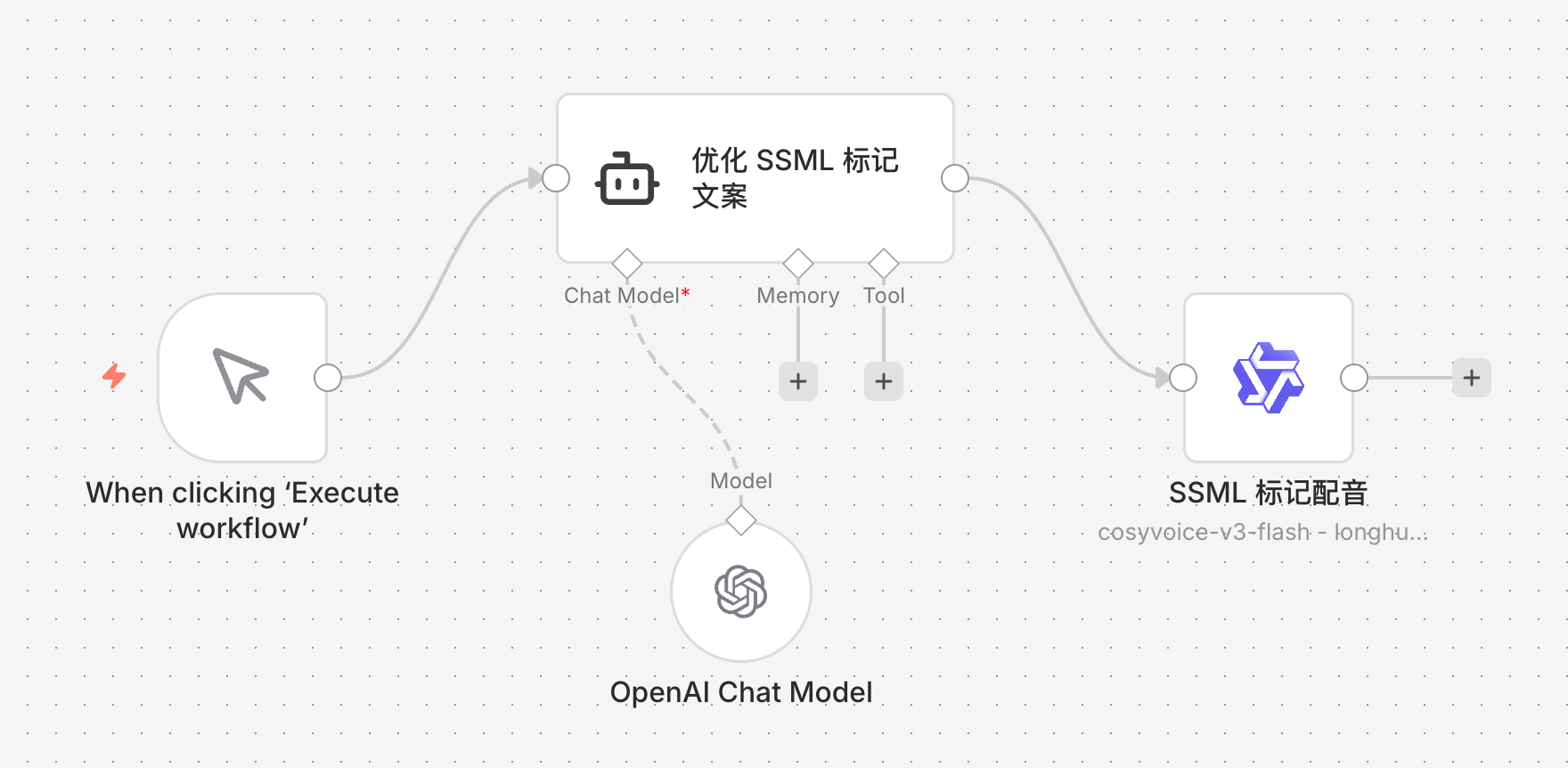
逻辑如下:
-
原始文本输入:输入一段普通文本。
-
大模型优化:编写 Prompt,让 AI 按照 SSML 规范处理文本。
- 数字处理:将阿拉伯数字转换为中文读法标签,如
<sub alias="中文读法">数字</sub>。 - 停顿控制:在需要呼吸感的位置插入
<break time="500ms"/>。 - 多音字校正:使用
<phoneme>标签指定准确读音。
- 数字处理:将阿拉伯数字转换为中文读法标签,如
-
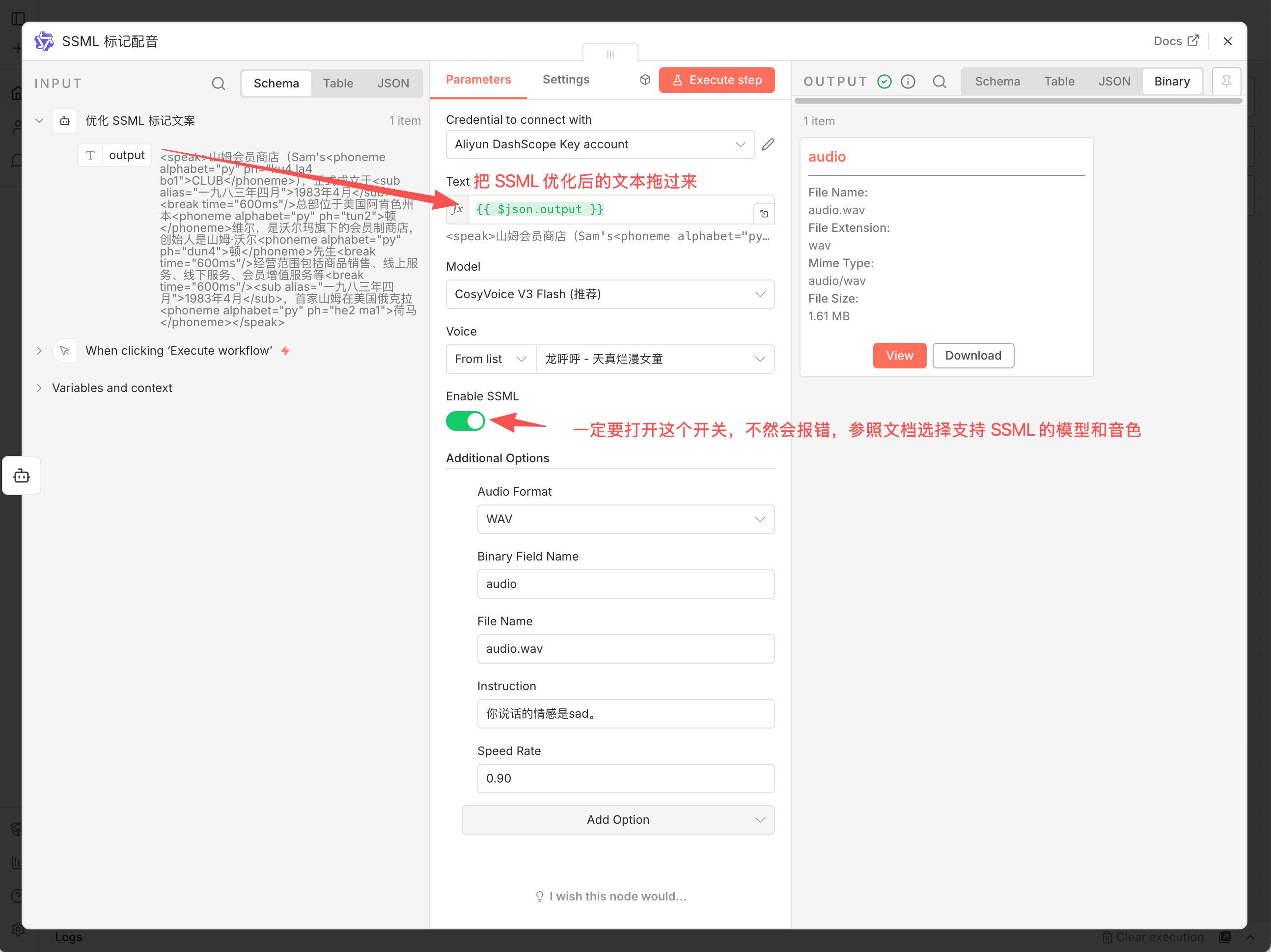
语音合成:将带有标签的文本传输给 CosyVoice 节点,并开启
Enable SSML选项。
配合节点中的 Instruction(情感指令)参数,例如设置为“你说话的情感是 sad”,合成出的语音会在语气和节奏上呈现出明显的情绪变化。
成本与价值
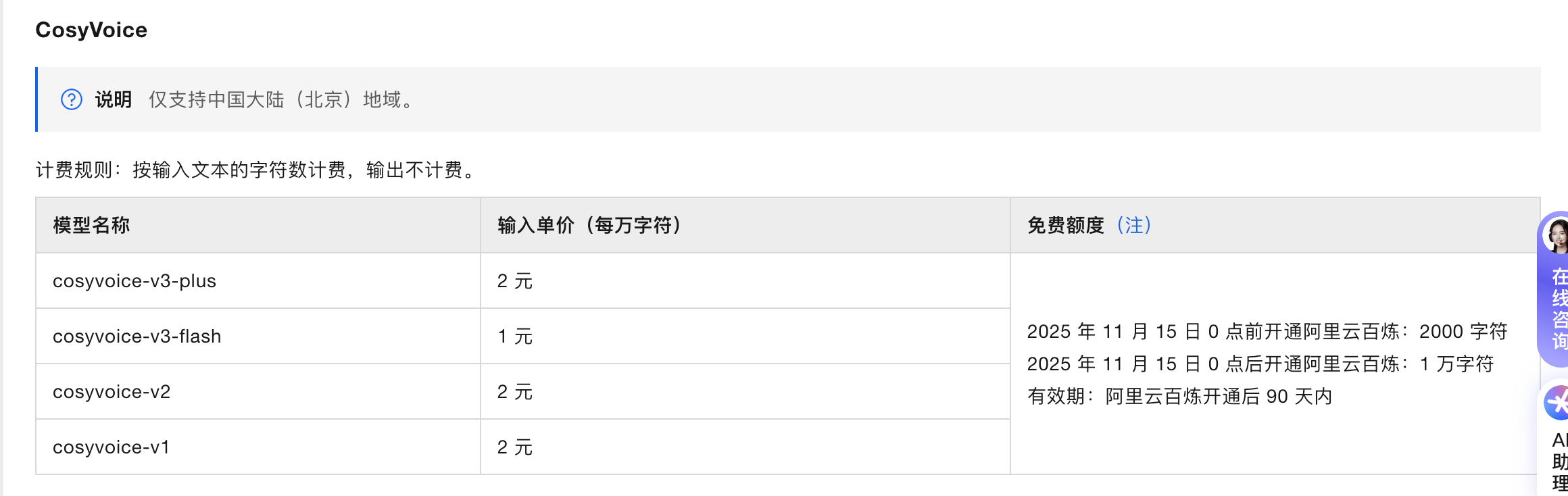
通过这个方案,我们利用阿里云 v3-flash 模型较低的计费标准,配合 n8n 的自动化能力,在本地搭建了一套高质量的音频生产流程。
无论是制作视频配音、播客内容,还是开发语音助手,这个方案都在成本和效果之间取得了不错的平衡。
文中演示的完整工作流文件,包括用于优化 SSML 的 Prompt,我已经整理完毕。
关注公众号 【曹工不加班】,后台回复 CosyVoice 即可获取。
