

💡 本文价值提示
你是否遇到过这种情况:同一个 Prompt,有时候模型回答得一本正经,有时候却胡言乱语?或者你想让模型写代码,它却给你编造了一个不存在的库?
作为从大数据转型而来的架构师,你习惯了 SQL 查询结果的“确定性”(1+1 永远等于 2)。但在 AI 的世界里,“概率”才是王道。
本文将带你深入 LLM 的“大脑皮层”,揭示控制模型输出性格的两个核心参数——Temperature 和 Top-P。掌握它们,你就能在“精准的业务逻辑”和“发散的创意生成”之间自由切换,真正驾驭模型,而不是被模型“抽奖”般的结果所困扰。
🎬 前情回顾与引入
👋 大家好!欢迎回到我们的**“大数据工程师转型 AI 架构师”**系列。
在上一篇《拆解大模型“心脏”:BERT与GPT的相爱相杀(架构师进阶指南)》中,我们学会了如何把万事万物变成向量,扔进向量数据库里做语义检索。这让我们拥有了强大的“记忆库”(RAG 的基础)。
但是,光有记忆是不够的。当模型检索到信息,准备开口说话时,它该怎么说? 是像法官一样字斟句酌?还是像脱口秀演员一样天马行空?
这就涉及到了大模型推理(Inference)阶段最关键的**“控制论”**。今天,我们要打开大模型的黑盒,调整两个决定它“性格”的旋钮。
🎲 第一部分:大模型的本质——一场“文字接龙”的赌局
在理解参数之前,我们必须先打破一个幻想:大模型其实并不“思考”,它只是在“猜”下一个字。
当你输入“今天天气真”的时候,模型内部会计算词库中所有词出现的概率分布:
- “好”:概率 70%
- “不错”:概率 20%
- “糟糕”:概率 9%
- “苹果”:概率 0.001% (完全不通顺)
模型本质上就是一个超高维度的概率预测机。
👉 架构师视角的差异:
- 传统程序:
if input == "A" return "B"(确定性)。 - 大模型:
input "A" -> P(B)=0.8, P(C)=0.2(随机性)。
那么问题来了:模型是每次都选概率最大的那个词吗? 答案是:不一定。 这完全取决于你如何设置接下来的两个参数。
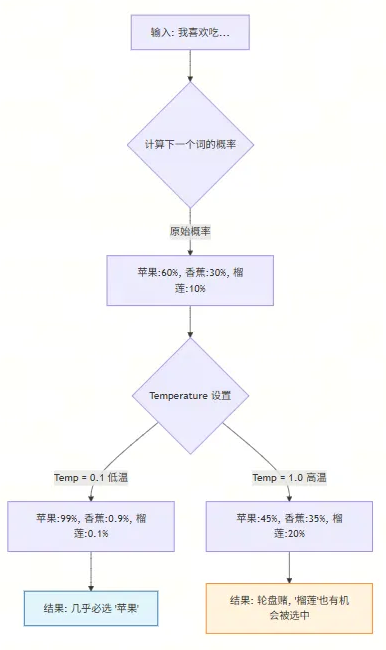
🌡️ 第二部分:Temperature(温度)——给概率分布“加热”
Temperature 是最常用的参数,通常范围在 0 到 2 之间。
1. 核心原理:冰与火之歌 🔥❄️
想象一下,模型的候选词概率是一块橡皮泥。
-
❄️ 低温 (Low Temperature, e.g., 0.1 - 0.3) :
- 效果:相当于把橡皮泥冷冻住。概率高的词(山峰)会变得更高,概率低的词(山谷)会变得更低。
- 行为:模型变得极其保守、自信、死板。它几乎只选概率最高的那个词。
- 人设:严谨的理工男、会计师、代码审查员。
-
🔥 高温 (High Temperature, e.g., 0.7 - 1.0+) :
- 效果:相当于给橡皮泥加热,它融化了,摊平了。原本概率高的词,优势不再明显;原本概率低的词,也有机会被选中。
- 行为:模型变得多样、活跃、不可预测。它可能会选一些冷门的词,带来惊喜(或惊吓)。
- 人设:浪漫的诗人、疯癫的艺术家、醉酒的聊天伴侣。
2. 流程图解:温度如何影响选择
🎯 第三部分:Top-P (Nucleus Sampling) —— 设立“VIP 门槛”
除了温度,还有一个参数叫 Top-P(通常设为 0.1 到 1.0)。很多初学者容易把它和 Temperature 搞混。
1. 核心原理:切断长尾 ✂️
如果说 Temperature 是改变概率分布的形状(变尖或变平),那么 Top-P 就是在划定候选池的范围。
Top-P = 0.9 意味着:“只在累积概率达到 90% 的前几个词里进行选择,剩下的垃圾词我看都不看。”
- 场景模拟:
- 词库里有 10000 个词。
- 前 5 个词(苹果、香蕉...)加起来概率就到了 90%。
- 如果 Top-P = 0.9,模型就只在这 5 个词里掷骰子。后面 9995 个词(比如“拖拉机”、“外星人”)直接被截断(Truncated)。
2. 为什么要用 Top-P?
它可以防止模型在高温下“彻底发疯”。即使 Temperature 很高,Top-P 也能保证模型选的词至少是“靠谱圈子”里的,避免选出概率极低、逻辑完全不通的词。
🏗️ 第四部分:架构师的决策指南——场景化配置
作为架构师,你的价值不在于知道这些参数的定义,而在于针对不同的业务场景,制定最佳的参数组合策略。
这是我为你总结的 “黄金配置表”:
| 业务场景 | 推荐 Temp | 推荐 Top-P | 理由 | 风险提示 |
|---|---|---|---|---|
| 代码生成 / SQL 转换 | 0 | 1.0 | 代码容错率极低,必须精准,不能有随机性。 | 设为 0 时,模型可能陷入重复循环。 |
| 数据提取 (JSON) | 0 - 0.1 | 1.0 | 格式必须严格,Key/Value 不能乱编。 | 同上。 |
| RAG (知识库问答) | 0.1 - 0.3 | 0.9 | 基于事实回答,需要严谨,但保留微小润色空间。 | 温度过高会导致“幻觉”,编造文档里没有的内容。 |
| 通用聊天机器人 | 0.5 - 0.7 | 0.9 | 需要像人一样自然,太死板会像复读机。 | 偶尔会一本正经地胡说八道。 |
| 创意写作 / 营销文案 | 0.8 - 1.0 | 0.8 - 0.9 | 需要脑洞,拒绝陈词滥调。 | 逻辑性可能变差,需要人工审核。 |
💡 架构师的实战心法:
- 控制幻觉 (Hallucination): 在金融、医疗等严肃场景,Temperature 必须压低。你绝对不希望 AI 帮你生成的财务报表里出现一个随机数字。
- 互斥关系: 虽然 OpenAI 文档建议“Temperature 和 Top-P 最好只调一个”,但在实际工程中,通常的做法是:固定 Top-P (如 0.9) 以保证下限,然后动态调整 Temperature 以控制上限。
- 方差测试: 如何验证你的 Prompt 是否稳定?把 Temperature 设为 0.7,连续调用 5 次。如果 5 次结果意思完全不一样,说明你的 Prompt 约束力不够,或者模型本身对该领域知识掌握不牢。
📝 实践任务:亲手“调戏”模型
不要光看,去写代码!使用 Python 调用 API 时,尝试修改这两个参数:
import openai
def get_response(prompt, temp):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=temp, # <--- 关键在这里
)
return response.choices[0].message.content
prompt = "请用三个词形容一下大数据工程师。"
# 实验 1:严谨模式
print(f"Temp=0.1: {get_response(prompt, 0.1)}")
# 输出可能是:专业、严谨、技术控 (每次运行几乎都一样)
# 实验 2:疯癫模式
print(f"Temp=1.2: {get_response(prompt, 1.2)}")
# 输出可能是:数据的驯兽师、键盘上的舞者、熬夜冠军 (每次运行都不同,甚至出现怪词)
🧠 总结:从原理到架构的思维导图
让我们用一张图来总结今天的内容,这是你作为架构师知识库中的重要拼图:
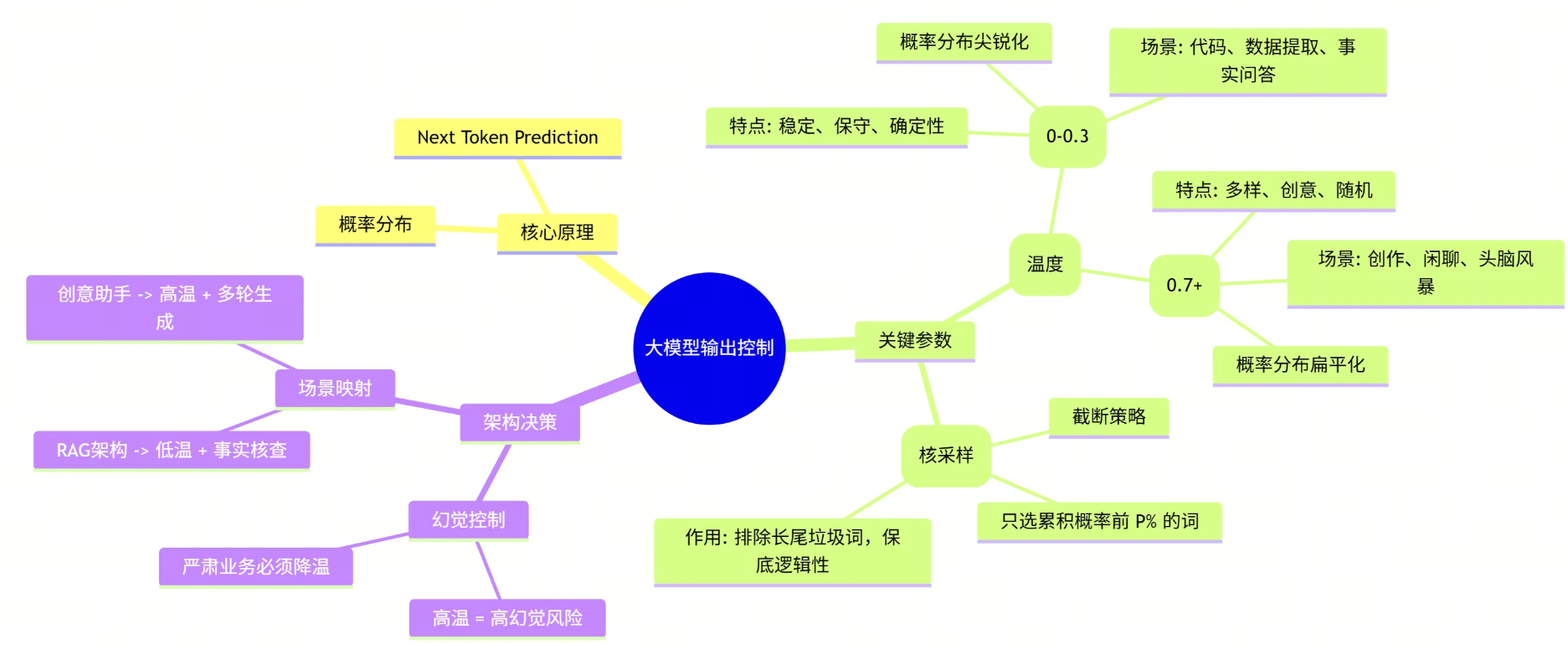
🧩 架构师的完整拼图:LLM 核心链路复盘
至此,我们已经完成了 “大模型基础理论” 这一专题的全部学习。作为架构师,当你再次审视一个 AI 应用时,不应再把它看作一个黑盒,而是一条清晰的数据流水线:
- 🧱 数据入口 (Tokenization) : 一切始于分词。它是计费的单位,也是上下文窗口的物理限制。你明白了为什么中文和英文的消耗不同,也懂得了如何在有限的窗口内“精打细算”。
- 🧠 核心引擎 (Transformer) : 这是心脏。通过 Attention 机制,模型不再是死记硬背,而是学会了“关注”上下文的关联。你了解了 Encoder(理解)与 Decoder(生成)的区别,从而能为不同的业务选择正确的模型架构。
- 🌉 语义桥梁 (Embedding) : 这是连接人类语言与机器数学的隧道。通过向量化,我们将模糊的“语义”变成了可计算的“距离”。这是你构建企业级知识库(RAG)和语义搜索的基石。
- 🎛️ 输出控制 (Temperature) : 这是最后一道阀门。通过调整概率分布,你掌握了模型的“性格”。你不再被动接受结果,而是主动权衡“精准”与“创意”,让模型在严谨的逻辑与发散的思维间自由切换。
这四个环节,构成了大模型应用的“骨架”。 掌握了它们,你就拥有了透过现象看本质的能力,不再被层出不穷的新名词迷惑,而是能从底层原理出发,设计出稳健、高效的 AI 架构。
💬 互动话题
你在使用 ChatGPT 或开发应用时,有没有遇到过因为 Temperature 设置过高而产生的“神回复”或离谱的幻觉?
欢迎在评论区分享你的“翻车现场”,让我们一起看看 AI 喝醉了是什么样子!👇👇👇
