

本文价值提示: 很多转型AI的大数据工程师,会调用 API,会写 Prompt,但一旦遇到“为什么这个任务跑得这么慢?”或者“为什么提取实体总是出错?”时就懵了。 本文不讲复杂的数学公式,而是用架构师的视角,带你钻进大模型的“黑盒”内部,看懂 Transformer 的三种形态,并附赠一份2025年主流模型选型清单(含国产之光)。
👋 大家好,我是你们的老朋友。
在上一期的《AI 计费的秘密:为什么你的 Prompt 越写越贵?》中,我们搞懂了模型是如何“吃”数据的。很多同学在后台留言:“数据吃进去了,然后在里面到底发生了什么?市面上模型几百个,LLaMA、Qwen、BERT 到底该选谁?”
今天,我们就进入大模型基础理论专题的第二站:核心引擎——Transformer 架构。
如果说 Python 工程化是你手中的“瑞士军刀”,那么 Transformer 架构原理就是你心中的“内功心法”。作为未来的 AI 架构师,你不需要推导反向传播公式,但你必须知道:这台引擎的三个档位(Encoder, Decoder, Encoder-Decoder)分别适合跑什么路况,以及对应的代表车型是谁。
01 💡 灵魂机制:Attention(注意力)
—— 模型是如何“懂”你的?
在 Transformer 出现之前,老一代的 NLP 模型(如 RNN)像是一个记性不好的阅读者,读到句子末尾时,往往忘了开头讲什么。
而 Transformer 的核心武器是 Self-Attention(自注意力机制)。
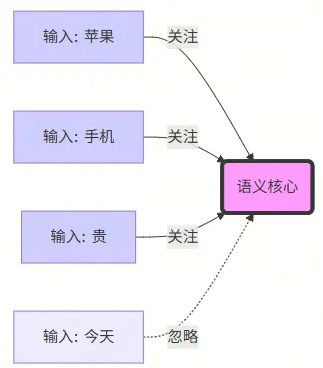
🌰 这是一个通俗的比喻:
想象你在读这行字:“苹果公司今天发布了新手机,它真贵。”
当你读到“贵”这个字时,你的大脑会自动把注意力聚焦在前面的“手机”和“苹果”上,而不是“今天”或“发布”。
这就是 Attention。它让模型在生成或理解每一个 Token 时,都会 “回头看一看” 上下文中的其他 Token,并计算出它们之间的关联强度(权重)。
02 ⚔️ 华山论剑:三大家族与主流模型
—— 并不是所有模型都叫 GPT
Transformer 架构虽然统一了江湖,但根据对 Attention 的使用方式不同,分化出了三大流派。作为架构师,选对流派,成本能省 90%,效果能提升 50%。
1. 🧐 严谨的理解者:Encoder-only (BERT 家族)
- 核心特点:双向注意力。它能同时看到“过去”和“未来”,拥有上帝视角。
- 比喻:完形填空高手。擅长做阅读理解,但不擅长说话。
- 架构师必知代表模型 :
- 🌍 BERT (Google) :鼻祖级模型,工业界微调任务的基石。
- 🇨🇳 RoBERTa-wwm (哈工大讯飞) :针对中文优化的 BERT,中文理解任务的首选。
- 🇨🇳 BGE / M3 (BAAI 智源) :重点关注! 目前 RAG(检索增强生成)架构中,用于将文本转为向量(Embedding)的最强开源模型之一。
- 适用场景:文本分类(情感分析)、实体抽取(NER)、RAG 系统的向量检索。
2. 🗣️ 奔放的创作者:Decoder-only (GPT 家族)
- 核心特点:单向注意力。只能看到“过去”,永远看不见“未来”,走一步看一步。
- 比喻:即兴演讲大师。目前最火的大模型(LLM)基本都属于这一派。
- 架构师必知代表模型:
- 🌍 GPT-4 / GPT-4o (OpenAI) :目前的战力天花板,逻辑推理和多模态能力的标杆。
- 🌍 LLaMA 3 (Meta) :开源界的盟主,大多数私有化部署模型的基座。
- 🇨🇳 Qwen 通义千问 (Alibaba) :中文能力极强,生态完善,Qwen-72B/7B 是国产开源的佼佼者。
- 🇨🇳 DeepSeek 深度求索: 在代码生成和数学推理上表现惊人,且 API 价格极具破坏力。
- 🇨🇳 ChatGLM (智谱 AI) :国内最早跑通消费级显卡(int4 量化)的模型,微调生态非常成熟。
- 适用场景:文本生成、对话系统、创意写作、代码补全、逻辑推理。
3. 🔄 全能的翻译官:Encoder-Decoder (Seq2Seq 家族)
- 核心特点:左手理解(Encoder),右手生成(Decoder)。
- 比喻:同声传译员。
- 架构师必知代表模型:
- 🌍 T5 (Google) :Text-to-Text Transfer Transformer,万金油模型。
- 🌍 BART (Facebook) :擅长文本摘要。
- 现状:在通用大模型领域,Decoder-only 逐渐占据了统治地位,但在机器翻译和特定格式摘要任务中,T5 依然有一席之地。
03 🏗️ 架构师视角:选型与瓶颈
—— 别让你的系统卡在“生成”上
作为从大数据转型来的架构师,你可能习惯了 MapReduce 的并行处理思维。但在 LLM 时代,你必须面对一个新的物理约束。
🛑 核心瓶颈:推理延迟 (Inference Latency)
请记住这个公式:
Decoder 生成耗时 ≈ Token 数量 × 单个 Token 生成时间
GPT/Qwen 这类模型的生成是串行的。 它必须先生成第 1 个字,才能生成第 2 个字。如果一个字耗时 50ms,1000 个字就是 50 秒。这是物理硬伤,堆 GPU 也只能缓解,无法消除。
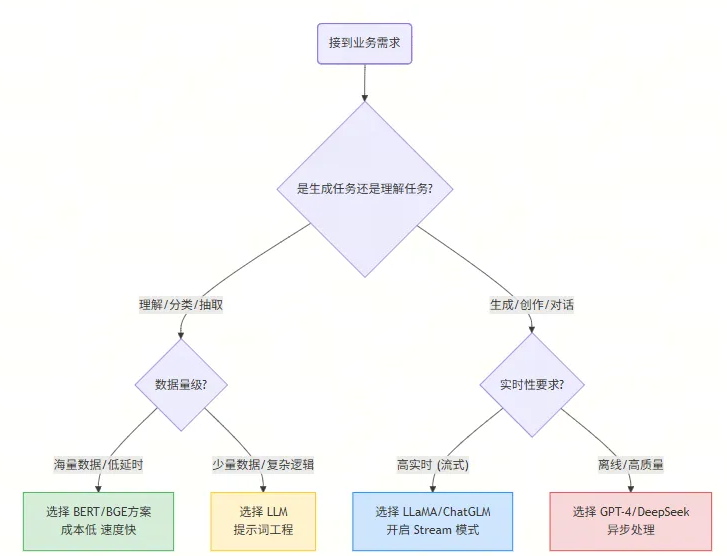
⚖️ 选型决策实战
假设你现在要为公司设计一个 “电商评论分析系统” ,老板有两个需求:
- 需求 A:从 100 万条评论中,找出所有抱怨“物流慢”的评论。
- 需求 B:针对用户的差评,自动写一段安抚回复。
❌ 错误的架构(全用 GPT-4):
- 用 GPT-4 扫描 100 万条评论做分类。
- 后果:Token 费用爆炸,处理时间可能需要几天。
✅ 正确的架构(组合拳):
- 针对需求 A(理解任务):使用 BGE 做向量检索,或者微调一个 RoBERTa 小模型。
- 理由:BERT 类模型处理速度极快,可并行,成本几乎为零。
- 针对需求 B(生成任务):调用 Qwen-Max 或 DeepSeek 接口。
- 理由:只有 Decoder 架构才能写出有人情味的回复。
👇 架构选型决策流程图:
04 🛠️ 总结与下一步
今天我们拆解了大模型的“心脏”。作为架构师,你不需要去训练一个 Transformer,但你必须深刻理解 Encoder(理解) 和 Decoder(生成) 的区别。
- Encoder (BERT/BGE) 是你手里精准的手术刀,适合做分析、提取、搜索。
- Decoder (GPT/Qwen) 是你手里万能的画笔,适合做创作、对话、交互。
未来的 AI 应用架构,往往是 “小模型(BERT/Embedding)做路由和检索” + “大模型(GPT)做总结和生成” 的混合架构。这正是我们大数据工程师发挥架构整合能力的最佳战场!
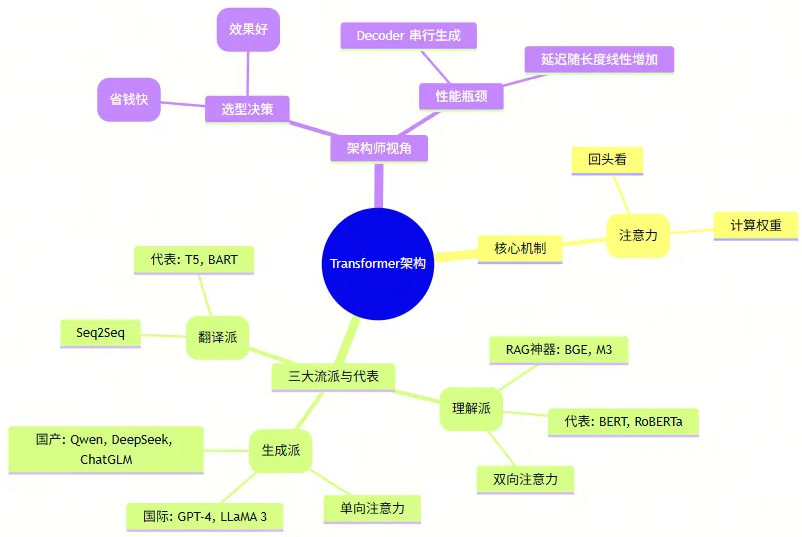
🧠 本文思维导图总结
📢 下期预告
搞懂了“心脏”和“选型”,下一期我们将进入连接大数据与 AI 的最关键桥梁,也是 RAG(检索增强生成)的基石——Embedding(向量化)。
👉 互动话题: 国产模型百花齐放,Qwen、DeepSeek、ChatGLM,你在实际业务中更看好哪一个?或者你踩过哪些坑?欢迎在评论区分享你的“实战经验”!
这是【大模型基础理论】专题的第二篇。如果你错过了第一篇《Python 高级工程化》,欢迎点击历史消息查看。让我们一起,从大数据工程师蜕变为 AI 架构师!
