

【本文价值提示】
作为一个拥有大数据背景的工程师,你可能习惯了按 GB、TB 甚至 PB 来衡量数据。但在大模型(LLM)的世界里,计量单位变了——变成了 Token。
这不仅仅是一个计费单位,它是大模型理解世界的“原子”,是架构设计的“硬约束”,更是导致模型“算术不好”的罪魁祸首。
本文是 “从大数据工程师到 AI 架构师” 系列教程的第一篇。我们将揭开大模型黑盒的第一层面纱,带你从架构师的视角,重新理解数据的入口。
大家好,我是你们的转型领路人。
很多刚开始接触大模型(LLM)的朋友,在调用 OpenAI 或 Claude 的 API 时,往往会产生一种错觉: “我发给模型的是一句话,模型读懂了这句话,然后回了我一句话。”
错!大错特错。
在 AI 的眼里,根本没有“字”或“单词”的概念,只有一串串冷冰冰的数字。如果你不理解这一点,你设计的 AI 应用不仅会性能低下,还会让公司的API 账单爆炸,甚至会出现一些让你摸不着头脑的逻辑错误。
今天,我们就来聊聊大模型数据流转的第一站:Tokenization(分词)。
01 什么是 Token?AI 的“精神食粮” 🍔
在大数据处理中,我们习惯把文本看作 String 或 Bytes。但在 LLM 中,文本在进入模型之前,必须被切碎。
Token(词元) 就是模型能消化的最小单位。
你可以把大模型想象成一个**“挑食的吃货”**。你给它一整块牛排(一句话),它吃不下去。你必须用刀叉(Tokenizer)把牛排切成一小块一小块(Tokens),它才能一口一口吃掉。
这里的关键认知差在于:
- 人类视角:
I love AI是 3 个单词。 - 机器视角:这可能是 3 个 Token,也可能是 4 个,取决于你怎么切。
📝 架构师的速记公式:
- 中文场景:1 个汉字 ≈ 1 个 Token(大部分情况下)。
- 英文场景:1 个单词 ≈ 1.3 个 Token(因为复杂的词会被拆开)。
⚠️ 警钟长鸣: 很多初级工程师在做成本预估时,直接用“字符数”去乘价格,结果月底账单出来发现比预估高了 30%~50%。这就是不懂 Token 转换率的代价。
02 BPE:统计学上的“暴力压缩” 🗜️
你可能会问:“为什么要切分?直接用 Unicode 编码或者按单词切不行吗?”
这就涉及到了 Tokenization 的核心算法——BPE (Byte Pair Encoding) 。
作为大数据工程师,你对“压缩算法”一定不陌生。BPE 其实就是一种基于统计学的文本压缩。它的逻辑非常简单粗暴:
- 高频出现的字符组合:合并成一个独立的 Token(比如
ing、tion、the)。 - 低频出现的字符组合:拆分成多个 Token。
举个栗子 🌰
假设我们要处理单词 "Unhappiness":
- 如果是生僻词,模型可能没见过。
- BPE 会把它拆解为:
Un(前缀) +happi(词根) +ness(后缀)。
这样一来,模型即使没见过 "Unhappiness",但它学过这三个部分,就能猜出意思是“不快乐”。
📉 流程图解:文本是如何变成数字的
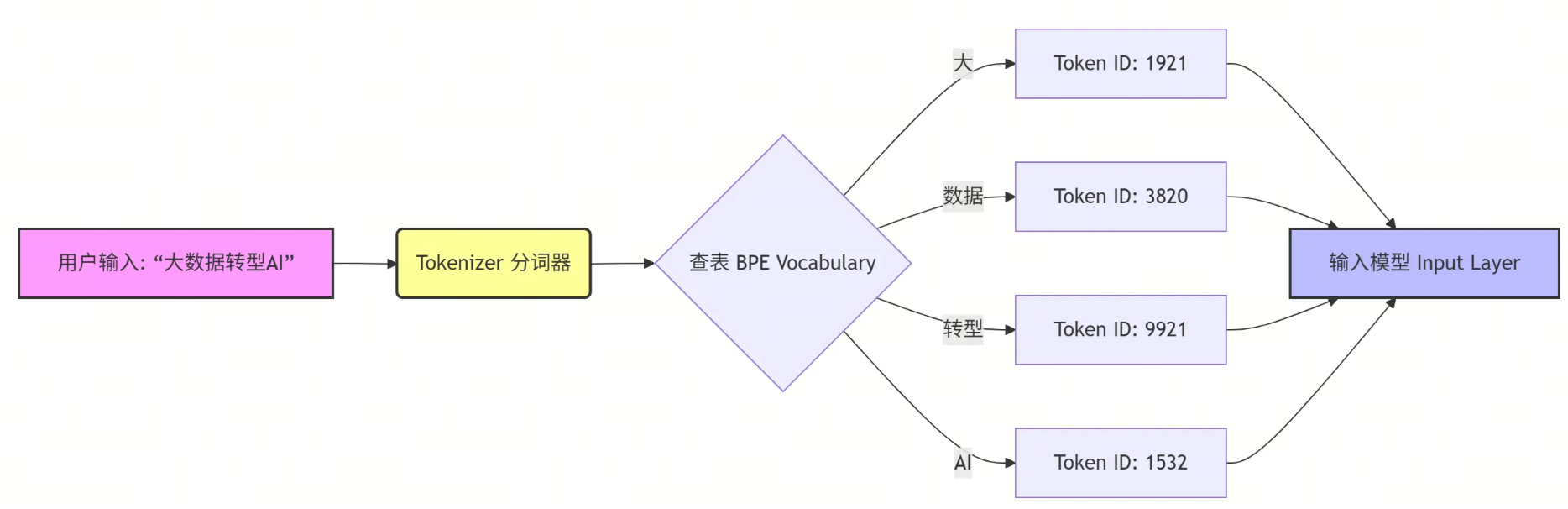
03 架构师的噩梦:数字与代码的“失语症” 😵💫
理解了 BPE,你就能解释一个困扰无数人的玄学问题: “为什么 ChatGPT 这种超级大脑,做三位数的加减法经常算错?”
原因不在于模型笨,而在于 Tokenization 把它坑了。
在 BPE 算法下,数字的切分非常诡异。
1000可能是一个 Token。1,000可能是两个 Token (1和,000)。1001可能是两个 Token (10和01)。
👀 想象一下: 你要教一个孩子学数学,但你禁止他看数字本身,而是告诉他:“苹果 + 香蕉 = 梨”。这孩子能学会才怪!
因为数字被切分得支离破碎,破坏了数位(个十百千)的逻辑,导致模型在处理算术、哈希值、甚至某些代码缩进时,表现得像个“智障”。
🛠️ 架构决策点: 如果你的业务场景涉及精确的数学计算或复杂的 ID 匹配,千万不要完全依赖 LLM 的推理。 正确做法:使用 Tool Use(工具调用),让 LLM 写 Python 代码去算,或者调用计算器 API。
04 核心硬约束:Context Window(上下文窗口) 🪟
做大数据架构,我们习惯了横向扩展(Scale-out)。数据多了?加机器!
但在 LLM 的世界里,有一个目前无法物理突破的硬约束:Context Window。
每个模型都有最大窗口限制(例如 GPT-4 是 128k,Llama 2 是 4k)。这个窗口大小 = 输入 Token + 输出 Token。
这就好比你有一个工作台:
- 你把参考资料(Prompt + RAG 检索到的文档)堆在桌上。
- 你还要留出空间写答案(Output)。
- 如果桌子满了,你要么扔掉旧资料(截断),要么就写不出答案(报错)。
💡 架构师的思考:
在设计 RAG(检索增强生成) 系统时,你检索出的文档往往有几万字。
- 全部塞进去? 窗口爆了,或者费用爆了。
- 只塞一部分? 丢弃哪部分?头部?尾部?还是中间?
这是一个典型的 “空间换质量” 的博弈。你需要根据 Token 数量,动态计算能塞入多少条知识库内容。
05 实战演练:用 Python 看看 Token 的真面目 🐍
光说不练假把式。作为工程师,我们直接上代码。我们将使用 OpenAI 官方的 tiktoken 库来直观感受一下。
import tiktoken
# 加载 GPT-4 的编码器
enc = tiktoken.get_encoding("cl100k_base")
# 实验文本:中英混合 + 数字
text = "AI架构师 2025 transformation"
# 编码
tokens = enc.encode(text)
print(f"原文: {text}")
print(f"Token IDs: {tokens}")
print(f"Token 数量: {len(tokens)}")
# 解码回来看每个 Token 对应什么
print("-" * 20)
for t in tokens:
print(f"ID: {t} -> '{enc.decode([t])}'")
运行结果预演:
你会发现 AI 可能是一个 Token,架构师 被拆成了几个 Token,而 transformation 作为一个常见英文词,可能只是一个 Token。
这就是为什么同样的语义,英文 Prompt 通常比中文 Prompt 更省钱、处理速度更快的原因。
06 总结:架构师的知识图谱 🗺️
恭喜你,完成了从大数据向 AI 架构转型的第一步!
现在,当你再看 LLM 的输入框时,你不应该只看到文本,而应该看到流动的 Token、潜在的计费点以及窗口的约束。
让我们用一张思维导图总结今天的核心内容:
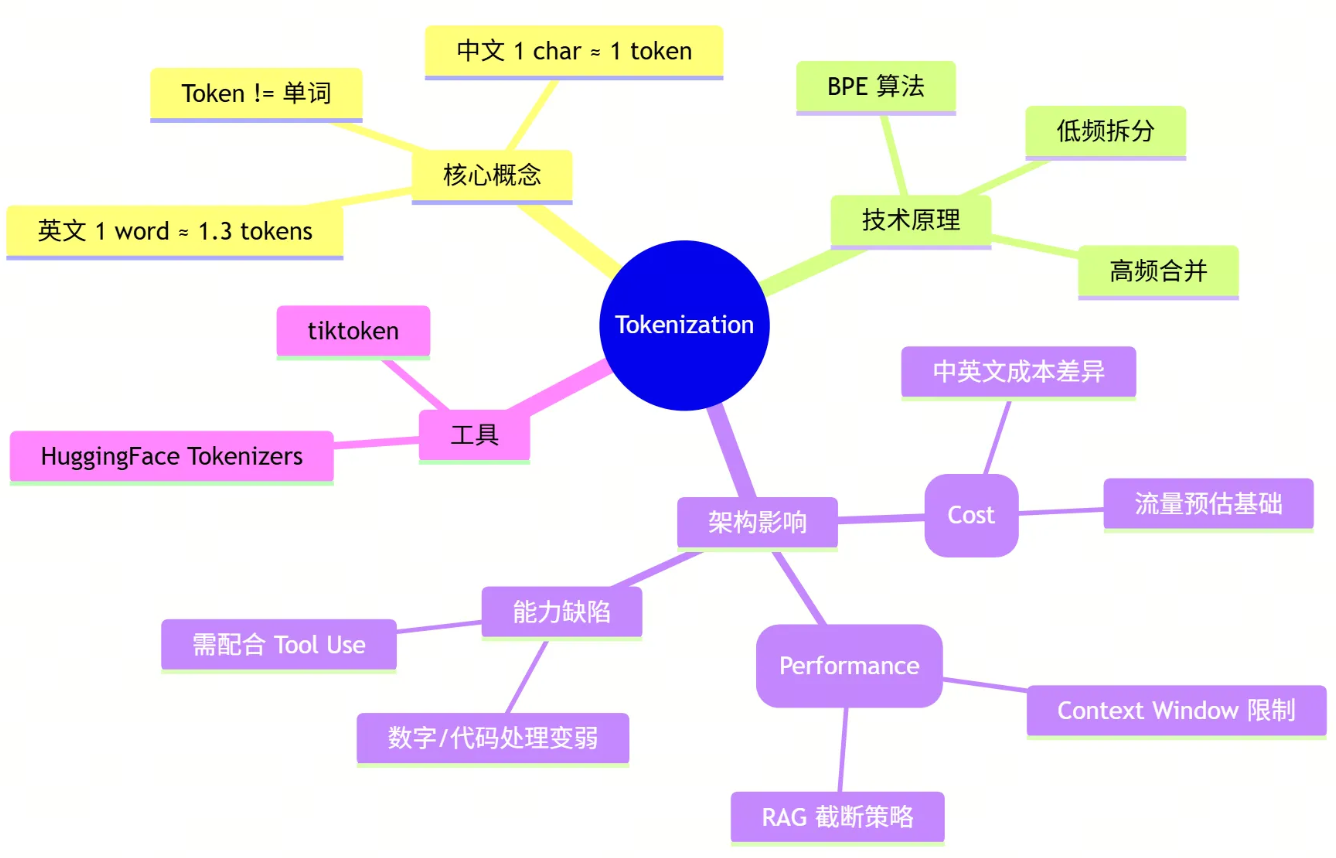
🔜 下期预告
搞懂了数据如何“进入”模型,下一期我们将深入模型的心脏。
为什么有的模型只能做阅读理解(BERT),有的却能吟诗作对(GPT)? 第二阶段:核心引擎——Transformer 架构解析。我们将剖析 Encoder 与 Decoder 的爱恨情仇,教你如何根据业务场景进行模型选型。
👇 互动话题: 你在使用大模型 API 时,有没有遇到过因为 Token 超长被截断,或者数学算错的坑?欢迎在评论区分享你的“血泪史”!
喜欢这篇文章吗?点赞、在看、转发,是更新的最大动力! 🚀
