

题目 1:医院门诊数据分析
“医院门诊数据.csv” 包含字段:“就诊编号”“就诊日期”“科室 (内科 / 外科 / 儿科 / 妇科 / 骨科)”“患者年龄”“性别”“诊疗费用 (元)”“药品费用 (元)”“是否医保报销 (是 / 否)”。
请使用 pandas、numpy 和 matplotlib 完成以下任务:
- 读取 CSV 文件数据,判断是否为高费用就诊(诊疗费用 + 药品费用 ≥ 500 元),添加 “是否高费用” 列(是 / 否)。
- 按 “科室” 和 “年龄分组”(0-18、19-40、41-60、60+)双重分组,统计每组的高费用就诊比例。
- 计算诊疗费用与药品费用的相关系数。
- 按是否医保报销分组,统计诊疗费用、药品费用的均值和方差(使用 agg 函数)。
- 绘制不同科室的平均总费用(诊疗 + 药品)对比柱状图。
分解代码:
请使用 pandas、numpy 和 matplotlib 完成以下任务:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
1. 读取 CSV 文件数据,判断是否为高费用就诊(诊疗费用 + 药品费用 ≥ 500 元),添加 “是否高费用” 列(是 / 否)。
df = pd.read_csv("医院门诊数据.csv")
df['总费用'] = df['诊疗费用 (元)'] + df['药品费用 (元)']
df['是否高费用'] = np.where(df['总费用'] >= 500, '是', '否')
print(df)
运行结果:
2. 按 “科室” 和 “年龄分组”(0-18、19-40、41-60、60+)双重分组,统计每组的高费用就诊比例。
def age_group(age):
if 0 <= age <= 18:
return "0-18"
elif 19 <= age <= 40:
return "19-40"
elif 41 <= age <= 60:
return "41-60"
else:
return "60+"
df['年龄分组'] = df['患者年龄'].apply(age_group)
print(df)
df_states = df.groupby(['科室', '年龄分组']).agg(
总就诊数=('就诊编号', 'count'),
高费用就诊数=('是否高费用', lambda x:(x=='是').sum())
)
print(df_states)
# 高费用就诊比例
ratio = df_states['高费用就诊数'] / df_states['总就诊数']
print(ratio)
3. 计算诊疗费用与药品费用的相关系数。
corr = df['诊疗费用 (元)'].corr(df['药品费用 (元)'])
print(corr)
运行结果:
4. 按是否医保报销分组,统计诊疗费用、药品费用的均值和方差(使用 agg 函数)。
states = df.groupby("是否医保报销").agg(
诊疗费用均值=('诊疗费用 (元)', 'mean'),
诊疗费用方差=('诊疗费用 (元)', 'var'),
药品费用均值=('药品费用 (元)', 'mean'),
药品费用方差=('药品费用 (元)', 'var')
)
print(states)
运行结果:
5. 绘制不同科室的平均总费用(诊疗 + 药品)对比柱状图。
total_sales = df.groupby('科室')['总费用'].sum()
print(total_sales)
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.bar(total_sales.index, total_sales)
plt.show()
运行结果:
完整代码:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 1. 读取 CSV 文件数据,判断是否为高费用就诊(诊疗费用 + 药品费用 ≥ 500 元),添加 “是否高费用” 列(是 / 否)。
df = pd.read_csv("医院门诊数据.csv")
df['总费用'] = df['诊疗费用 (元)'] + df['药品费用 (元)']
df['是否高费用'] = np.where(df['总费用'] >= 500, '是', '否')
print(df)
# 2. 按 “科室” 和 “年龄分组”(0-18、19-40、41-60、60+)双重分组,统计每组的高费用就诊比例。
def age_group(age):
if 0 <= age <= 18:
return "0-18"
elif 19 <= age <= 40:
return "19-40"
elif 41 <= age <= 60:
return "41-60"
else:
return "60+"
df['年龄分组'] = df['患者年龄'].apply(age_group)
print(df)
df_states = df.groupby(['科室', '年龄分组']).agg(
总就诊数=('就诊编号', 'count'),
高费用就诊数=('是否高费用', lambda x:(x=='是').sum())
)
print(df_states)
# 高费用就诊比例
ratio = df_states['高费用就诊数'] / df_states['总就诊数']
print(ratio)
# 3. 计算诊疗费用与药品费用的相关系数。
corr = df['诊疗费用 (元)'].corr(df['药品费用 (元)'])
print(corr)
# 4. 按是否医保报销分组,统计诊疗费用、药品费用的均值和方差(使用 agg 函数)。
states = df.groupby("是否医保报销").agg(
诊疗费用均值=('诊疗费用 (元)', 'mean'),
诊疗费用方差=('诊疗费用 (元)', 'var'),
药品费用均值=('药品费用 (元)', 'mean'),
药品费用方差=('药品费用 (元)', 'var')
)
print(states)
# 5. 绘制不同科室的平均总费用(诊疗 + 药品)对比柱状图。
total_sales = df.groupby('科室')['总费用'].sum()
print(total_sales)
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.bar(total_sales.index, total_sales)
plt.show()
题目 2:短视频平台用户行为数据分析
“短视频行为数据.csv” 包含字段:“用户 ID”“观看日期”“视频类型 (搞笑 / 剧情 / 科普 / 美妆 / 游戏)”“观看时长 (秒)”“点赞数”“评论数”“分享数”“是否关注作者 (是 / 否)”。
请使用 pandas 和 matplotlib 完成以下任务: 1. 读取 CSV 文件数据,将 “观看日期” 转换为 datetime 格式。 2. 按 “视频类型” 分组,统计平均观看时长、平均点赞数和活跃用户数(去重用户 ID 数)。 3. 提取 “观看日期” 中的月份信息,统计每月的总观看时长(转换为小时),绘制折线图。 4. 计算观看时长与点赞数的相关系数。 5. 筛选出分享数 ≥10 的记录,保存为 “高分享视频记录.csv”(不含索引)。
分解代码:
请使用 pandas 和 matplotlib 完成以下任务:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
```
**1. 读取 CSV 文件数据,将 “观看日期” 转换为 datetime 格式。**
````python
df = pd.read_csv("短视频行为数据.csv")
df['观看日期'] = pd.to_datetime(df['观看日期'])
print(df)
```
运行结果:
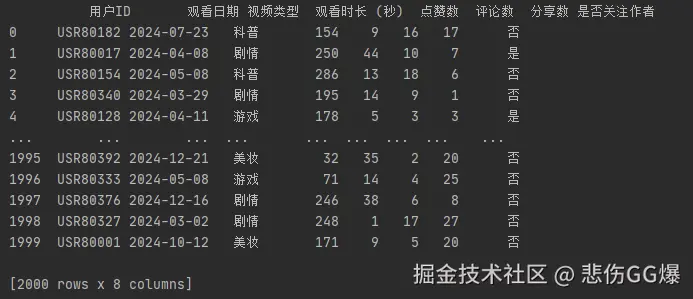
**2. 按 “视频类型” 分组,统计平均观看时长、平均点赞数和活跃用户数(去重用户 ID 数)。**
````python
df_states = df.groupby("视频类型").agg(
平均观看时长=('观看时长 (秒)', 'mean'),
平均点赞数=('点赞数', 'mean'),
活跃用户数=('用户ID', 'nunique') # 去重
).reset_index()
print(df_states)
```
运行结果:
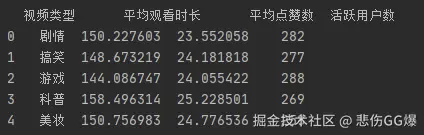
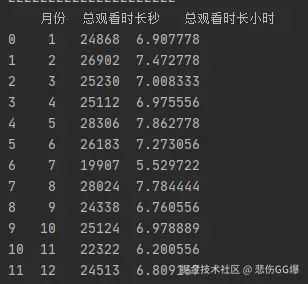
**3. 提取 “观看日期” 中的月份信息,统计每月的总观看时长(转换为小时),绘制折线图。**
````python
df['月份'] = df['观看日期'].dt.month
month_watch = df.groupby('月份').agg(
总观看时长秒=('观看时长 (秒)', 'sum')
).reset_index()
month_watch['总观看时长小时'] = month_watch['总观看时长秒'] / 3600
print(month_watch)
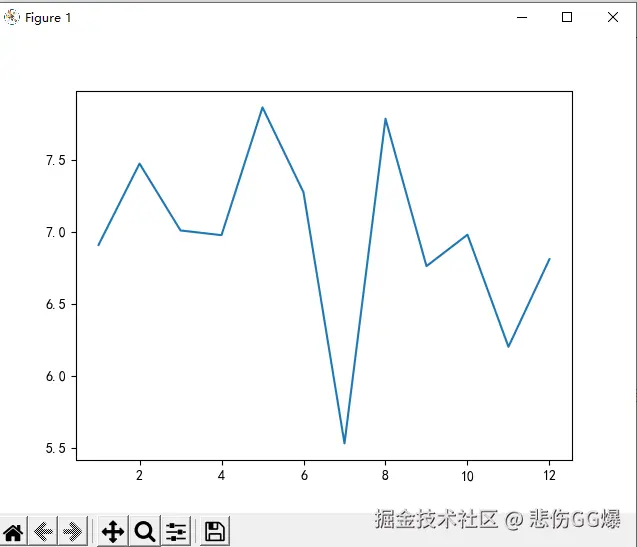
plt.plot(month_watch['月份'], month_watch['总观看时长小时'])
plt.show()
```
运行结果:
**4. 计算观看时长与点赞数的相关系数。**
````python
corr = df['观看时长 (秒)'].corr(df['点赞数'])
print(corr)
```
运行结果:

**5. 筛选出分享数 ≥10 的记录,保存为 “高分享视频记录.csv”(不含索引)。**
````python
new_df = df[df['分享数'] >= 10]
new_df.to_csv('高分享视频记录.csv')
```
**完整代码**
```python
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 1. 读取 CSV 文件数据,将 “观看日期” 转换为 datetime 格式。
df = pd.read_csv("短视频行为数据.csv")
df['观看日期'] = pd.to_datetime(df['观看日期'])
print(df)
# 2. 按 “视频类型” 分组,统计平均观看时长、平均点赞数和活跃用户数(去重用户 ID 数)。
df_states = df.groupby("视频类型").agg(
平均观看时长=('观看时长 (秒)', 'mean'),
平均点赞数=('点赞数', 'mean'),
活跃用户数=('用户ID', 'nunique') # 去重
).reset_index()
print(df_states)
# 3. 提取 “观看日期” 中的月份信息,统计每月的总观看时长(转换为小时),绘制折线图。
df['月份'] = df['观看日期'].dt.month
month_watch = df.groupby('月份').agg(
总观看时长秒=('观看时长 (秒)', 'sum')
).reset_index()
month_watch['总观看时长小时'] = month_watch['总观看时长秒'] / 3600
print(month_watch)
plt.plot(month_watch['月份'], month_watch['总观看时长小时'])
plt.show()
# 4. 计算观看时长与点赞数的相关系数。
corr = df['观看时长 (秒)'].corr(df['点赞数'])
print(corr)
# 5. 筛选出分享数 ≥10 的记录,保存为 “高分享视频记录.csv”(不含索引)。
new_df = df[df['分享数'] >= 10]
new_df.to_csv('高分享视频记录.csv')
```
