

本文价值提示:
💡 面向人群:拥有 Java/Scala/Spark 背景,正在向 AI Agent/RAG 架构转型的后端或大数据工程师。
🎯 核心收获:
- 思维重构:如何用 Spark 的“惰性求值”思维理解 Python 生成器。
- 架构解耦:如何用 Spring AOP 的“切面”思维掌握 Python 装饰器。
- 实战落地:手把手构建一个自动重试+流式输出的高可用 LLM 接口。
在大数据时代,Python 往往被我们视为“胶水语言”——写写 Airflow 调度脚本,或者用 PySpark 做个简单的 ETL。那时候,我们的重型武器是 Java 和 Scala,追求的是高吞吐和强类型约束。
但在 AI 2.0 时代,Python 翻身做主人,成为了核心业务逻辑的承载者。
当你开始构建 AI Agent 或 RAG(检索增强生成)应用时,你会发现:LLM 的 API 极其不稳定,且响应速度慢得惊人。 如果你还用写脚本的方式写架构,系统分分钟崩溃。
今天,我们将深入 Python 的生成器 (Generators) 和 装饰器 (Decorators) ,带你从“脚本小子”进化为“AI 架构师”。
01 🌊 生成器 (Generators):数据的“惰性”流动
🤔 大数据思维映射
还记得 Spark RDD 或 Flink DataStream 吗?
它们的核心特性是 Lazy Evaluation(惰性求值)。当你定义一个 map 操作时,数据并没有真正计算;只有当触发 Action 时,数据才像水流一样流过管道。
Python 的生成器(Generator),就是单机版的 Flink 流。
🚫 传统列表的痛点
在处理 LLM 响应时,传统的做法是等待 AI 生成完所有 1000 个字,再一次性返回给用户。
这就像 Spark 里的 collect() 算子,把所有数据拉回 Driver 端,结果就是:
- 用户体验极差:看着空白屏幕干等 10 秒。
- 内存爆炸:如果并发高,内存瞬间被撑爆。
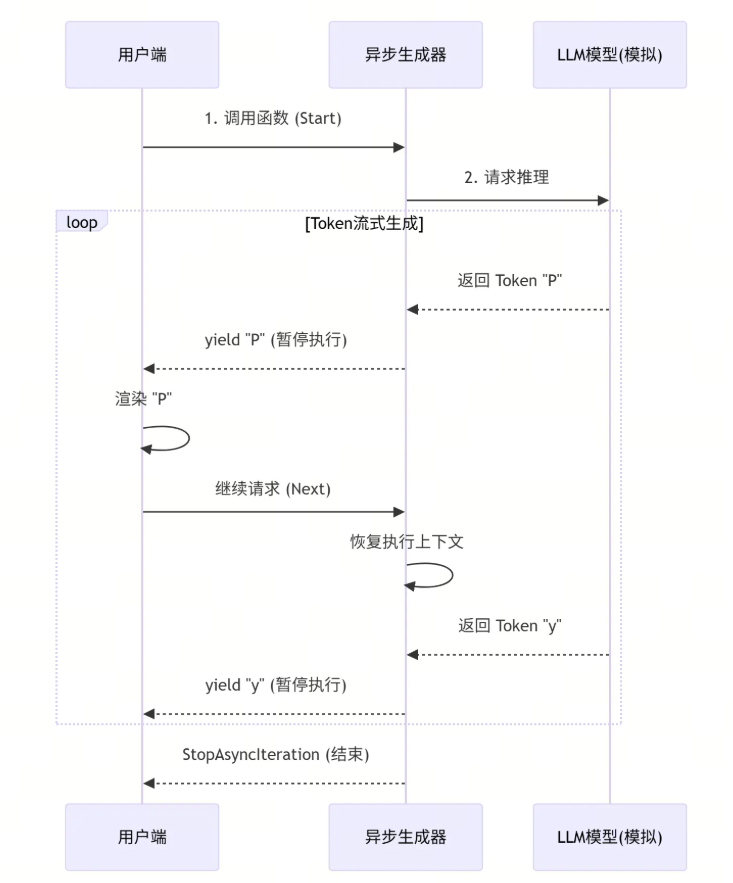
✅ 生成器的魔法:yield
生成器使用 yield 关键字。它不像 return 那样交出结果就结束函数,而是交出一个值,然后“暂停”在原地,保留现场,等待下一次召唤。
这正是 ChatGPT 实现“打字机效果”的核心技术!
💻 代码实战:模拟 LLM 流式吐字
在 AI 工程中,我们通常使用 异步生成器 (async generator),因为网络 I/O 是最大的瓶颈。
import asyncio
import time
from typing import AsyncGenerator
# 模拟一个耗时的 LLM 推理过程
async def mock_llm_stream(query: str) -> AsyncGenerator[str, None]:
"""
模拟 LLM Token 生成。
这就像 Flink 的 Source Function,源源不断产生数据。
"""
print(f"🤖 AI 收到问题: {query}")
response_text = "Python 的生成器机制非常适合处理 LLM 的流式传输..."
for token in response_text:
# 模拟网络延迟 (非阻塞)
# ⚠️ 注意:千万别用 time.sleep(),那会卡死整个 Event Loop!
await asyncio.sleep(0.1)
# 【关键点】yield 将数据"推"给下游,并暂停在此处
yield token
# 消费端 (Sink)
async def main():
print("--- 开始接收流 ---")
# 【关键点】必须使用 async for 来遍历异步生成器
async for token in mock_llm_stream("什么是生成器?"):
# end='' 模拟打字机效果,不换行
print(token, end='', flush=True)
print("\n--- 结束 ---")
📊 流程图解
看看数据是如何像水流一样被 yield 出来的:
02 🛡️ 装饰器 (Decorators):Python 版的 AOP
🤔 大数据思维映射
在 Java Spring 开发中,你一定用过 @Transactional 处理事务,或者 @Retryable 处理重试。这就是 AOP(面向切面编程)。
你不需要修改业务代码,只需要加一个注解,就能把“鉴权、日志、重试、熔断”这些非业务逻辑“织入”到代码中。
Python 的装饰器,就是更灵活、更动态的 AOP。
🛠️ 为什么 AI 架构必用装饰器?
LLM 的 API 是出了名的“娇气”:
- Rate Limit: 动不动就报 429 Too Many Requests。
- Timeout: 经常 504 Gateway Timeout。
- 不稳定: 偶尔返回乱码或空值。
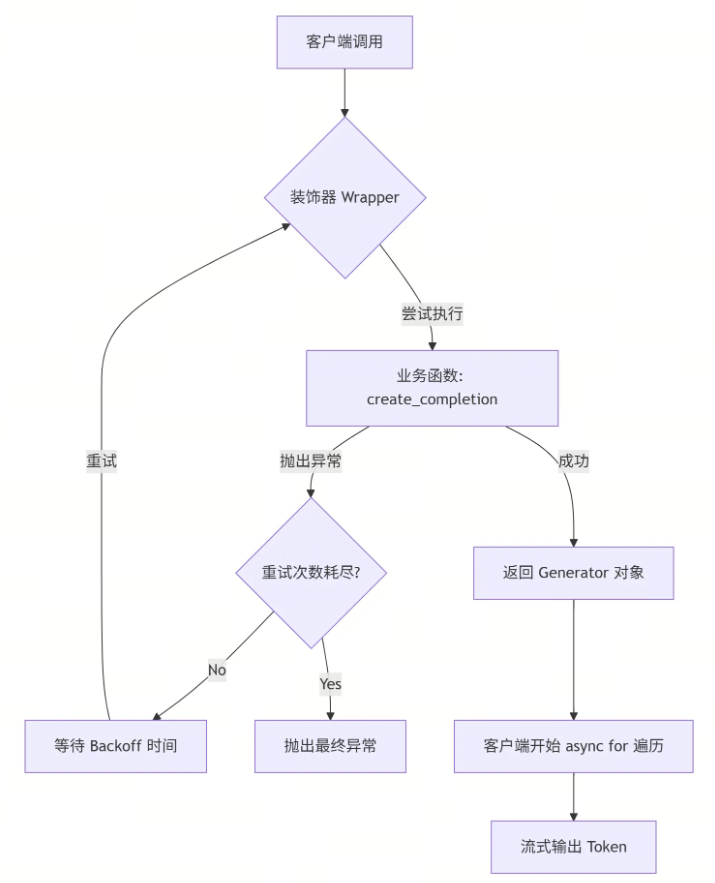
如果我们把重试逻辑写在业务代码里,代码会变成一团乱麻。我们需要一个**“指数退避重试”**的切面。
💻 代码实战:打造“高可用护甲”
import asyncio
import functools
import logging
from typing import Callable, Any, AsyncGenerator
# 配置日志:显示时间戳以便观察重试间隔
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger("RetrySystem")
def retry_with_backoff(max_retries: int = 3, initial_delay: float = 1.0):
"""
装饰器工厂:用于接收配置参数,闭包保存重试配置。
"""
def decorator(func: Callable[..., AsyncGenerator]):
# 使用 functools.wraps 保留原函数的名称、文档等元数据
@functools.wraps(func)
async def wrapper(*args, **kwargs):
"""
代理生成器 (Proxy Generator)。
它拦截调用,并在内部管理对原始生成器的迭代和重试。
注意:因为函数体内包含 yield,wrapper 本身也会返回一个 AsyncGenerator。
"""
delay = initial_delay
# --- 重试循环 ---
for attempt in range(max_retries):
try:
# 1. 获取生成器实例
# 调用原函数 func(*args),此时原函数内部代码并未执行!
# 它仅仅返回一个"未启动"的生成器对象 (Generator Object)。
gen = func(*args, **kwargs)
# 2. 驱动生成器执行 (关键步骤)
# 使用 async for 遍历生成器,这会触发 func 内部代码开始运行。
# 如果 func 内部抛出异常(如连接失败),会在这里被触发,从而被外层 try 捕获。
async for item in gen:
# 3. 数据透传
# 将底层生成器产生的数据,原封不动地 yield 给最外层的调用者。
yield item
# 4. 成功退出
# 如果上面的循环完整走完且没有报错,说明流式传输成功完成。
# 直接 return 结束 wrapper 生成器,不再进行后续重试。
return
except Exception as e:
# --- 异常捕获与处理 ---
logger.warning(f"⚠️ [第 {attempt + 1} 次失败] 捕获异常: {e}")
# 检查是否还有重试机会
if attempt < max_retries - 1:
# 计算指数退避时间 (1s, 2s, 4s...)
sleep_time = delay * (2 ** attempt)
logger.info(f"⏳ 等待 {sleep_time} 秒后重新创建生成器...")
# 挂起当前任务,等待冷却
await asyncio.sleep(sleep_time)
# 循环继续 -> 下一次迭代会再次调用 func()
# 这相当于创建了一个全新的生成器实例,实现了"从头重试"。
else:
# 重试次数耗尽,记录错误并向上抛出,通知调用方彻底失败
logger.error("❌ 重试次数耗尽,操作失败。")
raise e
return wrapper
return decorator
03 🏗️ 综合实战:构建高可用 LLM 网关
现在,我们将 Stream(流式) 和 Decorator(切面) 结合起来,解决一个真实的工程痛点: “如何优雅地调用一个经常挂掉的 LLM 接口,并流式返回给用户?”
场景模拟
- 不稳定: 模拟 70% 概率连接失败。
- 流式: 连接成功后,逐字吐出。
- 无感重试: 用户不知道底层重试了,只看到最终结果。
🚀 完整架构代码
import random
# --- 业务层 ---
class UnstableLLMProvider:
# 应用装饰器:
# 当调用 create_completion_stream 时,实际上调用的是 wrapper
@retry_with_backoff(max_retries=4, initial_delay=0.5)
async def create_completion_stream(self, prompt: str):
"""
模拟不稳定的 LLM 流式接口。
"""
# 模拟 API 网关随机抖动 (70% 概率失败)
# 注意:这个异常只有在 wrapper 进行 async for 遍历时才会被触发
if random.random() < 0.7:
raise ConnectionError("模拟 API 网关超时 (504 Gateway Timeout)")
print(f"✅ [底层提供商] 连接成功!开始流式传输关于 '{prompt}' 的内容...")
# 模拟生成内容
content = "Python 异步生成器重试机制演示..."
for char in content:
# 模拟 Token 生成延迟
await asyncio.sleep(0.1)
# 逐个字符产出
yield char
# --- 调用层 ---
async def run_business_logic():
client = UnstableLLMProvider()
try:
print("🚀 [业务层] 发起请求...")
# 1. 获取代理生成器
# 这里调用的是 wrapper,它立即返回一个 AsyncGenerator,不会阻塞
stream = client.create_completion_stream("RAG 架构设计")
# 2. 消费数据
# 这里的 async for 会驱动 wrapper 运行 -> wrapper 驱动 UnstableLLMProvider 运行
# 整个链路像齿轮一样咬合转动
async for token in stream:
print(token, end='', flush=True)
print("\n✅ [业务层] 接收完成")
except Exception as e:
# 如果重试耗尽,异常最终会抛到这里
print(f"\n💀 [业务层] 服务最终不可用: {e}")
if __name__ == "__main__":
# 启动事件循环
asyncio.run(run_business_logic())
🧩 逻辑流程图
看看装饰器是如何拦截并保护你的业务逻辑的:
📝 总结与展望
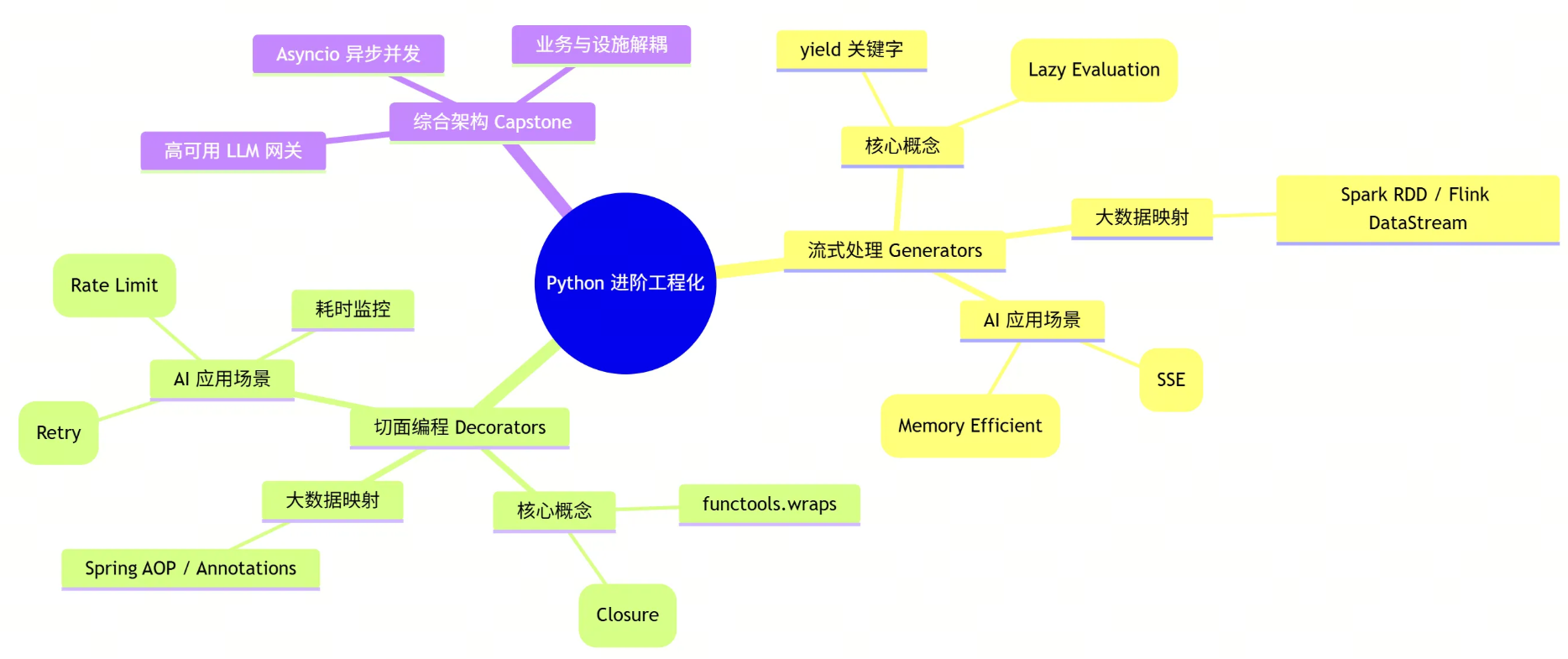
从大数据转型 AI 架构,语言只是工具,思维才是核心。
- Generators 让你学会了处理 AI 的“流式数据”,就像处理 Spark 的 RDD。
- Decorators 让你学会了架构的“解耦”,就像使用 Spring 的 AOP。
当你把这两个工具结合起来,你就拥有了构建生产级 AI 应用的基石:既能处理高并发的 I/O 等待,又能从容应对不稳定的外部依赖。
🧠 本文核心知识图谱
下期预告: 搞定了核心逻辑,如何将其封装成微服务?下一篇我们将深入 FastAPI,探讨如何结合 Pydantic 进行强类型接口定义,构建符合 OpenAPI 标准的 AI 微服务。
👉 关注我,带你用架构师的思维玩转 AI 工程化!
