

掌握这个20个Linux命令,能帮你解决90%的服务器问题,总结与实操结合,极具价值,建议【点赞】【收藏】,建议【关注我】,以免错过后续更多干货内容。
1.top / htop
实时看 CPU、内存、进程占用。这是一个非常重要且常用的工具,能够帮你快速检查CPU、内存、进程的情况,对于排查服务器问题非常有效。
top效果如下图:
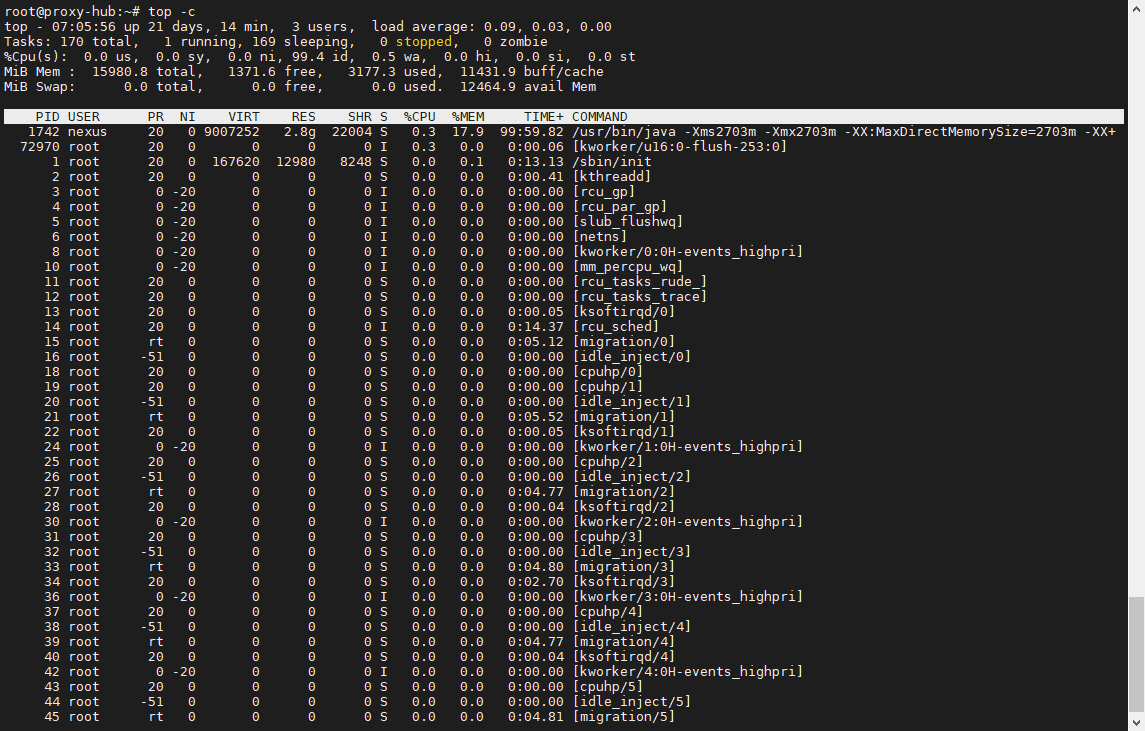
htop效果如下图:
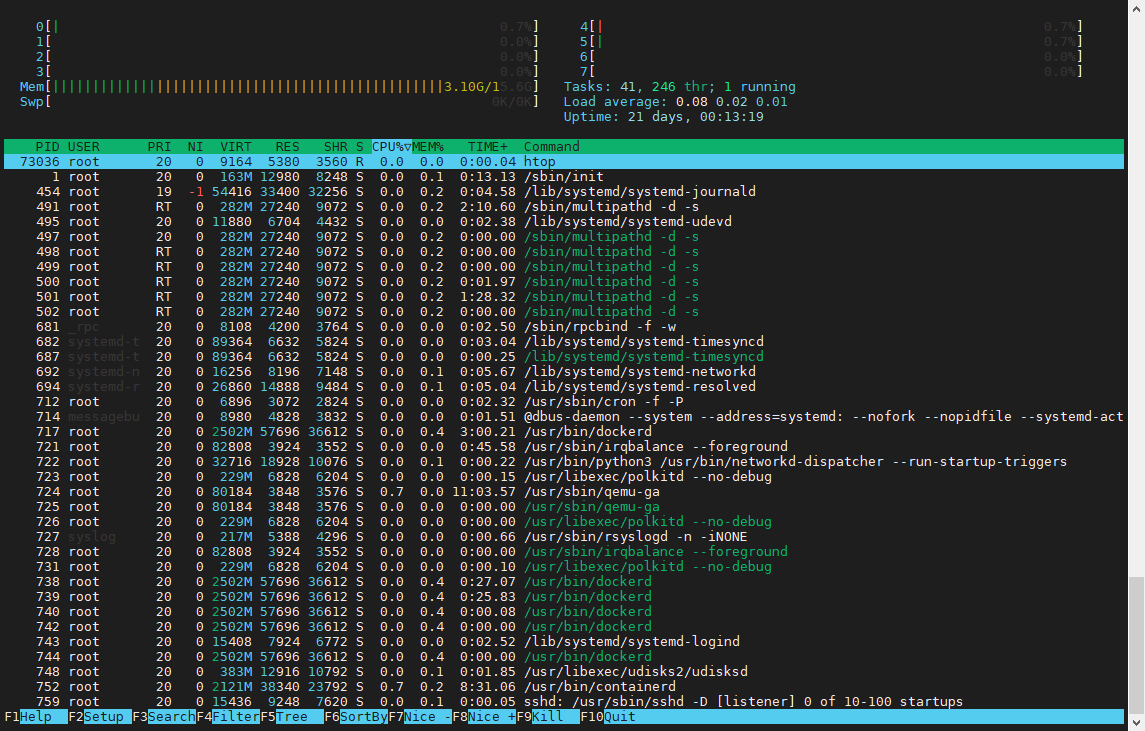 使用
使用top -c 能够显示完整命令;htop 是更友好的工具,但通常需额外安装才能用。
2.free -h
快速查内存使用情况。
 重点关注
重点关注 available,这是真正可用内存,别只看used,还要看buff/cache,Linux 会用缓存,不代表真没内存!
3.df -h
看磁盘空间使用情况。尤其要关注 / 和 /var 分区的情况。
出现报错 “No space left”时,别犹豫,第一时间用df -h查看一下。
 看看
看看Avail这是可用的,Use%这个是使用率,百分比越高,说明占用空间越多,可用空间越少。
4.vmstat
查看系统整体运行状况,助你一眼窥探系统瓶颈。
例如:vmstat -w 1 5 整体查看运行状况

-w参数宽屏列对齐显示,第一个数字是指间隔时间,第二个数字是打印输出次数。你也可以改成vmstat -w 2 5即是每隔2秒采样输出一次,总共采样输出5次。
几个关键指标要注意,id指CPU空闲时间百分比,这个越高说明CPU没那么忙。wa是CPU等待I/O的时间百分比,越高越说明磁盘忙不过来,如果wa > 20%,那你的磁盘有点不堪重负。
5.iostat
深度看磁盘 I/O情况。iostat是用于监控系统 CPU 使用率 和 磁盘 I/O 性能 的工具。
例如:iostat -x 1 2 查看磁盘的情况
 其中-x参数显示更详细的设备统计信息。1 2参数指每间隔1秒采样输出,总共采样输出2 次 。
avg-cpu是显示CPU情况:
%user 指用户态进程占用 CPU 时间百分比;
%nice 在用户态下,低优先级(nice)进程的时间百分比;
%system 内核态进程占用 CPU 时间百分比;
%iowait CPU 等待 I/O 操作完成的时间百分比
%steal 在虚拟化环境中,被其他虚拟机抢占的CPU时间;
%idle CPU 空闲时间百分比。
Device是设备IO的情况,r开头的是读取 (Read) 相关 (
其中-x参数显示更详细的设备统计信息。1 2参数指每间隔1秒采样输出,总共采样输出2 次 。
avg-cpu是显示CPU情况:
%user 指用户态进程占用 CPU 时间百分比;
%nice 在用户态下,低优先级(nice)进程的时间百分比;
%system 内核态进程占用 CPU 时间百分比;
%iowait CPU 等待 I/O 操作完成的时间百分比
%steal 在虚拟化环境中,被其他虚拟机抢占的CPU时间;
%idle CPU 空闲时间百分比。
Device是设备IO的情况,r开头的是读取 (Read) 相关 (r/s, rkB/s, r_await, 等),w开头的是写入 (Write) 相关 (w/s, wkB/s, w_await, 等)。
d开头是丢弃 (Discard) 相关 (d/s, 等),通常是与 SSD 相关。f开头是刷新区 (Flush)相关 (f/s, 等)。
还有两个关键指标 aqu-sz 是指平均请求队列长度,即IO操作排队情况,越大越表示繁忙。%util 指设备利用率百分比。
6.netstat / ss -tulnp
查看网络状态,比如看那些端口开着,哪些应用在监听什么端口、哪些外部ip连在这台服务器上。
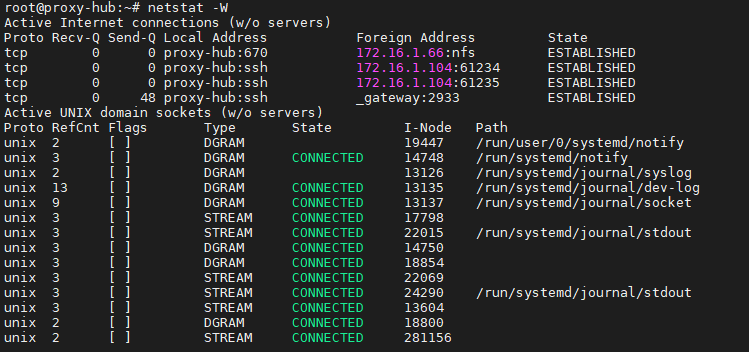

ss -tulnp是替代老旧的 netstat,更快,且显示更友好。很多新发行版都没有装netstat了,如果要使用需要安装,新发行版更多的可能是默认安装了ss。比如要查看80端口是否被占用可以ss -tnp | grep :80方式查看。
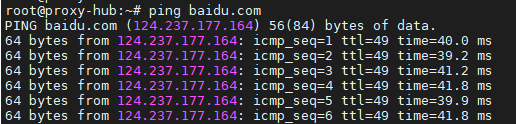
7.ping / traceroute
ping 测试通不通,部分云服务器和一些网站可能禁 ping,可以改用 telnet ip port 测试 TCP连通性。
例如:ping baidu.com 通常用来测试互联网访问是否可达。
traceroute 查看路由卡在哪一跳。可能部分系统要安装才可以用。
例如:traceroute baidu.com 来测试经过哪些路由或者路由耗时。
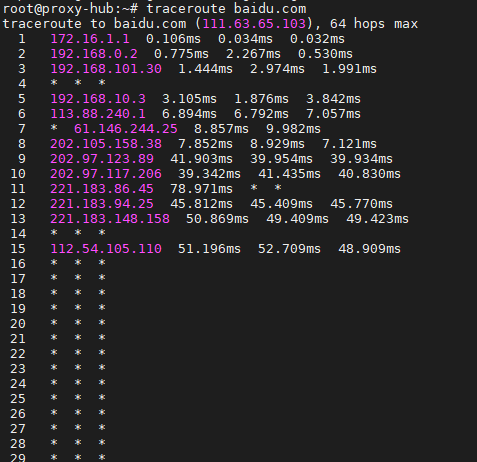 这里看到部分很多星号。甚至后面全都是星号*是因为大部分核心服务器基于安全和减少无用负载考虑,不响应traceroute的探测包。
这里看到部分很多星号。甚至后面全都是星号*是因为大部分核心服务器基于安全和减少无用负载考虑,不响应traceroute的探测包。
8.tcpdump
这是linux下一个常用的抓包神器!常用于排查 API 异常、丢包、协议问题。
例如:tcpdump -i any -c 5 -i any是指定所有网络(网卡)。-c 5是指抓包5次

例如:tcpdump -i eth0 port 80 -w http.pcap 指抓取eth0网卡下端口80的数据 保存http.pcap文件中。
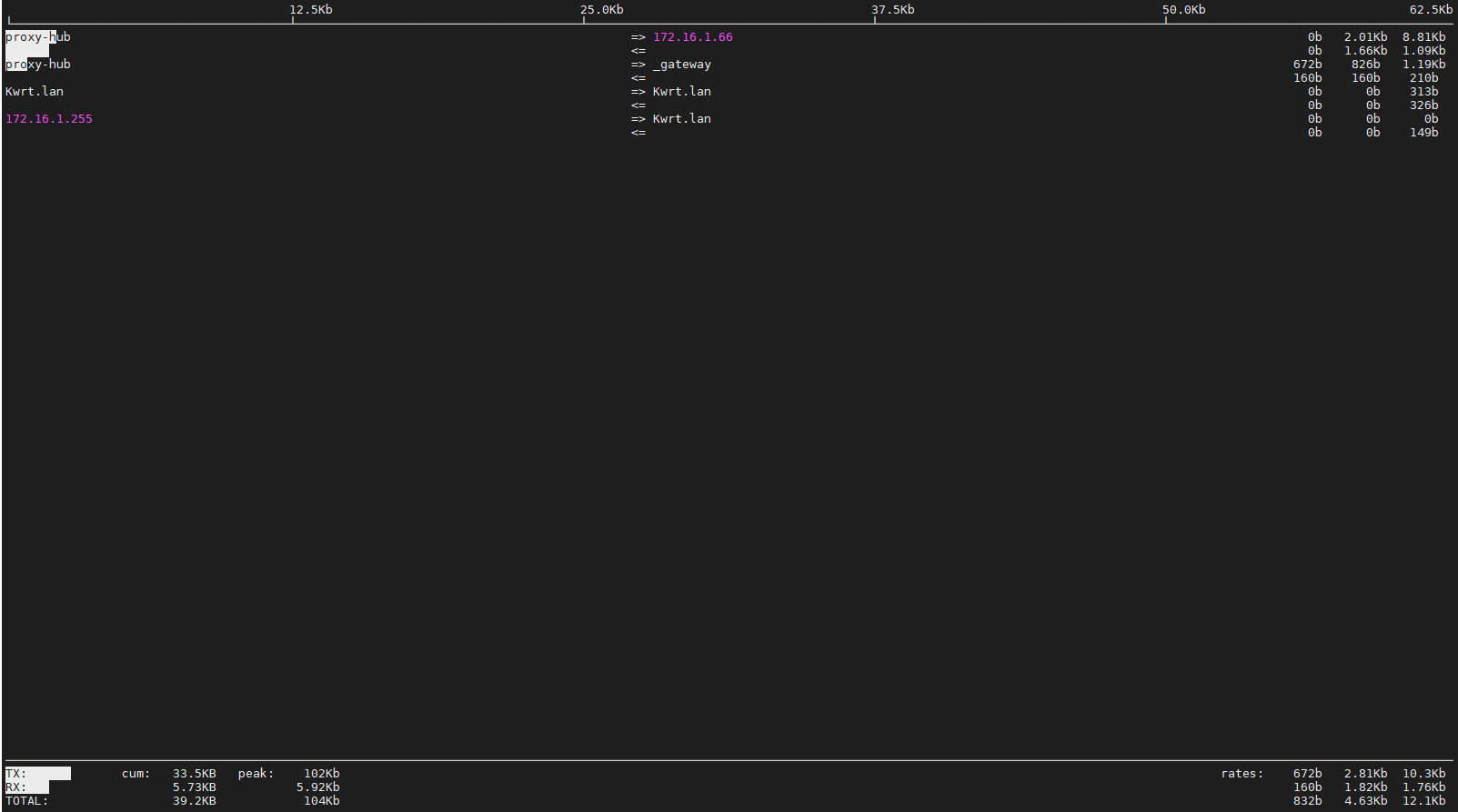
9.iftop
iftop是一个专门实时监控和查看网络流量的工具,可以实时看流量排行,比如可以用来揪出 DDoS 或异常上传进程。
例如:iftop -i eth0 如下图所示
10.grep
文本搜索之王!支持正则、上下文显示。
例如:grep -A3 -B2 "FAILURE" syslog(错误前后3行)

11.tail -f
实时追踪日志更新,调试必备。可以通过管道符组合其他命令。
例如: tail -500f syslog | grep --color "failed"
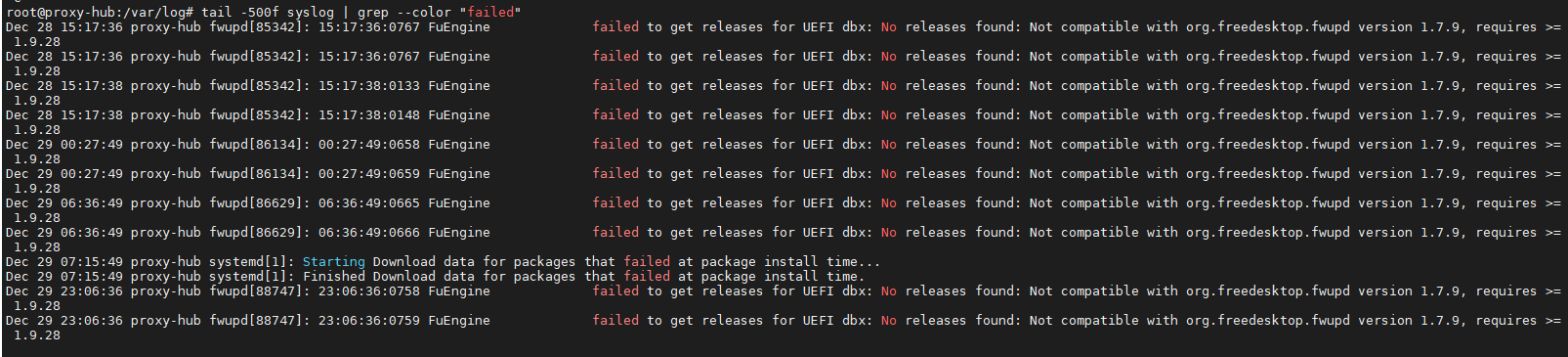 这样就可以通过关键词搜索到想要的内容了。常用于故障分析和排查。
这样就可以通过关键词搜索到想要的内容了。常用于故障分析和排查。
12.awk / sed
awk 统计分析(如 Nginx 状态码),sed 批量替换。
例:awk '{print $9}' access.log | sort | uniq -c
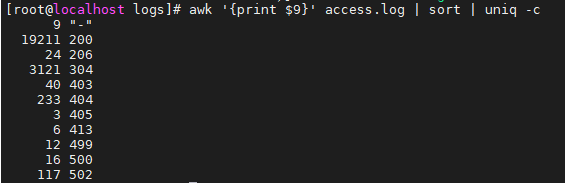 如图,每种请求的状态值就统计出来了,左边是次数,右边是状态码。
如图,每种请求的状态值就统计出来了,左边是次数,右边是状态码。
13.find
按大小、时间、名称等找文件。
例:find /var/log -size +100M -mtime +7(找7天前的大日志)
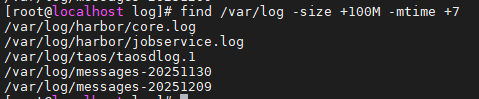
14.du
查看目录或者目录下的各文件大小,快速定位快速占领磁盘空间的“元凶”。
如下:du -sh * | sort -hr快速定位哪些文件占用空间最大
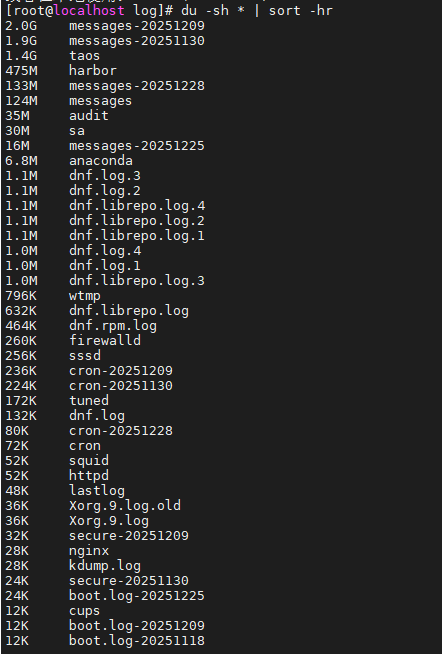
15.lsof
lsof是List Open Files的缩写,是一个强大的命令行工具,用于列出当前系统被进程打开的文件。由于Linux中“一切皆文件”的理念,所以包括普通文件、目录、网络连接(如TCP/UDP端口)、设备文件、管道、共享库等。最常用于查哪个进程占用了端口(比 netstat 更直接),即lsof -i :端口号查看端口被占用情况。
例如:lsof -i :3306 查看3306是否被占用,以及被什么程序占用了。LISTEN那个即表示被占用了,mysqld占用了,这是mysql的守护进程。

16.ps
查找特定进程。常组合使用ps aux | grep [p]rocess (方括号避免 grep 自身被匹配)
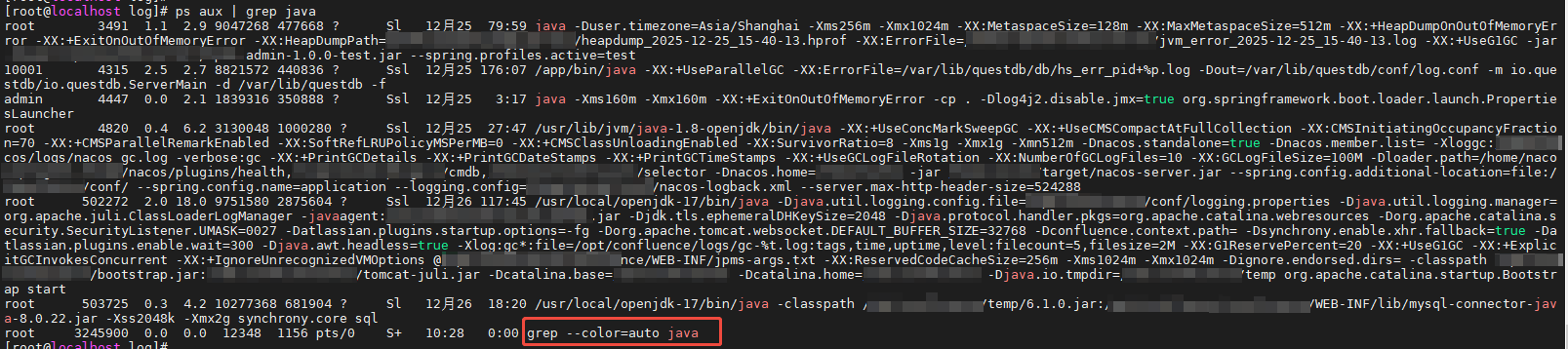
例如:ps aux | grep [j]ava 或者 ps aux | grep java 前者是不包含自身的,后者会显示grep自身。
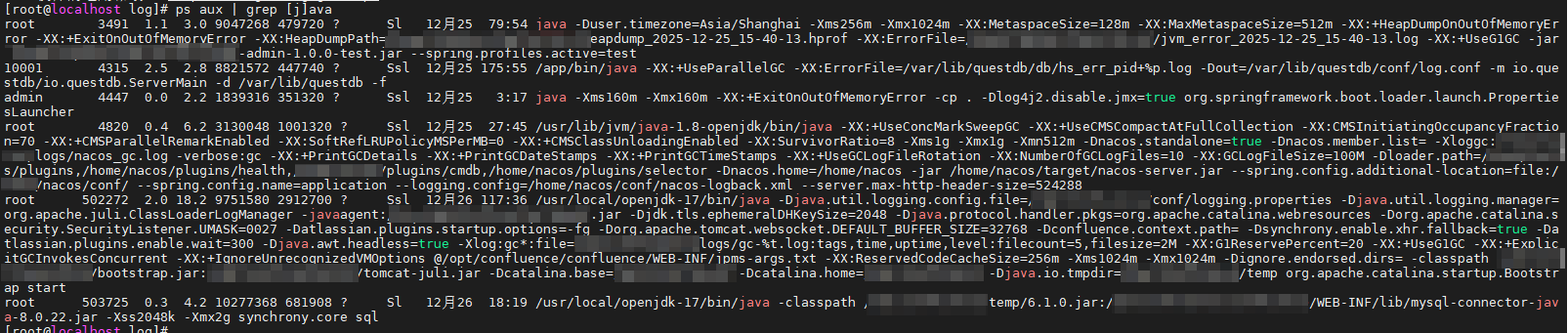 上图是
上图是ps aux | grep [j]ava的效果,下图是ps aux | grep java,可以对照看下有什么不一样。
17.kill / killall
杀死进程,先 kill PID(优雅退出),不行再 kill -9(强制终止)。
[!note] 正式环境一定要谨慎使用 -9
这个就不展示了,实际上没啥好展示的,kill完也不会提示(记住:没有消息就是好消息),不过一般是跟第16个命令一起使用,先查出进程号,在直接kill,例如要杀上面的admin.jar进程,直接kill 3491或者kill -9 3491。
18.systemctl
这个没啥好说的,管理服务命令,常配合:start/stop/restart/status使用。
例如:
启动docker服务systemctl start docker
重启docker服务systemctl restart docker 。
 没有消息就是好消息,服务已经重启好了,只不过部署应用有点多的话,重启需要一会儿等待完成。
没有消息就是好消息,服务已经重启好了,只不过部署应用有点多的话,重启需要一会儿等待完成。
19.journalctl
查 systemd 服务的日志,比翻 /var/log 更集中。就是日志量大时会有点耗时。常用例如:journalctl -u 服务名 --since "1 hour ago"查看服务近1小时日志。
例如我想看docker的近一小时系统日志。直接journalctl -u docker --since "1 hour ago"

20.history
history就是快速帮你找回你曾经敲过的命令,省得重复记忆!
history | grep "关键词"这个特别好用,直接上图。
 最近使用过什么命令全出来了。
最近使用过什么命令全出来了。
如果网站慢?我们试试按照这个思路排查 → top(看CPU)→ ss(看连接数)→ tail -f(看日志)→ iostat(看磁盘)。
当然我们不是要去死记硬背这些命令,这里只是总结知识点帮助我们快速掌握最常用最核心的东西,达到事半功倍的效果。我们应该先熟悉这些命令,然后灵活应用,特别是组合使用这些命令,往往能达到四两拨千斤的效果。
看都看完了,不【点赞】【收藏】一下么,建议【关注我】,后续更多干货内容不容错过。
