简单数据分析函数
代码
'''
数据分析函数参数说明:
-main_data:位置参数,必须传入的主要数据分析列表
-*extra_data:可变长度的位置参数,可以传入若干个额外数据列表进行分析
-threshold:默认值参数,用于分析数据的阈值,默认为None时取main_data和extra_data之和的平均值
数据分析函数的返回值说明:
-total_sum:传入的所有数据的总和(包括main_data和extra_data)
-volatility:数据的波动指数(最大值和最小值的差)
-high_count:高于阈值的元素数量
'''
def data_analysis(main_data, *extra_data, threshold=None):
all_data = main_data
for data in extra_data:
all_data = all_data + data
total_sum = sum(all_data)
volatility = max(all_data) - min(all_data)
if threshold is None:
threshold = total_sum / len(all_data)
high_count = sum(1 for data in all_data if data > threshold)
return total_sum, volatility,high_count
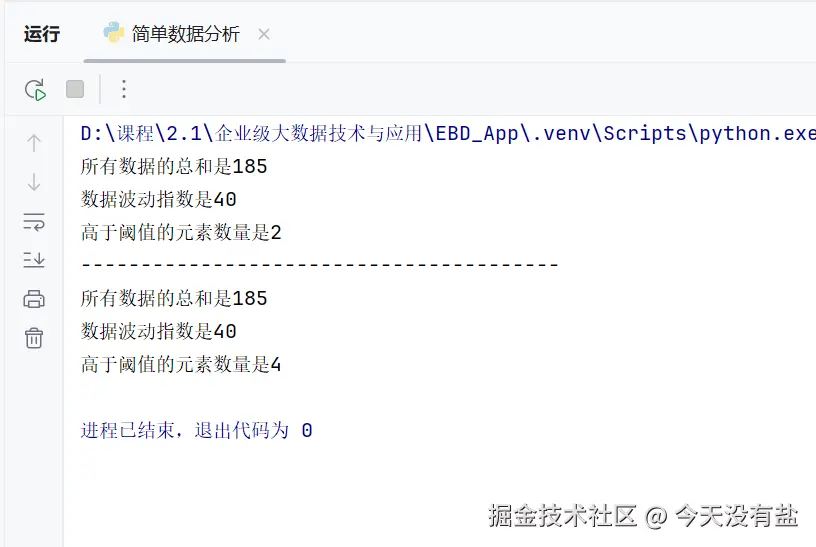
total_sum, volatility,high_count = data_analysis([10, 20, 30], [5, 15] , [25, 35, 45], threshold=30)
print(f'所有数据的总和是{total_sum}')
print(f'数据波动指数是{volatility}')
print(f'高于阈值的元素数量是{high_count}')
print('-'*40)
total_sum, volatility,high_count = data_analysis([10, 20, 30], [5, 15] , [25, 35, 45])
print(f'所有数据的总和是{total_sum}')
print(f'数据波动指数是{volatility}')
print(f'高于阈值的元素数量是{high_count}')
代码结果
代码分析
- 函数使用了灵活的参数设计:位置参数、可变参数和默认参数
- 通过
*extra_data接收任意数量的额外数据列表,提高了函数的灵活性
- 阈值参数
threshold有默认值None,当不提供时会自动计算平均值作为阈值
- 使用生成器表达式
sum(1 for data in all_data if data > threshold)高效计算高于阈值的元素数量
- 函数返回三个统计量:总和、波动指数和高阈值数量,满足多维度分析需求
简单数据分析(包调用)
代码
from package1.module1 import data_analysis
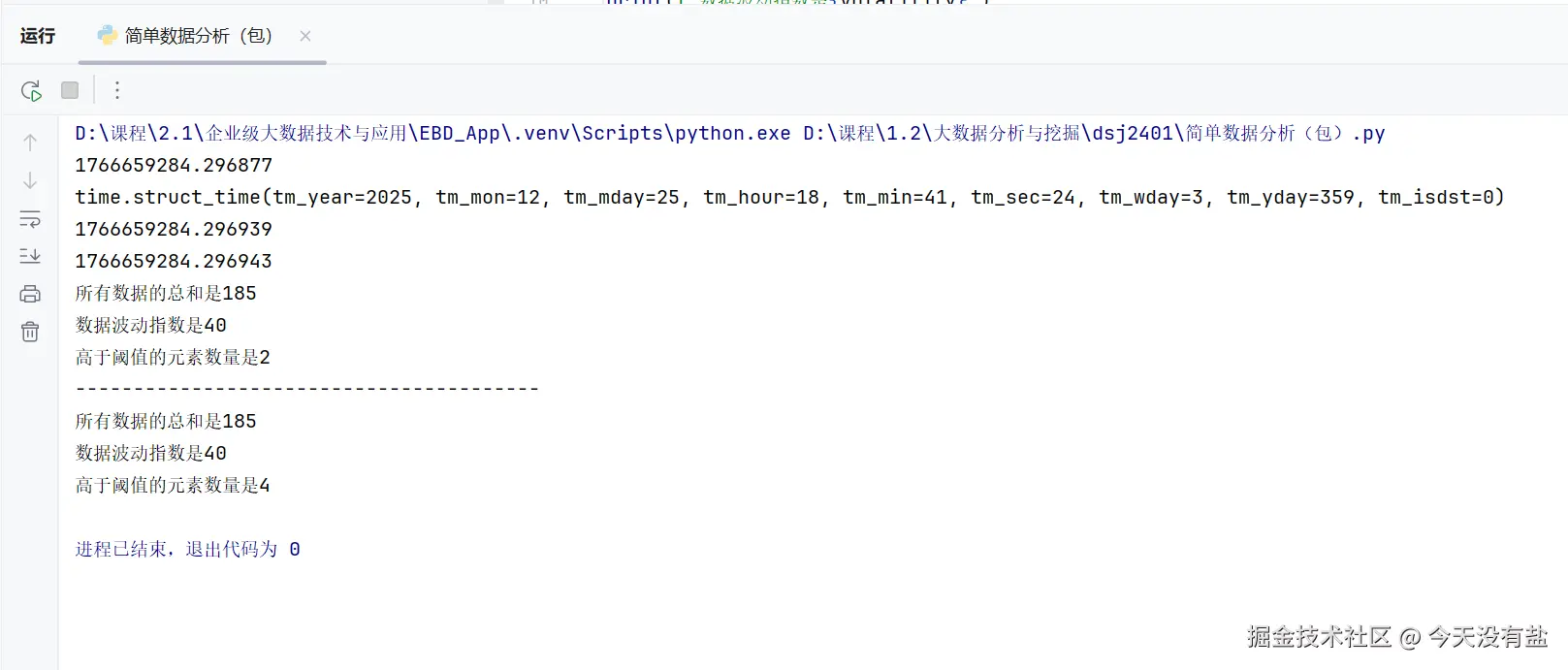
total_sum, volatility,high_count = data_analysis([10, 20, 30], [5, 15] , [25, 35, 45], threshold=30)
print(f'所有数据的总和是{total_sum}')
print(f'数据波动指数是{volatility}')
print(f'高于阈值的元素数量是{high_count}')
print('-'*40)
total_sum, volatility,high_count = data_analysis([10, 20, 30], [5, 15] , [25, 35, 45])
print(f'所有数据的总和是{total_sum}')
print(f'数据波动指数是{volatility}')
print(f'高于阈值的元素数量是{high_count}')
代码结果
代码分析
- 展示了如何将函数封装在包中进行调用,体现了模块化编程思想
- 从
package1.module1导入data_analysis函数,保持了代码的整洁性
- 两次调用展示了不同参数设置下的结果对比,验证了函数的灵活性
- 结果与直接调用函数一致,证明了封装的有效性


