import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("外卖商家数据.csv")
df["单日营收"] = df["接单数量"] * df["客单价 (元)"] * (1 - df["平台抽成比例 (%)"] / 100)
print(df)
df["接单日期"] = pd.to_datetime(df["接单日期"])
df["星期"] = df["接单日期"].dt.dayofweek
print(df)
week_map = {0:"周一", 1:"周二", 2:"周三", 3:"周四", 4:"周五", 5:"周六", 6:"周天"}
df["星期名称"] = df["星期"].map(week_map)
print(df)
df_mean = df.groupby("星期名称").agg(
平均接单数量=("接单数量", "mean"),
平均配送时长=("配送时长 (分钟)", "mean")
).reset_index()
print(df_mean)
hour_mean = df["配送时长 (分钟)"].mean()
hour_std = df["配送时长 (分钟)"].std()
hour_cv = hour_std / hour_mean
h90 = df["配送时长 (分钟)"].quantile(0.9)
print(f"配送时长的变异系数{hour_cv:.2f},90分位数为{h90:.2f}")
df["准时配送"] = df["配送时长 (分钟)"] <= 30
print(df)
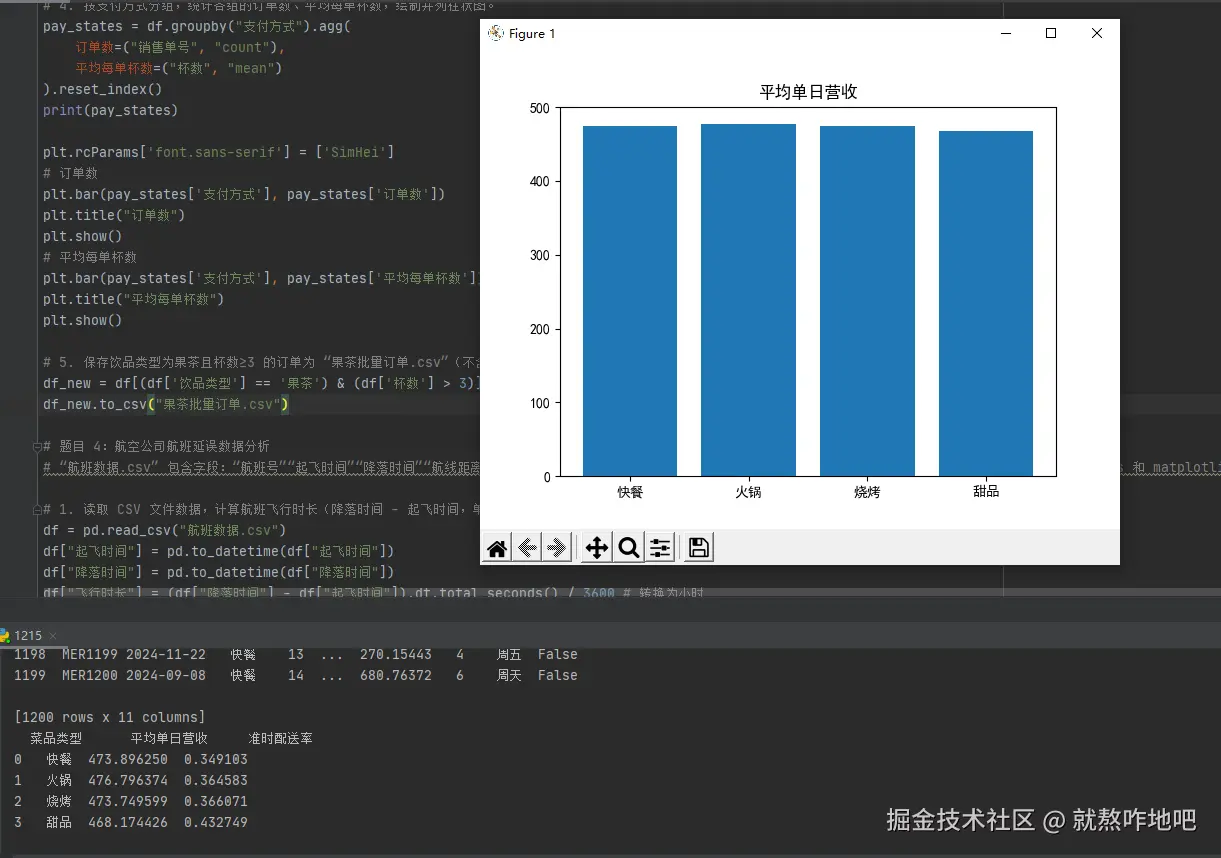
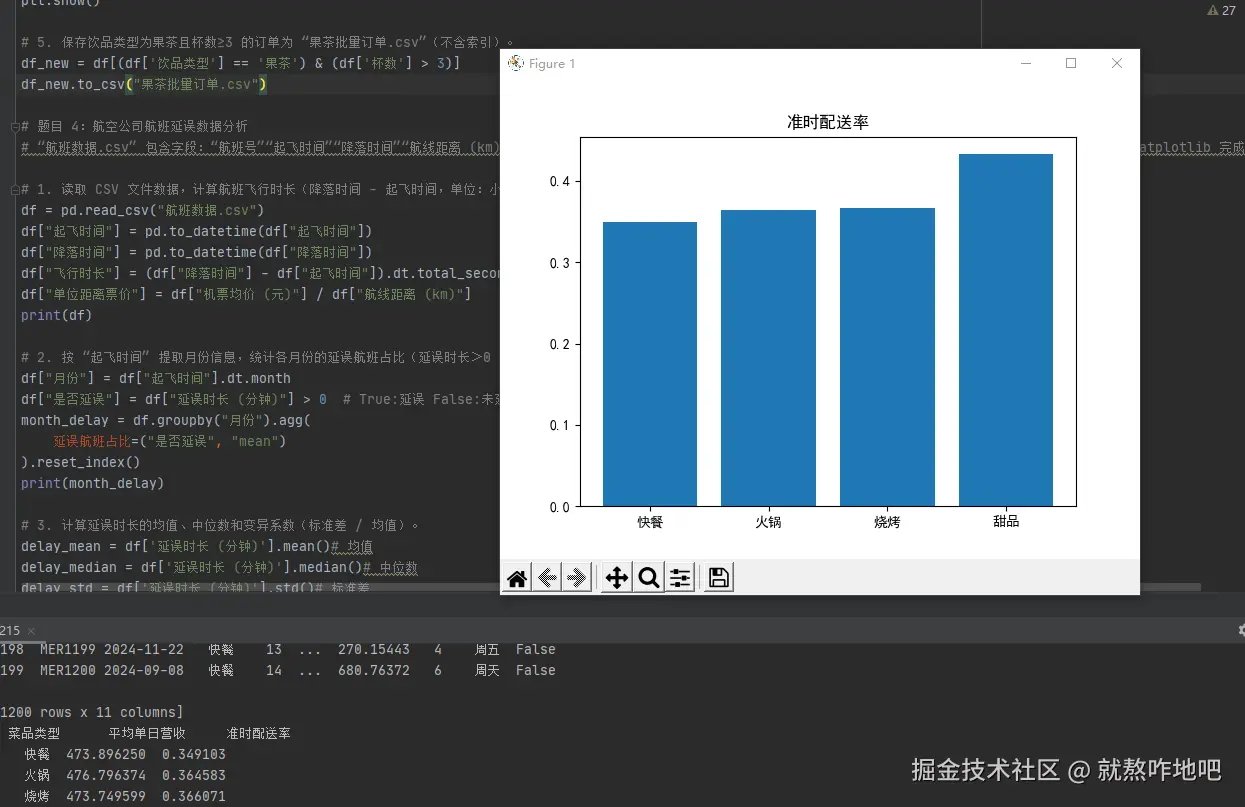
df_states = df.groupby("菜品类型").agg(
平均单日营收=("单日营收", "mean"),
准时配送率=("准时配送", "mean")
).reset_index()
print(df_states)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("平均单日营收")
plt.bar(df_states["菜品类型"], df_states["平均单日营收"])
plt.show()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("准时配送率")
plt.bar(df_states["菜品类型"], df_states["准时配送率"])
plt.show()
df_new = df[df['平台抽成比例 (%)'] >20]
df_new.to_csv("高抽成商家数据.csv")
df = pd.read_csv("网约车出行数据.csv")
df["出行总费用"] = df["基础车费 (元)"] + df["里程加价 (元)"]
df.loc[df["是否高峰期"] == "是", "出行总费用"] += 15
df["到达时间"] = pd.to_datetime(df["到达时间"])
df["出发时间"] = pd.to_datetime(df["出发时间"])
df["行驶时长"] = (df["到达时间"] - df["出发时间"]).dt.total_seconds() / 60
print(df)
df["出发小时"] = df["出发时间"].dt.hour
df_states = df.groupby("出发小时").agg(
订单量=("订单号", "count"),
平均行驶里程=("行驶里程 (km)", "mean")
).reset_index()
print(df_states)
data = df["行驶时长"].agg(['min', 'max', 'mean', 'median'])
print(data)
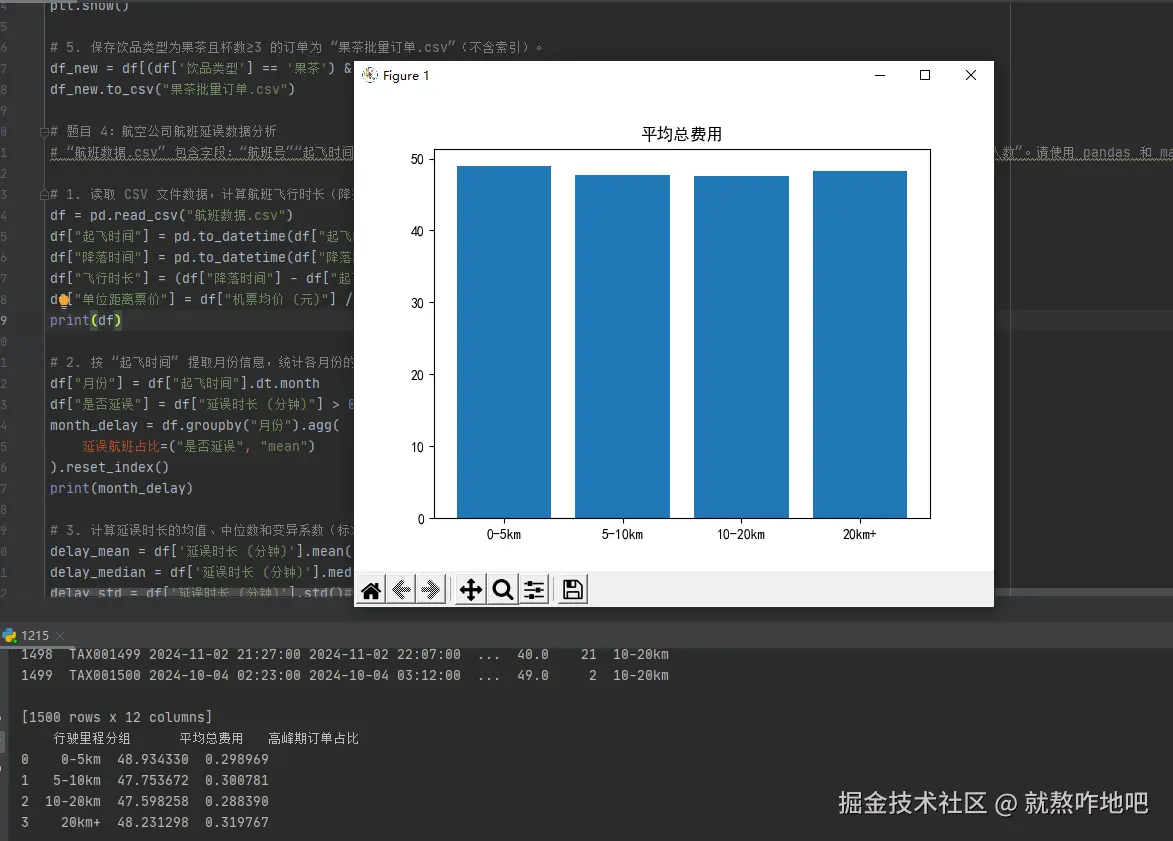
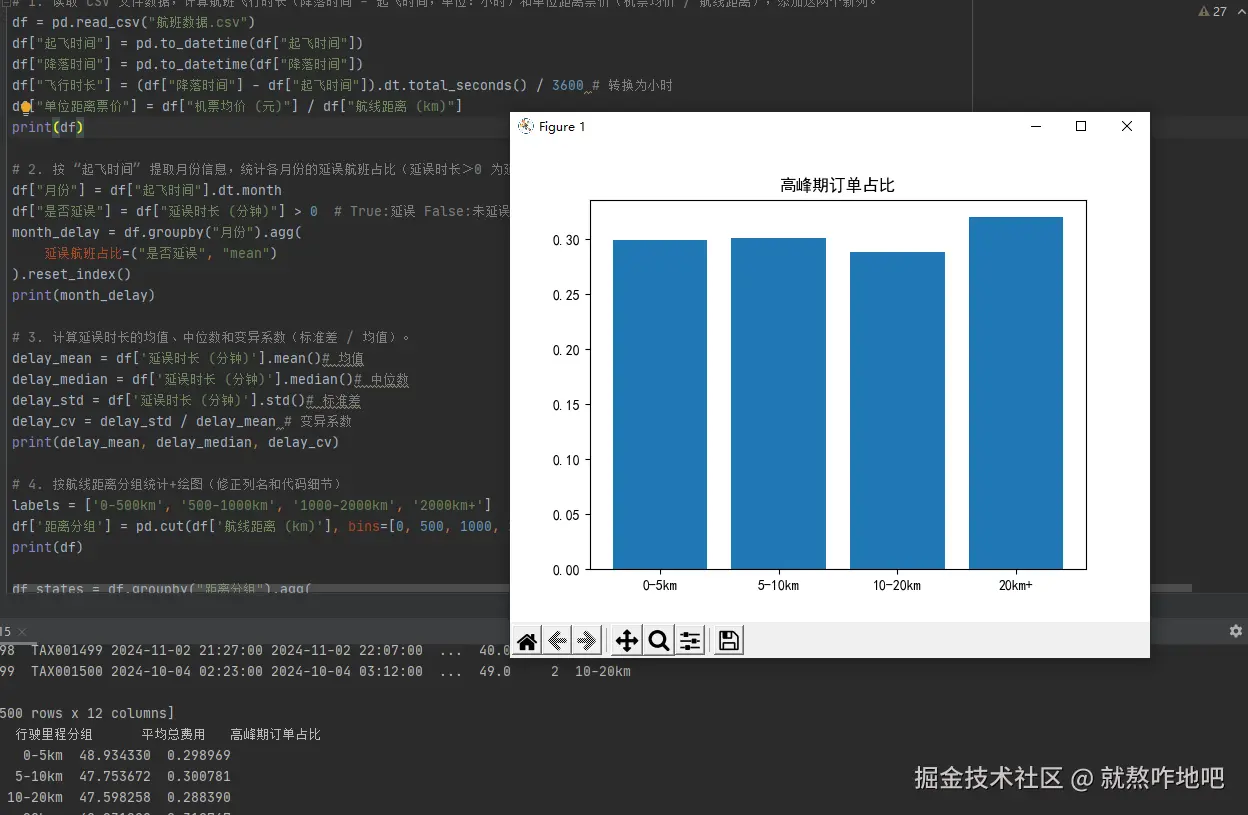
labels = ["0-5km", "5-10km", "10-20km", "20km+"]
df["行驶里程分组"] = pd.cut(df["行驶里程 (km)"], bins=[0, 5, 10, 20, np.inf], labels=labels, right=False)
print(df)
states = df.groupby("行驶里程分组").agg(
平均总费用=("出行总费用", "mean"),
高峰期订单占比=("是否高峰期", lambda x:(x=="是").mean())
).reset_index()
print(states)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("平均总费用")
plt.bar(states['行驶里程分组'], states['平均总费用'])
plt.show()
plt.title("高峰期订单占比")
plt.bar(states['行驶里程分组'], states['高峰期订单占比'])
plt.show()
df_new = df[df['行驶时长'] > 60]
df_new.to_csv("长时出行订单.csv")
df = pd.read_csv("奶茶销售数据.csv")
df["销售日期"] = pd.to_datetime(df["销售日期"])
df["订单金额"] = df["杯数"] * df["单杯价格 (元)"] + df["加料费用 (元)"]
daily_sales = df.groupby("销售日期")["订单金额"].sum().reset_index()
daily_sales.columns = ["销售日期", "单日销售额"]
print(daily_sales)
df = pd.merge(df, daily_sales, on="销售日期", how="left")
df["月份"] = df["销售日期"].dt.month
cost_map = {"奶茶":3, "果茶":4, "咖啡":5, "酸奶":3.5}
df["单杯利润"] = df["单杯价格 (元)"] - df["饮品类型"].map(cost_map)
print(df)
df_states = df.groupby("月份").agg(
总销量=("杯数", "sum"),
平均单杯利润=("单杯利润", "mean")
).reset_index()
print(df_states)
q25 = df['加料费用 (元)'].quantile(0.25)
q50 = df['加料费用 (元)'].quantile(0.5)
q75 = df['加料费用 (元)'].quantile(0.75)
q_sum = df['加料费用 (元)'].sum()
print(f"加料费用的四分位数分别为:{q25:.2f}, {q50:.2f}, {q75:.2f}, 总和为: {q_sum:.2f}")
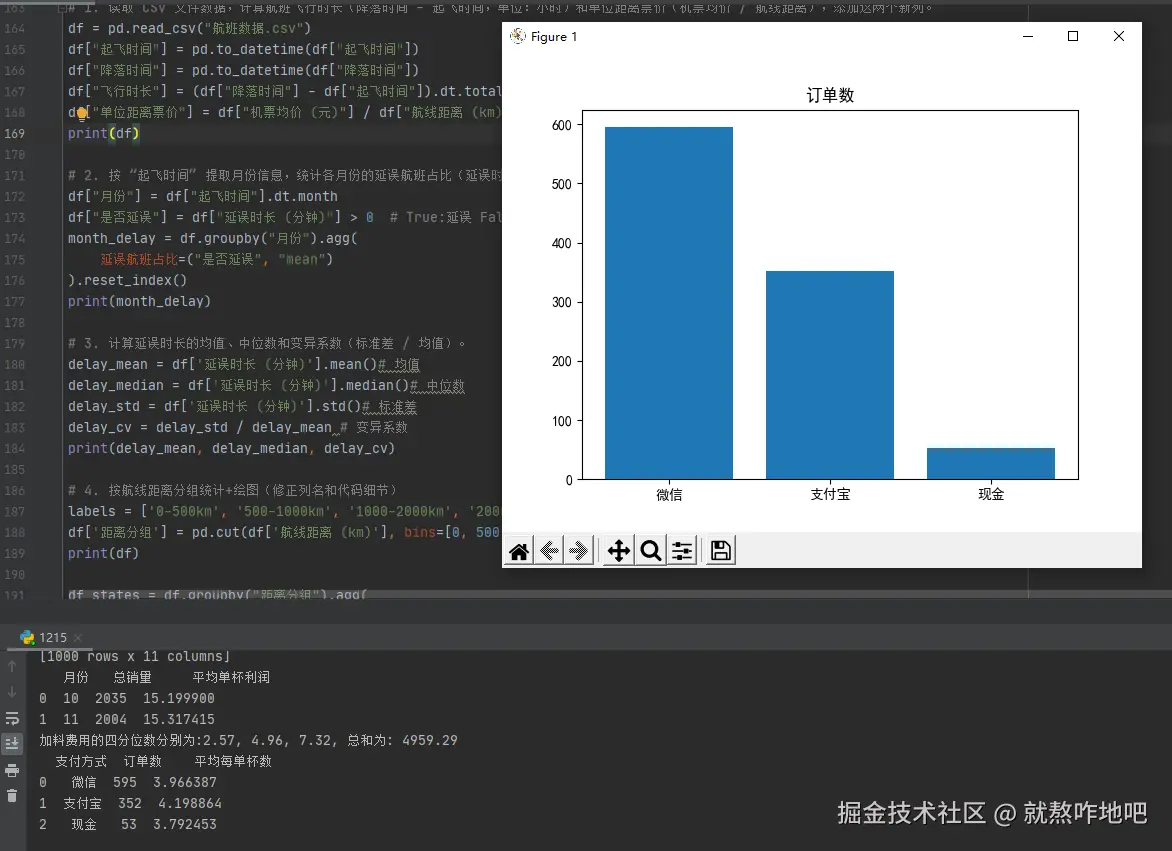
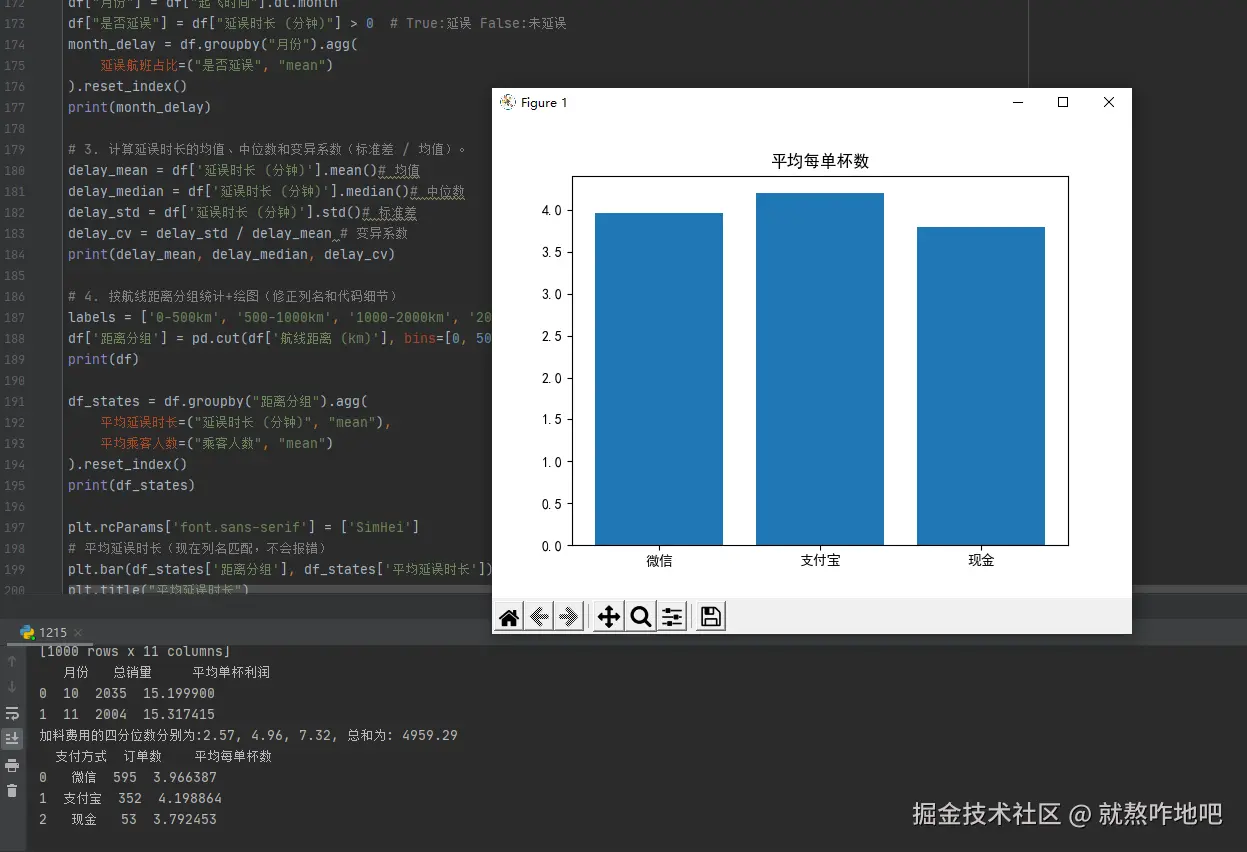
pay_states = df.groupby("支付方式").agg(
订单数=("销售单号", "count"),
平均每单杯数=("杯数", "mean")
).reset_index()
print(pay_states)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.bar(pay_states['支付方式'], pay_states['订单数'])
plt.title("订单数")
plt.show()
plt.bar(pay_states['支付方式'], pay_states['平均每单杯数'])
plt.title("平均每单杯数")
plt.show()
df_new = df[(df['饮品类型'] == '果茶') & (df['杯数'] > 3)]
df_new.to_csv("果茶批量订单.csv")
df = pd.read_csv("航班数据.csv")
df["起飞时间"] = pd.to_datetime(df["起飞时间"])
df["降落时间"] = pd.to_datetime(df["降落时间"])
df["飞行时长"] = (df["降落时间"] - df["起飞时间"]).dt.total_seconds() / 3600
df["单位距离票价"] = df["机票均价 (元)"] / df["航线距离 (km)"]
print(df)
df["月份"] = df["起飞时间"].dt.month
df["是否延误"] = df["延误时长 (分钟)"] > 0
month_delay = df.groupby("月份").agg(
延误航班占比=("是否延误", "mean")
).reset_index()
print(month_delay)
delay_mean = df['延误时长 (分钟)'].mean()
delay_median = df['延误时长 (分钟)'].median()
delay_std = df['延误时长 (分钟)'].std()
delay_cv = delay_std / delay_mean
print(delay_mean, delay_median, delay_cv)
labels = ['0-500km', '500-1000km', '1000-2000km', '2000km+']
df['距离分组'] = pd.cut(df['航线距离 (km)'], bins=[0, 500, 1000, 2000, np.inf], labels=labels)
print(df)
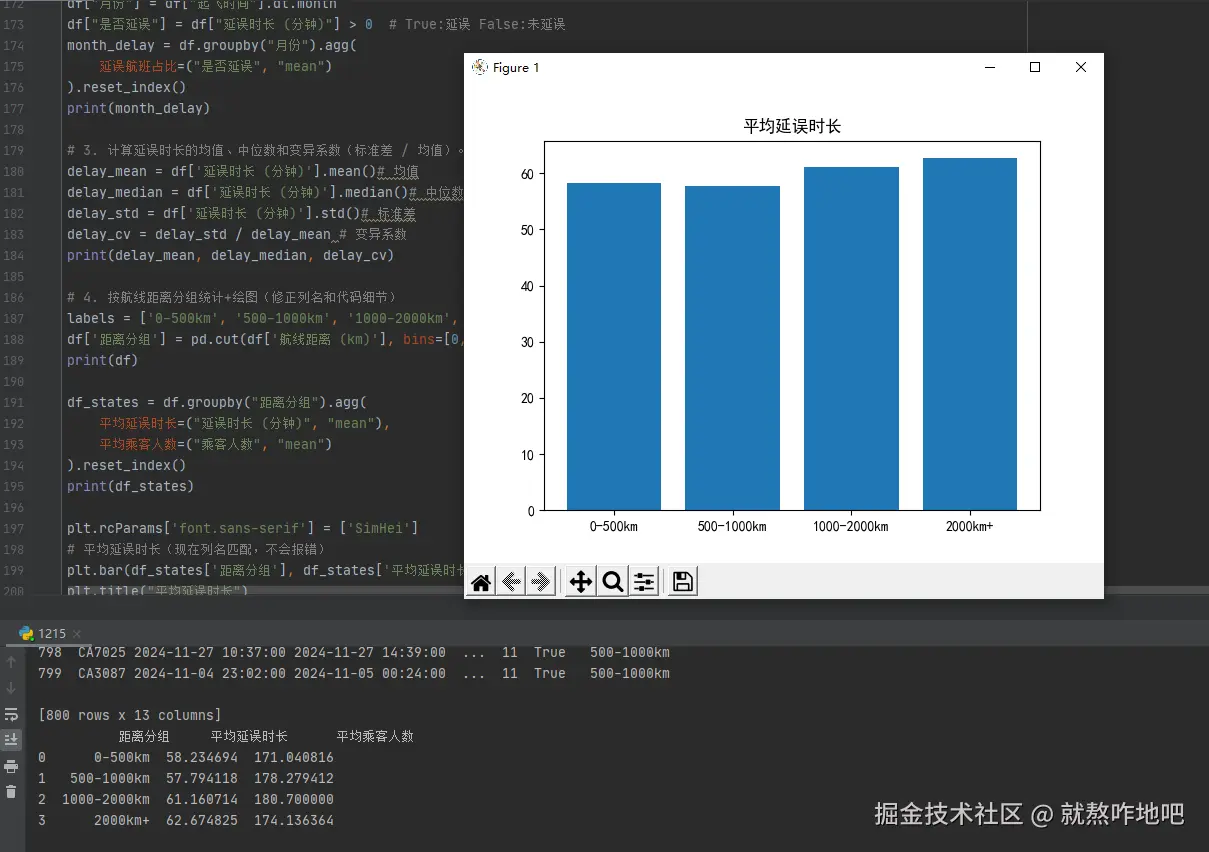
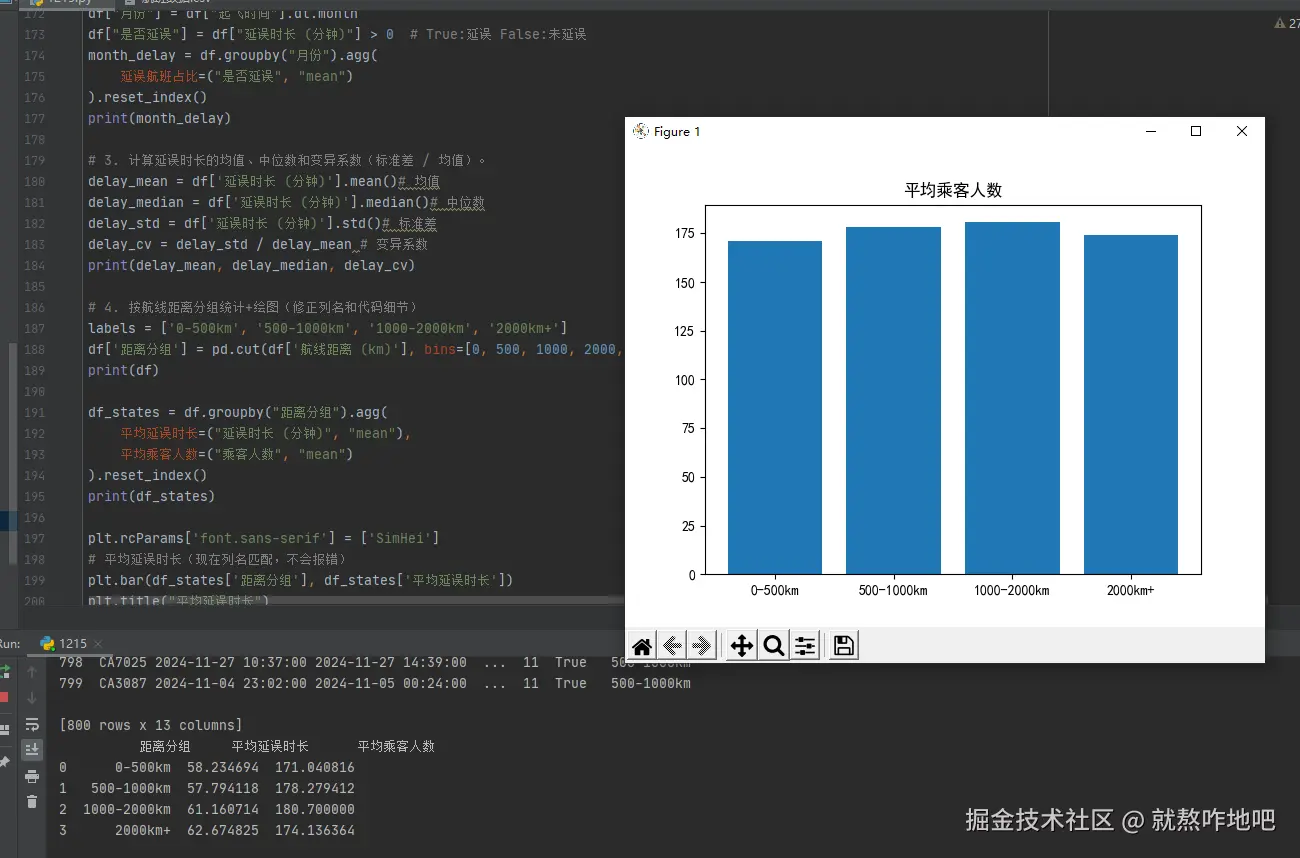
df_states = df.groupby("距离分组").agg(
平均延误时长=("延误时长 (分钟)", "mean"),
平均乘客人数=("乘客人数", "mean")
).reset_index()
print(df_states)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.bar(df_states['距离分组'], df_states['平均延误时长'])
plt.title("平均延误时长")
plt.show()
plt.bar(df_states['距离分组'], df_states['平均乘客人数'])
plt.title("平均乘客人数")
plt.show()
df_new = df[(df['延误时长 (分钟)'] >= 60) & (df['是否天气原因延误'] == '是')]
df_new.to_csv("严重延误航班.csv", index=False)