- 为什么要用RNN
- 解决传统神经网络不能理解输入先后顺序的问题,例如“好吃嘛”与“嘛好吃”表达不同的意思,那么作为网络输入时,得到的输出也应该不一样
- RNN的计算公式
- 相较于正常神经网络的 Y=f(WX+b)
- RNN的输出公式为 Yt=f(WX+WyYt−1+b)
- RNN表示图
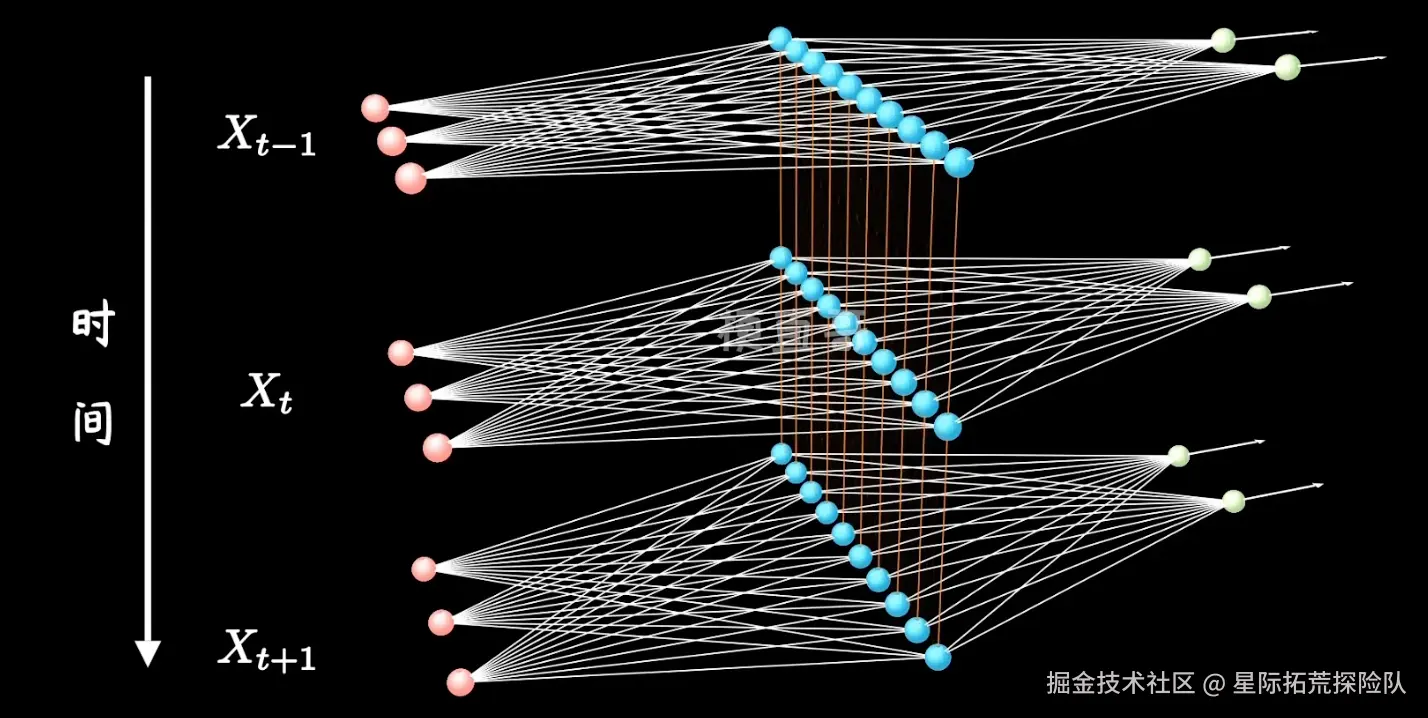 图片出自www.bilibili.com/video/BV1z5…
图片出自www.bilibili.com/video/BV1z5…
- RNN的核心思想:当前状态由 “上一状态 + 当前输入” 计算出来,事实上基于这一核心思想,RNN的公式可以表示为 ht=f(xt,ht−1)
- RNN的反向传播
- RNN的反向传播 = 所有时间步的反向传播贡献之和
- 要计算反向传播,首先要明确前向计算的公式:
- 计算 pre-activation(以x与h都是线性距离,更好解释梯度爆炸 or 消失,实际可以是更复杂的模型):at=Wihxt+Whhht−1+b
- 隐藏状态值 ht=f(at)
- 输出:y^t=Woht+bo
- 单个时间步的 loss(假定 many-to-many):Lt=ℓ(y^t,yt)
- 最终总 loss:L=∑t=1TLt
- 那么当反向传播的的时候,假如L_t是最终步
- 定义δT=∂aT∂L
- 根据链式法则得到:δT=∂hT∂L⋅f′(aT)
- 如果L_t不是最终步,那么则需要考虑后一步对前一步的导数
- ∂ht∂L=∂ht∂Lt+Whh⊤δt+1,会多出一个δt+1的项(来自于t+1时刻因为使用了ht做输入因此回传的导数)
- 由此得到最终的导数形式
- δt=(∂ht∂Lt+Whh⊤δt+1)⊙f′(at)
- 根据δt对w_x和w_h求导就可以得到t时刻的倒数,将每个时刻的导数加起来得到单次反向传播的导数
- RNN可以用来解决不同的问题,包括下图四种
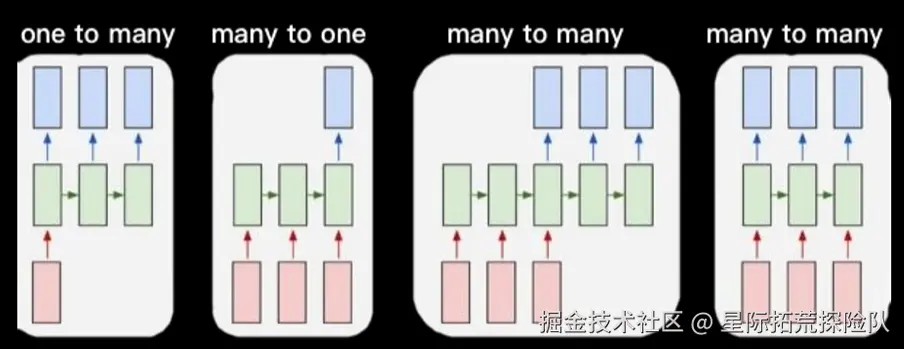
- one to many
- many to one
- 用于根据一段文字输出判断(例如文字的情绪判断)等场景
- 两种many to many,用于机器翻译,Encoder-Decoder模型,seq2seq等
- RNN的简易实现
- 可以在 Google Colab 上直接执行这段代码
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import random
def gen_arith_sample(seq_len=4, start_range=(-10, 10), diff_range=(-5, 5)):
a = random.randint(*start_range)
d = random.choice([i for i in range(diff_range[0], diff_range[1]+1) if i != 0])
seq = [a + i*d for i in range(seq_len + 1)]
x = seq[:-1]
y = seq[-1]
return x, y
class ArithDataset(Dataset):
def __init__(self, n=2000, seq_len=4):
self.data = [gen_arith_sample(seq_len=seq_len) for _ in range(n)]
self.seq_len = seq_len
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
x, y = self.data[idx]
x = torch.tensor(x, dtype=torch.float32).unsqueeze(-1)
y = torch.tensor([y], dtype=torch.float32)
return x, y
class SimpleRNN(nn.Module):
def __init__(self, input_size=1, hidden_size=32):
super().__init__()
self.rnn = nn.RNN(input_size=input_size, hidden_size=hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, h = self.rnn(x)
last = out[:, -1, :]
pred = self.fc(last)
return pred
def train():
seq_len = 4
train_ds = ArithDataset(n=2000, seq_len=seq_len)
test_ds = ArithDataset(n=200, seq_len=seq_len)
train_loader = DataLoader(train_ds, batch_size=64, shuffle=True)
test_loader = DataLoader(test_ds, batch_size=64)
model = SimpleRNN(hidden_size=32)
opt = torch.optim.Adam(model.parameters(), lr=1e-3)
loss_fn = nn.MSELoss()
for epoch in range(30):
model.train()
total = 0.0
for x, y in train_loader:
x = x
y = y
pred = model(x)
loss = loss_fn(pred, y)
opt.zero_grad()
loss.backward()
opt.step()
total += loss.item()
model.eval()
with torch.no_grad():
val_loss = 0.0
for x, y in test_loader:
pred = model(x)
val_loss += loss_fn(pred, y).item()
print(f"epoch {epoch+1:02d} | train_loss={total/len(train_loader):.4f} | val_loss={val_loss/len(test_loader):.4f}")
return model
model = train()
def demo(model, k=5, seq_len=4):
model.eval()
for _ in range(k):
x, y = gen_arith_sample(seq_len=seq_len)
xt = torch.tensor(x, dtype=torch.float32).unsqueeze(0).unsqueeze(-1)
with torch.no_grad():
pred = model(xt).item()
print(f"input={x} | target={y} | pred={pred:.2f}")
demo(model)


